

Этот парень был из тех, кто просто любит связь
Однажды в 1957 году советский инженер подал заявку на выдачу патента на устройство вызова и коммутации каналов радиотелефонной связи. По сути, это был мобильный телефон, по форме — трёхкилограммовая коробка с диском для набора номера, по содержанию — система с приёмником, преобразователем, передатчиком, коммутатором и дешифратором.

— Два, двенадцать, восемьдесят пять, ноль, шесть — это твой номер
Инженера звали Леонид Куприянович, а устройство — ЛК-1.
Принцип работы
В основе ЛК-1 лежал радиопередатчик, настроенный на работу в диапазоне коротких волн.
Принцип работы заключался в передаче сигналов от радиотелефона к автоматической телефонной станции (АТС) через автоматическую телефонную радиостанцию (АТР), которая играла роль посредника и ретранслятора. Предполагалось, что одна базовая станция (АТР) будет обеспечивать работу сразу нескольких радиотелефонов, не создавая между ними помех и распределяя сигналы по разным каналам.
Радиус действия «Радиофона» составлял 20–30 км, а само устройство могло работать без подзарядки до 30 часов. ЛК-1 поддерживал дуплексную связь, то есть мог одновременно и передавать, и принимать сигналы.
Куприянович утверждал, что для полного покрытия Москвы было достаточно установить всего десять АТР, чтобы москвичи и гости столицы могли свободно перемещаться по городу, оставаясь на связи.
Технически всё было устроено примерно так:
«Юный техник», 1958 год
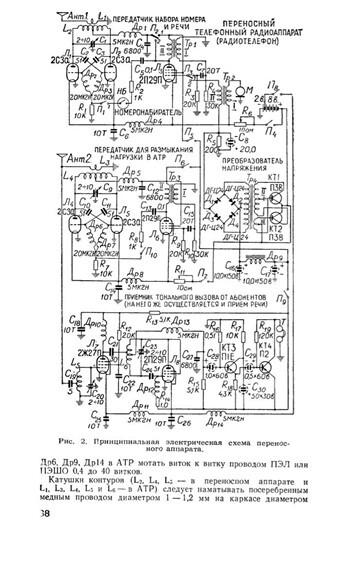
Система включала в себя многоканальный дешифрирующий тракт, где каждый канал был оснащён электронными реле и ламповыми блоками. Важным элементом была система релейной коммутации. Поляризованные реле использовались для удержания вызывного канала от начала вызова до конца разговора. Трансформатор подключался к городской сети после набора номера и обеспечивал трансляцию сигнала в радиоканал. Для обратного вызова абонента с городской сети на радиотелефон использовался импульсный формирователь сигнала, подключённый к генератору передатчика.
К 1958 году Куприянович пропатчил, заапдейтил и выкатил в продакшен ЛК-2: радиотелефон стал гораздо компактнее и весил полкило.
Существование ЛК-3 — наладонника весом в 70 граммов, который при всём этом в теории мог поддерживать связь на расстоянии до 80 км от базовой станции — вызывает некоторые сомнения и скепсис.
Каждому карману — карманный радиотелефон
Статьи о радиотелефоне стали регулярно появляться на страницах популярных журналов — от «Науки и жизни» и «За рулем» до «Юного техника» и «Техника — молодёжи». В публикациях отмечалось, что телефон Куприяновича мог бы стать важной частью повседневной жизни.

«Наука и жизнь», 1958 год
Сам Куприянович утверждал, что опытный радиолюбитель на досуге может собрать аппарат, используя компоненты, которые в целом были доступны. Как и сами схемы, они были опубликованы в том же «Юном технике».
В одной из статей Куприянович объяснял, как передавать до тысячи разговоров по одной радиоволне. Для этого использовались кодирование номера и коррелятор. Чтобы каждый радиотелефон мог подключиться к нужному абоненту, номер кодировался с помощью импульсов. Коррелятор работал на основе вокодера — устройства, которое анализирует и изменяет голосовой сигнал. Вокодер разделяет голос на частоты, сжимает каждую из них и отправляет данные. На другом конце происходит обратное: сжатый сигнал разворачивается обратно в голос.

«Юный техник», 1958 год
В 1959 году в киножурнале «Наука и техника» вышел достаточно пасторальный сюжет о Куприяновиче, где тот демонстрировал своё устройство в действии.
Ожидаемо изобретение заинтересовало не только радиолюбителей, но и общественность пошире. Вместе с тем проект не дошёл до стадии массового производства, а публикации о радиотелефоне к середине 60-х потихоньку сошли на нет.
Но почему
Одной из основных причин стало то, что в СССР приоритет был отдан другой системе связи — «Алтай». Этот проект, начатый в 1958 году группой инженеров под руководством Леонида Моргунова в Воронежском НИИ связи, имел гораздо больше государственной поддержки. Собственно, «Алтай» предназначался для использования в автомобилях и был более сложным (и дорогостоящим) решением, ориентированным на чиновников, спецслужбы и оперативные структуры.
Система работала по другому принципу. Она использовала радиопередатчики (базовые станции), которые размещали где-нибудь повыше, что позволяло создать зону покрытия для связи по всему городу. Собственно, основная сложность была не в создании портативного телефона как такового, а в необходимости разработки всей инфраструктуры связи. Например, первую базовую станцию установили в Москве на высотке на Котельнической набережной в 1963 году. Масштабно, серьёзно.
Радиотелефоны, установленные в автомобилях, могли автоматически настраиваться на свободные базовые станции, что обеспечивало надёжное и непрерывное соединение. Кроме того, система «Алтай» шифровала связь, что было крайне важно для служебных переговоров.
В общем, реализация проекта «Алтай» выглядела более жизнеспособной по сравнению с созданием национальной сети на базе радиотелефонов.
Изначально система использовала диапазон 150 МГц и могла обслуживать ограниченное количество абонентов через одну базовую станцию. В 1970-х была разработана новая версия «Алтай-3М» с дополнительными радиоканалами и улучшенной компактностью абонентских станций. К Олимпиаде 1980 года была проведена модернизация, и связь через «Алтай» активно использовалась для журналистских репортажей.
К началу 80-х количество абонентов достигло примерно 25 тысяч. Сеть просуществовала до 2011 года, когда последним городом, отключившим систему, стал Воронеж.

Вот такая штука
Что было дальше
Дальше всё достаточно туманно.
Часть проектов, в которых принимал участие Куприянович, осталась засекреченной по банальной причине: что происходит в НИИ — остаётся в НИИ.
В какой-то момент он переключился на медицинскую электронику и нейрофизиологию, в том числе написал пару книжек про циркадные ритмы и их коррекцию аппаратными методами, а ещё про то, как можно смэтчить резервы человеческой памяти с кибернетикой. Например, в своих исследованиях он рассматривал способы записи информации в подсознание через специальный «информационный сон».
По воспоминаниям дочери Куприяновича, его интересовал скорее процесс изобретения чего-то, чем выкатывание этого чего-то в продакшен. В частности, он разработал аппарат «Ритмосон», который предназначался для нормализации сна и коррекции его нарушений. Предполагалось, что ритмическая стимуляция и звуковые сигналы воздействовали на нервную систему и прочую мозговую активность, помогая пациенту расслабиться или погрузиться в сон.
Стоит сказать, что до ЛК-1 Куприянович ещё в студенческие годы сконструировал свою первую портативную рацию весом около двух килограммов. В дальнейшем он продолжил работу над уменьшением её габаритов и через несколько итераций за пару лет дошёл до наручного формата.
Его разработки хотя и не получили широкого распространения, однако предвосхитили многие аспекты современных мобильных сетей.
Официальный первый звонок по мобильному телефону, как мы помним, раздался в 1973-м, когда Мартин Купер потроллил конкурентов из Bell Laboratories, но неофициальный перезвон радиотелефона ЛК-1 тоже занял своё место в истории.
Источник: блог Газпромбанка










