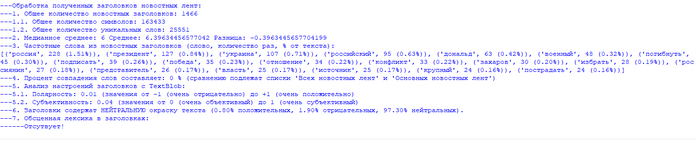
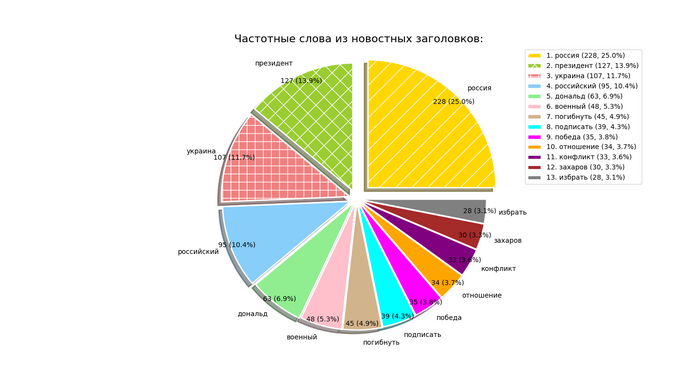
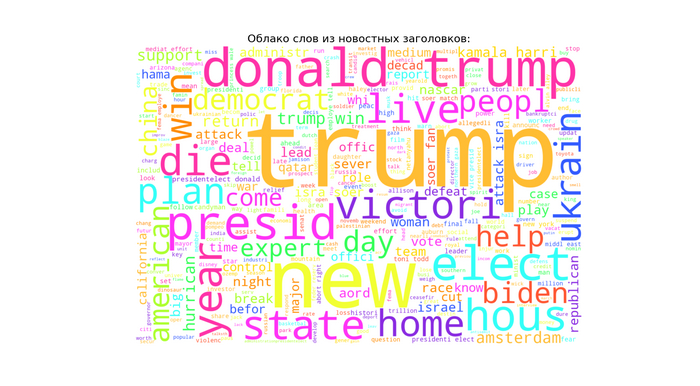
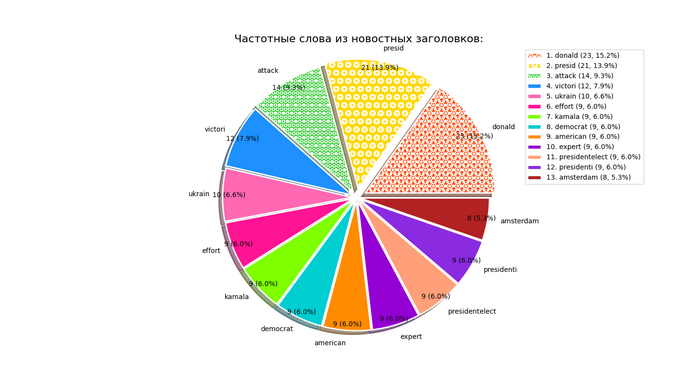
Помощники для ChatGPT и других LLM, а так же для ИИ-агентов
Сегодня необычные сервисы, а помощники для LLM и ИИ-агентов, чтобы они анализировали ваши файлы без галлюцинаций и ошибок. Обычные ИИ плохо справляются с PDF и картиками: путают колонки, не понимают таблицы и заголовки. Следующие инструменты читают документы как человек — учитывают структуру, формат, сноски, даже логику. Эти же инструменты превращают документ в качественно распознанный и разбитый по структуре текст, который уже можно загрузить в Большие Языковые модели (LLM) для дальнейшего взаимодействия без галлюцинаций. Этакие парсеры документов.
Проще, зачем они нужны? Для создания:
• систем поиска по внутренним документам (вопрос-ответ по внутренним документам)
• интеллектуального анализа юридических, медицинских, технических файлов
• создания базы знаний из PDF/HTML/DOCX, изображений и тд
Вот два таких сервиса:
1) LlamaParse
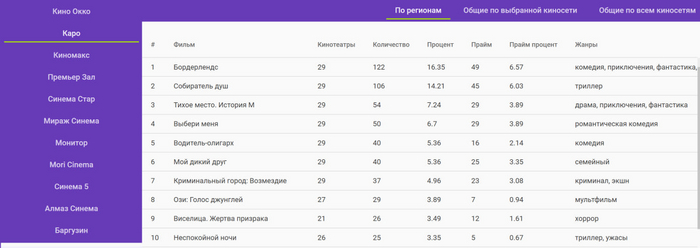
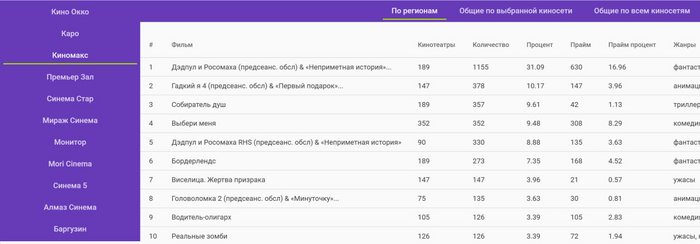
LlamaParse — умный парсер документов и файлов от LlamaIndex. Очень круто извлекает сложные таблицы. Можно интегрировать через API в приложения. Бесплатно можно обработать до 1 000 страниц в день.
LlamaParse поддерживает:
• Документы: PDF, DOC, DOCX, RTF, TXT, EPUB, XML, HTML, Pages, Keynote и др.
• Презентации: PPT, PPTX, ODP
• Таблицы: XLS, XLSX, CSV, ODS, TSV
• Изображения: JPEG, PNG, GIF, BMP, SVG, TIFF, WebP
• Аудио: MP3, MP4, WAV, M4A и др. (до 20 МБ)
Полный список доступен в официальной документации Supported Document Types
Например: Вы загружаете инструкцию по продукту, договор или научную статью → LlamaParse анализирует структуру и разбивает по логике → вы используете это в GPT-боте, который теперь может грамотно отвечать на вопросы по документу.
Больше проверенной информации и пользы в моем телеграм канале.
2) Contextual
Contextual - тоже самое, вы загружаете документ со сложными таблицами, рисунками и диаграммами, сервис так же преобразовывает это в текстовый файл с метаданными, понятный для любой LLM. Бесплатно можно обработать до 500 страниц.
Contextual AI поддерживает:
• Документы: PDF, DOC, DOCX, PPT, PPTX, HTML-файлы
Можно использовать документы Microsoft Office напрямую в системах Contextual AI, без необходимости предварительно конвертировать их в PDF.
Подпишитесь на НейроProfit и узнайте, как можно использовать нейросети для бизнеса, учебы и работы, не теряя свое время.
Хотите больше полезных сервисов для работы, учебы и бизнеса, видеоуроков, обратную связь и сильное окружение - Добро пожаловать в: