В этом посте перечислю годные сервисы, которые с большой вероятностью распознают сгенерированный ИИ контент. Я разделила их на детекторы визуального и текстового контента
1.Детекторы текста
Thecheckerai — добротный определитель текстового контента, который создал ИИ
AiOrNot - С вероятностью около 90% сервис определит, сделала ли картинку нейросеть или нет.
Sightengine - мой любимчик, не только определит, сделано ли изображение в ИИ, но и определит в какой - SD, Flux, Midjourney и т.д. Есть определение дипфейка лица. Без регистрации дает один раз определить, далее после регистрации можно выбрать и другие модели детекторов - детские изображения, излишне жестокие изображения, алкоголь и наркотики, обнаженка и тд - занятный сервис.
Hivemoderation - этот думает подольше, тоже определяет, в какой модели сгенерировали изображение. Помимо детектора ИИ изображений, там есть и другие любопытные продукты для модерации контента, в том числе видео и аудио, фичи для модераторов типа обнаружения скама и тд.
Кстати, как вам видео к посту? Забавно, но теперь крадут посты с моим лицом, не подозревая об этом 😃 Вот в чем еще прелесть нейрофотосессий и видео со своим лицом для креаторов, а не просто девушек “клеить” (опыт моего приятеля здесь описывала) 🤭
Вкратце, если правильно все сделаете, то даже знакомые ваши фото не отличат) мой друг активно клеит барышень на "дай винчик" с фотками с Куршавеля, монако и Багамских островов. Моральную сторону вопроса я затрагивать не буду, это не моего ума дело, я изначально этот инструмент рассматриваю для бизнеса, чтобы не тратить время самой на фотосеты, а по текстовой подсказке получить фото с собой, фото для поста, обложку для ютуб, видео в конце-концов из этой фото сделать. Нормальный результат не отличишь от настоящих фото - там и работа с кожей, и с настройками) Кто хочет этому качественно научиться, добро пожаловать ко мне на обучение:
А если вы хотите просто попробовать, без лишних проблем в виде оплаты иностранными картами и иже с ними, то в боте Syntx -- это мини приложение в телеграм, есть все популярные модели в единой подписке, и их можно оплатить русской картой. Там же я показала процесс создания Нейрофотосессии со своим лицом- кликайте, там обучающее видео бесплатно, мне не жалко этим поделиться)
Если же вы уже умеете, и определились с площадкой, но у вас нет иностранной карты для оплаты этих сервисов - тут на видео показала Как оплачивать иностранные сервисы
С развитием технологий все чаще возникает вопрос: можно ли определить, что текст был создан нейросетью? Особенно остро этот вопрос стоит в образовательной сфере, где студенты могут использовать ИИ для написания эссе, курсовых и даже дипломных работ.
Современные системы проверки на плагиат постепенно адаптируются к новой реальности и начинают уметь распознавать тексты, созданные с помощью моделей вроде GPT. Антиплагиат существует не первый год и даже не первое десятилетие. Вообще, это программное обеспечение, предназначенное для выявления заимствований в текстах. Оно сравнивает поданный документ с базами данных интернет-ресурсов, научных публикаций, учебных работ и других источников. Однако современный вызов заключается в том, что текст может быть не списан, а сгенерирован ИИ, и тогда задача становится сложнее.
Почему традиционный антиплагиат не всегда видит GPT?
Стандартные программы (например, Антиплагиат ВУЗ, Turnitin, Advego Plagiatus и другие) ищут точные или близкие совпадения в уже существующих текстах. А текст, написанный с помощью GPT:
уникален — он не копирует конкретную статью или источник;
генерируется "на лету" — не существует заранее загруженного оригинала;
имеет структуру, отличную от типичного студенческого текста.
Именно поэтому такие работы могут пройти стандартную проверку как полностью оригинальные, хотя были созданы без участия человека.
История создания антиплагиатных систем
Первые попытки автоматизировать проверку оригинальности текстов начались ещё в конце 1970-х годов, когда университеты начали сталкиваться с проблемой списывания студенческих работ. Однако первые полноценные программы появились в середине 1990-х годов, когда интернет начал активно внедряться в повседневную жизнь. Одним из первых коммерческих решений стала система Turnitin , запущенная в 1997 году в США. Она позволяла преподавателям загружать студенческие работы и сравнивать их с базой данных уже существующих публикаций, сайтов и ранее сданных работ. Система быстро получила распространение в вузах благодаря своей простоте и эффективности.
В России развитие антиплагиатных программ началось чуть позже. Первые отечественные системы появились в начале 2000-х годов. Одной из самых известных стала система Антиплагиат ВУЗ , разработанная компанией «Антиплагиат» (ныне — группа компаний АО «Эксперт», https://www.antiplagiat.ru ). Эта система была внедрена во многих российских университетах и стала стандартом для проверки выпускных квалификационных работ. Основная задача антиплагиатной системы — выявить совпадения между анализируемым текстом и другими источниками. Современные системы, такие как Turnitin, Antiplagiat, Grammarly Plagiarism Checker и другие, используют сложные алгоритмы машинного обучения, чтобы не просто находить совпадения, но и давать оценку оригинальности текста.
Можно ли проверить, делал математические расчёты человек или искусственный интеллект?
На первый взгляд, математика — это формальная система, и неважно, кто её использует: человек или компьютер. Однако при анализе решения можно заметить некоторые характерные особенности: неидеальный порядок действий, ошибки в вычислениях - пропущенный шаг, забытая скобка, а также субъективность объяснений и долгая запись решения. ИИ работает как судент-отличник: нейросети редко ошибаются в вычислениях, если запрос понятен. Хотя большинство антиплагиатных программ (например, Антиплагиат ВУЗ, Turnitin) изначально были созданы для поиска заимствований, они не справляются с задачей обнаружения ИИ в математических работах. Новые технологии уже начинают внедрять специальные модули, ориентированные именно на эту задачу, но, по мнению специалистов в области образования и искусственного интеллекта, точно определить авторство математического текста пока невозможно.
Перспективы развития антиплагиата и обнаружения ИИ
Одной из ключевых тенденций в ближайшие годы станет глубокая интеграция методов машинного обучения в системы проверки оригинальности . Современные алгоритмы уже умеют не просто сравнивать текст с имеющимися источниками, но и анализировать его внутреннюю структуру — частоту словоупотребления, синтаксические особенности, логическую связность предложений и даже стиль написания. Такие подходы позволяют выявлять характерные черты текстов, созданных нейросетями, даже если они уникальны и не имеют прямых совпадений в интернете или базах данных. Один из эффективных методов обхода антиплагиата — переписывание текста своими словами. Даже если исходный материал создан нейросетью, его можно переформулировать, изменить структуру предложений и добавить личные комментарии. Это помогает снизить уровень формального сходства и приблизить текст к стилю человека.
Ещё один способ — многоэтапная обработка текста: сначала генерация через одну модель (например, Gemini), затем переработка через другую (например, YandexGPT). Это создаёт эффект "человеческой мысли", снижая вероятность обнаружения ИИ. Также полезно вносить ошибки и повторы , характерные для человеческого письма. Небольшие неточности, дополнительные пояснения и отклонения в структуре делают текст менее "идеальным" и ближе к реальному авторству.
Ещё одной важной перспективой является развитие многоуровневого анализа , при котором система не только определяет наличие заимствований, но и даёт оценку вероятности использования ИИ, а также уровня человеческого участия в подготовке текста. Например, можно будет увидеть, какие части работы были написаны самостоятельно, а какие, скорее всего, были сгенерированы нейросетью. Это даст преподавателям возможность более точно понимать, как именно студент работал над заданием, и поможет сохранить баланс между использованием технологий и развитием навыков самостоятельного мышления. Готов ли кто-то сейчас обойтись без возможностей ИИ, которые, буквально, доступны в каждом телефоне?
Скрытые метки ИИ?
В прошлом месяце специалисты платформы Rumi сообщили, что некоторые версии ChatGPT (o4-mini-high, o3) добавляют в генерируемый текст неразрывные пробелы (U+202F) — символы, невидимые в обычных редакторах, но обнаруживаемые в кодовых редакторах, таких как VS Code. Эти символы могли бы использоваться как скрытая "подпись" ИИ , однако представители OpenAI опровергли идею намеренного внедрения водяных знаков. По их словам, такие особенности возникли случайно — как побочный эффект обучения модели с подкреплением. Ранее компания рассматривала возможность добавления видимых или невидимых водяных знаков в тексты от ИИ , чтобы помочь преподавателям выявлять работы, написанные с помощью нейросети. Однако от этой идеи отказались из-за этических и технических сложностей. Тем не менее, исследователи утверждают: даже без явных меток современные системы могут отличить текст, созданный GPT, от человеческого , благодаря анализу стиля, логики и вероятностной структуры предложений.
Если OpenAI действительно будет внедрять такие метки, это может быть сделано:
для контроля использования ИИ в образовании;
для защиты авторских прав и прозрачности;
для соблюдения законов о генерации контента.
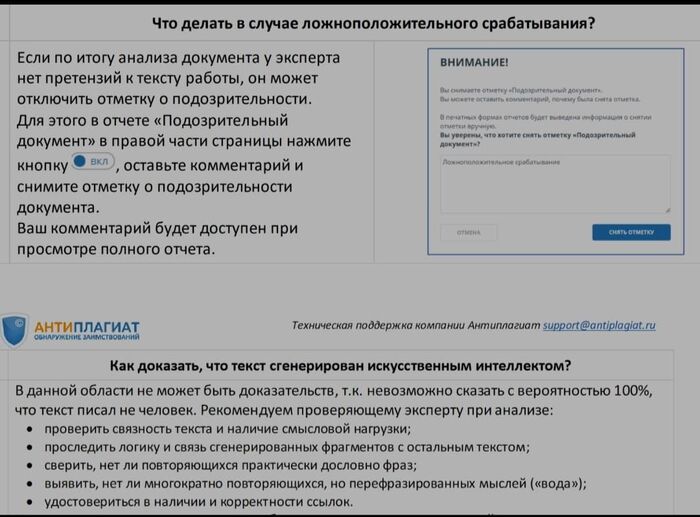
Если студент просто копирует текст в документ, преподаватель не увидит ничего необычного. А вот при более детальном анализе с помощью специальных программ можно определить, что текст был сгенерирован ИИ. Однако эксперты отмечают: скрытие таких меток простыми средствами — вопрос времени . Достаточно написать небольшую программу, которая удалит все U+202F из текста, и он станет "неотличимым".
Использование ИИ этично?
Вопрос не только в том, можно ли обнаружить ИИ , но и в том, следует ли это делать вообще. Некоторые педагоги считают, что ИИ должен стать частью образовательного процесса , а не средством обмана. Если студент умеет правильно задавать вопросы и интерпретировать ответы, это тоже навык, который заслуживает оценки. Но если студент пишет курсовую работу с помощью ИИ, можно ли считать её своей? Если художник создаёт картину через нейросеть, чьё это произведение — его или алгоритма? В конечном итоге, развитие антиплагиатных технологий и систем обнаружения ИИ направлено не на запрет прогресса, а на то, чтобы сделать его частью честной и контролируемой системы образования и коммуникации. Технологии продолжают развиваться, и уже сегодня можно говорить о том, что мы стоим на пороге нового этапа в области проверки подлинности текстов — этапа, где важен не только вопрос «откуда взят текст» , но и «кто его написал».
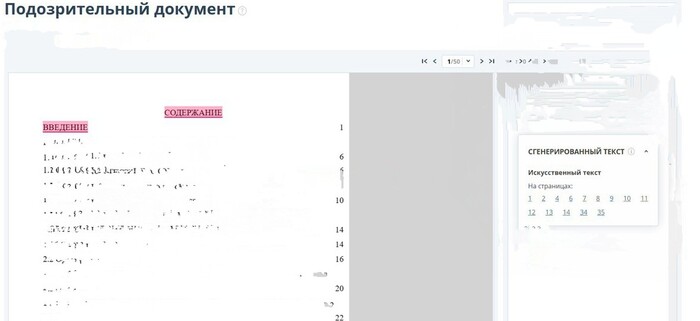
Доброго времени суток, с этого года Антиплагиат.ру внедрил в свою проверку на оригинальность поиск Искусственного интеллекта, да так хорошо внедрил, что Искусственный интеллект находит даже там, где его априори не может быть... Но зато студентов не допускают к защите и просят переписывать всю работу заново, где естественно был найден Искусственный интеллект. Вопрос к Антиплагиату.ру и его создателям. Вы ребята там конечно умные, но за косяки кто должен страдать? Студенты?))) Вот один из примеров, где антиплагиат нашел ИИ в словах Содержание и Введение))) Да да... Не удивляйтесь...
Да конечно студенты и тот кто занимается написанием дипломных работ, могут использовать ИИ. Мы живём в 2025 году... Сейчас даже переводчики не нужны, можно общаться с любым человеком через сервисы ИИ на практически любых языках мира... Но преподаватели Вузов бракуют работы... А был ли ИИ Вы даже сами не знаете... Зато Ваш ответ очень крутой, когда делаешь запрос Вам же, почему в тексте, который напечатан находит ИИ? Ответ сервиса Антиплагиат.ру:
В общем к чему я... Плохой Вы студент или хороший студент... Если хочется переписывать честно напечатанную работу по 20 раз... Пожалуйста... Печатать текст умеют немногие компании. И если заказываете работу обязательно выбирайте исполнителей с гарантией переделки до сдачи работы. А Антиплагиат.ру успехов... Потому что мало того, что образование стоит не малых денег, ещё и тут непонятки конкретные... P.S. Студент ты предупрежден, значит вооружен!!!))) По бесплатным консультациям по Студенческим работам прошу в мой ТГ канал: https://t.me/studpomogi
Есть случаи похуже чем Консультант+ и Литрес. Когда в вакууме, где должно быть государство, шустро появляются дельцы, которых оттуда потом не выкинуть под предлогом не изобретать же велосипед заново . Почти любой, кто с вузами связан, знает двух таких монструозных паразитов, создавших "государство в государстве" - Antilplagiat.ru и РИНЦ (elibrary.ru). Если найти закон или сказку Пушкина действительно можно где-то еще легально получить бесплатно, то эти две структуры фактически управомочены принимать обязательные решения и оказывать платные услуги, от которых нельзя отказаться заинтересованным лицам. Даже курсовая студента должна сопровождаться справкой из антиплагиата, расходы гос. вузов на оплату этой системы невероятно огромны и все растет что, такими темпами, скоро заметно превысит весь совокупный ущерб от нарушения авторских прав и недобросовестно пищущих письменные работы студентов.
C научными статьями все еще интереснее, РИНЦ, на первый взгляд лишь индекс цитирования. Однако по наличию статьи в нем определяется статус практически всех русскоязычных статей, тем более что последние годы с попаданием в иностранные индексы у наших журналов появились проблемы. И журналы, в том числе государством создаваемые и финансируемые (коих большинство), платят чтобы их в этом РИНЦе индексировали. В том числе, журналы из перечня ВАК (публикации в которых дают право защищать диссертации). При этом, за те огромные деньги сервис компания предоставляет архиужасный, в чем может убедиться любой, кто зайдет на elibrary.ru. Сайт, технологически почти не менялся c 2003 (!) года и сохраняет до сих пор характерный для того времени дизайн. Заявленную функцию OpenAccess (открытого доступа к статьям) сайт выполняет едва ли, потому искать на нем что либо то еще мучение, а для скачивания чего-либо, в старых добрых традициях, требуется регистрация, хорошо хоть бесплатная. О работе с издателями научной литературы и периодики с этой системой я даже говорить не буду, потому что не осведомлен, а лишь наслышан. Более того, поскольку ООО "НЭБ" владеющая РИНЦ (elibrary.ru) - контора частная, то их цель извлечение прибыли, а за хорошие деньги они индексирует в своем составе она кучу платных откровенно мусорных изданий, которые публикуют ненаучный, а часто и антинаучный бред чисто ради отчетности о количестве публикаций в РИНЦ, что вредно не только для науки в целом, но и полезность сайта снижает в разы.
Фактически, есть способы проверить на плагиат и без использования системы. Но в требованиях для ВУЗов нужны справки именно оттуда. Также можно открыть в России научный журнал или издать сборник трудов конференции, которого не будет на elibrary. Но учтены такие научные труды не будут нигде.
Не думаю, что сильно преувеличу, если скажу что уже годовые расходы государство на использование таких систем сопоставимы с расходами на создание аналогичных систем и их полноценного функционирования в не меньшем объеме.
Уникализация текста ради SEO убивает все в этом тексте. Мало того, что она искажает стиль, уничтожает терминологию, подтасовывает факты и извращает смысл текста, так она еще и лишает смысла то самое SEO, ради которого вы все это делаете, т. к. гугл жестко наказывает страницы, написанные не «для людей», а для поисковых роботов. Понижает их в выдаче, а может и вообще исключить из индекса. «За что боролись, на то и напоролись».
Кстати сайт с такими текстами называется (простите за мой французский) «говносайтом», и это не ругательство, это технический термин.
В описаниях большинства заданий на биржах копирайтинга указывают, что уникальность должна быть 100 % по text-ru (или etxt или advego...). И откуда вы это только берете! С заказчиками на этих биржах все понятно, там этот инструмент уже встроен. Но даже прямые заказчики, даже далекие от SEO, всегда спрашивают меня, какой процент уникальности я могу им дать.
И ладно бы еще только уникальность. Но нет же, в задание включен еще целый набор других требований, которые прямо противоречат этому условию.
Ну, во-первых, здесь так и хочется сказать: «Ты че орешь-то, уважаемый?» Ведь все эти восклицательные знаки, особенно тройные — это не что иное, как крик во всю глотку (!!!)
А во-вторых, «умение и знание» правил пунктуации, по ходу, необязательно.
Ну да ладно. Я сейчас о другом хотел сказать.
Заказчик, неужели вы не видите, что это задание противоречит само себе? Выполнить его невозможно. По крайней мере, выполнить его «для людей».
Я не прав? Считаете, что это возможно? Докажите!
Выполните задание:
Напишите, чему равно 2 + 2, с уникальностью 100 %, без воды и, само собой, только правду, никакого вымысла.
Да, согласен, задание абсурдное... Но не более абсурдное, чем ваше. Отличается только количеством знаков.
Попробуем выполнить? Не бойтесь. Я вам помогу.
Поехали!
Попытка № 1
«2 + 2 = 4».
Воды нет? Нет.
Факт правдивый? Да.
Уникальность? Ноль. С заданием не справились.
Попытка № 2
«Два плюс два равно четыре».
Воды нет? Нет.
Факт? Факт.
Уникальность? Ноль. Мы снова не справились с заданием.
Попытка № 3
Попробуем схитрить:
«2 + два = 4»
или
«два + 2 = четыре»
или даже
«два + two равно cuatro»
и так далее...
С заданием не справились, т. к. здесь несогласованность, неконсистентность или, как там ее, непоследовательность. Кстати, уникальность здесь тоже будет явно не 100 %.
Попытка № 4
Заменим русские «о», «а», «е» английскими, французскими или немецкими «о», «а», «е». Но это не даст пользы. Только нанесет непоправимый вред. Ключевые фразы перестанут считываться, т. к. перестанут быть таковыми, а вот гугл это обязательно заметит и уберет вашу страницу из выдачи за попытку нае... обмануть систему.
Попытка № 5
Добавим воды. Вернее, не воды, а вод — сточных:
«Fucking два плюс fucking two рав-fucking-но че-fucking-тыре».
Ну, вот! Другое дело! Можем же, когда захотим! А если и это УГ не пройдет тест на уникальность, то добавим к нему:
«Всем известно и ни для кого не секрет, что в наши дни, как, впрочем, и во все времена, сумма (и даже — вы не поверите! — произведение! о, да! про-из-ве-де-ни-е!) этих двух прекрасных, восхитительных и, не побоюсь этого слова, великолепных чисел, которые, как вы, наверняка, заметили, являются одним и тем же числом, которое, кстати, в нумерологии означает...»
Попытка № 6
Можно уникализировать и без воды. Вот так, например:
«2 + 2 = 3,9997856397»,
то есть за счет наглого, бессовестного вранья, буквально плюнув в лицо читателю. И еще не факт, что это вранье пройдет тест на уникальность.
Вы можете себе позволить так поступить с читателем?
Как работают системы антиплагиата
Если на предыдущем примере вы все еще не поняли, как это работает, постараюсь объяснить на другом примере, на этот раз более реалистичном.
Допустим, вы пишете статью по физике. В задании указано, что вам обязательно нужно вставить в текст 2-й закон Ньютона, т. к. это основная тема статьи, но при этом обеспечить уникальность текста не менее 100 % с шинглом 3.
Далеко ходить не будем, возьмем из Википедии:
«В инерциальных системах отсчета ускорение, приобретаемое материальной точкой, прямо пропорционально вызывающей его силе, совпадает с ней по направлению и обратно пропорционально массе материальной точки».
Если вы проверяете уникальность с шинглом 3, то программа проверки разобьет текст на все возможные фразы из трех слов, которые там могут быть («шинглы» с шагом 3) и проверит, встречаются ли точные вхождения этих фраз в интернете. И конечно, найдет их все без исключения. И придерется к неуникальности каждой из них:
«инерциальных системах отсчета» — плагиат!
«системах отсчета ускорение» — плагиат!
«отсчета ускорение приобретаемое» — плагиат!
и так далее по тексту.
В итоге программа выделит весь ваш 2-й закон Ньютона (все 180 знаков без пробелов) как плагиат.
Если, допустим, объем всей статьи у вас равен 1800 знаков, то одним лишь этим законом вы убили 10 % уникальности.
А не вставить его вы не можете. У вас в задании это прописано.
Попытаетесь подобрать синонимы (сделать рерайт)? Ну-ну. Там каждое слово — научный термин. Какие синонимы вы собираетесь подобрать к физическим величинам: «сила», «масса», «ускорение»? Замените каждый термин соответствующим определением? А может, еще проще сделаете?.. Вместо «силы» возьмете «мощность», вместо «массы» — «вес», а вместо «ускорения» — «скорость»?
Даже гугл не прощает такого беспредела. А уж о читателях вообще молчу.
А теперь, когда вы узнали, как работает метод шинглов, вы не можете не понимать самого интересного:
Требуя уникальности 100 %, вы тем самым требуете, чтобы у вас в статье не было:
ни одной ключевой фразы (хотя сами даете их целый список);
ни одного научного термина;
ни одной формулы;
ни одного географического названия;
ни одного ФИО;
ни одного фразеологического оборота;
ни одного известного факта;
да чего уж там... ни одной понятной фразы!.. т. к. любая понятная фраза уже записана тысячи раз, а значит, согласно вашему text-ru, является плагиатом.
Кстати, мы все разговариваем на сплошном плагиате. Не согласны? Тогда найдите хотя бы одну уникальную фразу в вашей собственной повседневной речи. Проверьте ее своими любимыми сервисами.
***
Итак, вам нужна статья, написанная фразами, которых никто никогда не использовал в письменной речи. То есть написанная на несуществующем языке.
Ну и на кой хрен вам такая статья?
---
Не пишите для поисковых ботов. Они не поймут и не оценят. Закажите лучше статью для людей -- у автора:
Об авторе:
Алексей Афонин
Переводчик английского, копирайтер, редактор, трейдер, криптоэнтузиаст, геолог-геофизик.
Держите студенты лайфхак как обойти антиплагиат. Берете с помощью генератора слов в интернете генерируете текст на 5-50 тыс. символов. Задаёте ему белый цвет, размер 1 пт. или меньше, отступы на минимум. И запихиваете его в текст. Можно скрыть картинкой. Все, вы великолепны. Рандомный текст полностью оригинален. И в процентном соотношении оригинальность будет повышена!
Retext – нейросеть, которая помогает повышать уникальность текстов.
Нейросеть анализирует исходный материал, и на выходе предложит новые способы изложения мыслей, варианты формулировок и синонимы, благодаря которым ваш текст станет по-настоящему оригинальным. Иными словами, перефразирует текст или напишет новый обойдя проверку на плагиат.
Что может инструмент:
- Генерация уникального текста;
- Редактирование объема текста, его расширение или сжатие;
- SEO-оптимизация текста.
Для получения уникального текста необходимо добавить исходный материал в окно платформы и дождаться завершения обработки.
Retext особенно придется по душе тем, кто по роду своей деятельности постоянно работает с текстами: копирайтерам, журналистам, студентам, блогерам, предпринимателям, а также авторам произведений.
Если вам интересны новые технологии, полезные сервисы и новости будущего, добро пожаловать в ИИшница 🍳 - пища для ума в мире высоких технологий
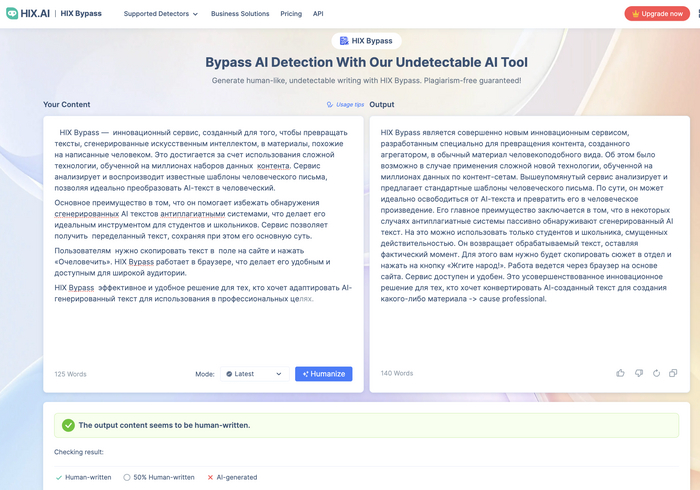
Сколько хайпа вокруг нейросети HIX Bypass, которая перефразирует сгенерированный нейросетью текст так, чтобы система антиплагиата не обнаружила признаков ИИ до 99%
А какие громкие заголовки - “Обходите обнаружение искусственного интеллекта”, “очеловечит текст ии” - я представляю, как обрадовались те, кто на Дзене пишет. Но радость их будет не полной, при том, что сервис платный, а для теста можно вставить кусок текста со 125 словами.
В чем же подвох?
Подвох номер 1
Разработчики утверждают, что сервис преобразует написанный ИИ контент в человекоподобный текст, гарантируя, что он пройдет через различные детекторы ИИ, такие как GPTZero, Turnitin и другие, не будучи отмеченным как созданный ИИ. По факту, если вам нужен русский текст, то русские AI - детектеры он не пройдет:
Такой текст даже человеческую критику не пройдет, бедные мои глаза
Подвох номер 2
Сервис заявлен как подходящий для различных целей, включая бизнес, академические и SEO-цели, и поддерживает несколько языков. Ну да, русский он поддерживает, однако, даже если в настройках выставить локацию Россия, выдаст он белиберду.
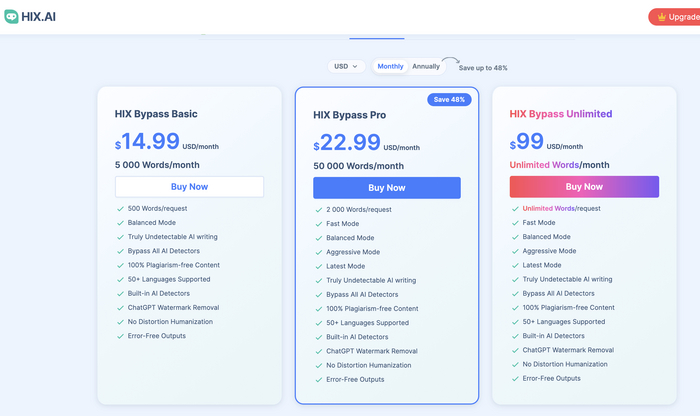
Вот слева текст даже почеловечней, хотя он от ChatGPT, а справа - просто жесть. Так что не ведитесь. Даже старый-добрый промпт для ChatGPT работает лучше). А цены у них, в прочем, сами посмотрите:
Видимо сервис все же для английских текстов, с русскими работать бесполезно
Хотите узнавать первыми о полезных сервисах с искусственным интеллектом для работы, учебы и облегчения жизни? Подпишитесь на мой телеграм канал НейроProfit, там я рассказываю, как можно использовать нейросети для бизнеса.