
0 просмотренных постов скрыто


В итальянских музеях начали следить за реакцией посетителей, чтобы оценить привлекательность экспонатов
Система собирает данные о количестве посетителей и их поведении перед картинами, скульптурами и артефактами.

Камеры с искусственным интеллектом проходят испытания в музее Болоньи / Фото с сайта The Telegraph
В музеях Болоньи внедрили систему ShareArt — рядом с экспонатами разместили камеры, отслеживающие посетителей. Система вычисляет, как долго и как близко люди рассматривают картины, скульптуры и артефакты, а затем выдаёт «оценку привлекательности». Модель классифицирует эмоции по пяти выражениям лица — счастливому, грустному, нейтральному, удивленному или сердитому, а также определяет пол, возраст и движение глаз посетителей.
Таким образом кураторы выставок хотят понять, какие именно экспонаты привлекают больше посетителей и на основе этого изменить планировки. По задумке руководства музеев, это позволит увеличить число туристов и возместить хотя бы часть из 190 миллионов евро выручки, которые музеи потеряли из-за пандемии.
Систему разработала команда из правительственного агентства ENEA, которое занимается развитием новых технологий в Италии. ShareArt использует камеры рядом с экспонатами, а затем объединяет и сравнивает, как люди проводят время рядом с разными картинами, скульптурами и артефактами.
Изначальный вариант системы разработали ещё в 2016 году, однако первые публичные тесты начали только в июле 2021 года после открытия музеев и галерей. Пока в музеях установили 14 устройств ShareArt: данные транслируют в специальный график, который отражает, на чём именно концентрируется внимание людей.
Разработчики уже получили первые результаты. К примеру, выяснилось, что в случае с картиной Трофима Биго «Святой Себастьян, помогающий Святой Ирэн», посетители фокусировались не на центре композиции, а на правой части лица Себастьяна. По мнению исследователей, причиной стала игра света и тени.

Картина Трофима Биго / Фото с сайта Saatchiart
ShareArt также отслеживает, как много посетителей останавливаются перед картинами и как долго на них смотрят. Оказалось, что очень немногие работы способны удерживать людей больше чем на 15 секунд. В среднем у экспоната проводят от 4 до 5 секунд.
Некоторые выводы исследователей оказались неожиданными: например, на диптихе 14-го века художника Витале дельи Экви внимание всегда привлекала только правая половина произведения. Левую часть большинство посетителей просто пропускали.

Диптих Витале дельи Экви / Фото Istituzione Bologna Musei
Пока в музее не поняли, в чём причина такого поведения посетителей, но считают, что чем больше данных они смогут получить, тем лучше смогут организовать выставки. Анализ поведения зрителей может привести к изменениям в освещении, постановке и размещении произведений искусства по отношению друг к другу.
Другим примером применения технологии стал анализ привлекательности статуи Аполлона Вейского, датированной 510-500 годами до Нашей Эры. Хотя кураторы Римского национального этрусского музея считали её одним из украшений коллекции, на неё обращают внимание лишь немногие зрители. Если бы статую разместили по принципу «лучшее напоследок», то её бы вообще не стали смотреть, пояснили в ENEA.

Аполлон Вейский / Фото из Мировой исторической энциклопедии
Дополнительно к описанному выше функционалу, камеры предупреждают персонал музея, если посетители находятся слишком близко друг к другу или снимают маски. Данные, получаемые с камер ShareArt, являются конфиденциальными. В частности, они не выполняют распознавание лиц, а фотографии посетителей после обработки нейросетью сразу же удаляются. Художники положительно оценили новую технологию: они утверждают, что ShareArt предоставляет ценный инструмент анализа влияния искусства на людей и выводит на новый уровень диалог между человеком и искусством.
Показать полностью
3
Робота обучили передвигаться, как четвероногое животное

Исследователи из UC Berkeley обучили робота имитировать поведение собаки с помощью обучения с подкреплением. Предложенный фреймворк масштабируется на другие виды животных. Модель получает на вход видеоролик с записью движения животного. На основе входного ролика RL-агент выучивает политику контроля движений, которая позволяет ему имитировать движение. Поддержка других видов движения добавляется аналогично. Исследователи обучили RL-агента выполнять такие действия, как поворот, быстрая ходьба и прыжок. Политики агент выучивает в симуляции. Затем модель переносится в реальный мир с помощью метода адаптации скрытого пространства, который позволяет адаптировать политику к реальной среде на основе коротки видеозаписей реального робота.
Ниже - описание самой научной работы в формате видео
Архитектура фреймворка
Предложенный фреймворк состоит из трех этапа:
1. Переоценка движения, во время которой движения животного на входной видеозаписи соотносятся с движениями робота;
2. Имитация движения, когда выход из первого этапа используется для обучения политики имитации движения агента;
3. Адаптация к реальной среде, когда обученная модель из симуляции переносится на реальную среду
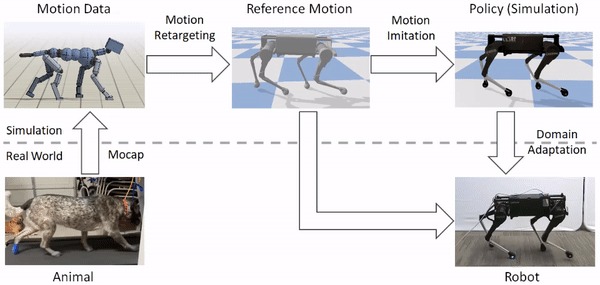
В качестве робота использовали модель четвероногого робота от Laikago.
Проверка работы алгоритма
RL-агент способен выучивать различные типы движений собаки. Среди типов движений — разные виды ходьбы, включая бег рысью или неспешный шаг, и быстрые повороты. Если обучать агента на видеозаписях с ходьбой, отмотанных в обратную сторону, то робот научается ходить назад.


Сравнение поведения до и после обучения робота: до адаптации робот склонен к падению в ходе выполнения задачи; после же тот готов последовательно исполнять предлагаемые команды.
Показать полностью
3
1
Google AI опубликовали датасет для восстановления 3D формы зданий

Исследователи опубликовали датасет с неструктурированными изображениями культурных объектов. Он включает в себя 25 тысяч изображений, каждое из которых содержит информацию о местоположении и наклоне. Данные собирали из открытых источников в интернете. Датасет создавали в сотрудничестве с UVIC, CTU и EPFL.
Восстановление 3D структуры зданий
Реконструкция 3D объектов и зданий из последовательности изображений (Structure-from-Motion) — это одна из открытых проблем компьютерного зрения. Одним из применений таких моделей является возможность изучения культурных объектов в браузере.
Google Maps уже использует изображения пользователей для обновления списка популярных мест или рабочих часов места. Однако использование такого типа данных для построения 3D моделей является более сложной задачей. Это связано с тем, что поступающие изображения имеют большую вариативность в том, с какой позиции снимали кадр, перекрывали ли люди объект на кадре и какие были погодные условия и освещение.
Что внутри датасета
Опубликованный датасет включает в себя 25 тысяч изображений из датасета YFCC100m. Каждое изображение имеет данные о позе (локация и направление). Исследовали сгенерировали тестовые 3D модели с помощью крупномасштабной SfM модели, которая использовала от сотен до тысяч фотографий здания для восстановления формы объекта. Такой подход не потребовал использования сенсоров или человеческой разметки для сбора данных.

3D форма объекта (Фонтан Треви), которую восстановили из 3 тысяч фотографий
Показать полностью
1
Ответ на пост «Этого человека не существует»1
StyleGAN2: улучшенная нейросеть для генерации лиц людей
Встречаем StyleGAN2 — вторую версию нейронной сети, которая создает реалистичные изображения людей и предметов. Пока мы стебались над тем, кто она не умеет воспроизводить человеческие уши и волосы, нейросеть качалась.
После просмотра результатов обучения как-то уже несмешно.
Протестировать работу нейронной сети - thispersondoesnotexist.com

В StyleGAN2 обновили архитектуру модели и методы обучения, чтобы минимизировать количество артефактов на генерируемых изображениях. Артефакты — это части изображения, которые снижают его реалистичность. Примером артефакта является размытость части изображения.
В частности, исследователи добавили измененные нормализацию генератора, регуляризацию генератора и прогрессивное повышение (progressive growing). Добавление регуляризатора в генератор решает проблему качества изображений и позволяет распознать изображения, которые были сгенерированы определенной нейросетью.
StyleGAN
Предыдущей state-of-the-art архитектурой для генерации изображений являлась StyleGAN модель. Отличительной чертой модели является архитектура генератора. Генератор принимает на вход промежуточное представление входного объекта. Слои генератора проходят через адаптивную instance нормализацию (AdaIN). Несмотря на высокие результаты по сравнению с конкурирующими подходами, оригинальная StyleGAN генерирует изображения с заметными артефактами.
StyleGAN2
В генераторе StyleGAN2 были убраны излишние операции в начале, вынесли суммирование bias термов за пределы блока стиля. Обновленная архитектура позволяет заменить instance нормализацию (AdaIN) на “демодуляцию”. Операция демодуляции применяется к весам каждого сверточного слоя.
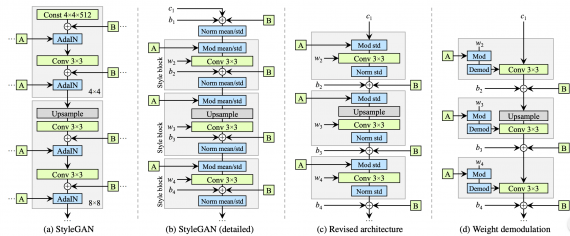
Сравнение составных частей StyleGAN (a-b) и StyleGAN2 (c-d)
Оценка работы модели
Для сравнения качества сгенерированных изображений исследователи использовали стандартные метрики: Frechet inception distance (FID) и Precision and Recall (P&R). Ниже видно, что внесенные в архитектуру StyleGAN изменения (B-F) улучшают качество изображений.

Сравнение результатов базовой StyleGAN и ее модификаций на датасетах FFHQ и LSUN Car
Показать полностью
3
1
BodyPix: сегментация людей в реальном времени с TensorFlow.js

BodyPix — это нейросеть для сегментации людей и частей тела в реальном времени в браузере. С дефолтными настройками модель сегментирует людей и части тел с кадровой частотой 25 на 2018 15-inch MacBook Pro и 21 кадр в секунду на IPhone X. Проверить работу демо-версии в браузере можно по ссылке. Исходный код модели доступен в Github репозитории.
В последнем обновлении библиотеки BodyPix 2. стали доступны сегментация нескольких людей сразу, новое API, квантизация весов и поддержка изображений разного размера. Помимо этого, точность модели стала выше в сравнении с ResNet50.
Сегментация человека в BodyPix
В компьютерном зрении задача сегментации изображения относится к группировке пикселей изображения в семантические участки объектов. BodyPix модель обучили не только сегментировать людей, но и распознавать 24 части тела. Другими словами, нейросеть классифицирует пиксели изображения на две категории:
1. Пиксели, на которых изображен человек;
2. Пиксели, на которых изображен фон
Для задачи сегментации человека модель выдает для каждого пикселя вероятность того, что это пиксель человека. Аналогичный процесс происходит для сегментации 24 частей тела. Для каждого пикселя модель выдает номер класса части тела. Пиксели, которые не являются частью тела, отмечаются отдельным классом.
Что внутри модели
Сама модель BodyPix в демо-версии — это MobileNet. Исследователи дополнительно обучили ResNet50 и получили качество лучше, но остановились на MobileNet из-за более высокой скорости работы в бразуере.
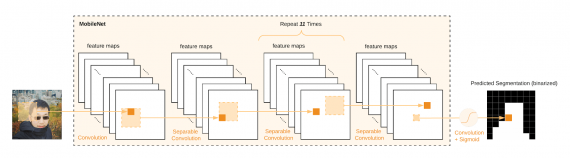
Архитектура обученной MobileNet

Показать полностью
2
Нейросеть анимирует персонажей в игровой среде

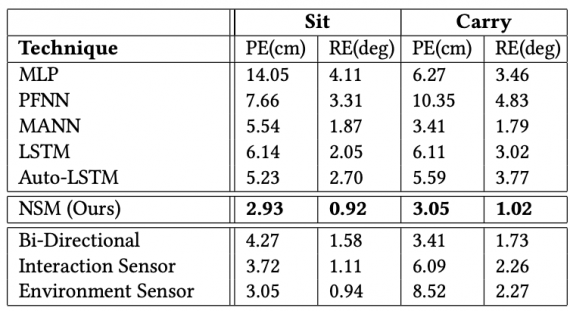
Исследователи из University of Edinburgh обучили нейросетевую модель анимировать игровых персонажей. Нейросеть предсказывает, как персонаж должен взаимодействовать со средой, чтобы выполнить какое-то действие. Среди действий — такие, как сидеть, стоять, передвигаться, избегать препятствия и поднимать предметы. Архитектура модели базируется на Neural State Machine.
Даже простые задачи, как сидеть на стуле, сложно моделировать с помощью обучения с учителем. Сложность заключается в том, что такая задача предполагает комплексное планирование и умение ориентироваться в среде. Neural State Machine моделирует взаимодействие игрока в сменяющихся сценах.
Нейросеть принимает на вход целевую локацию и тип действия, который необходимо совершить. На выходе модель выдает последовательность шагов для совершения целевого действия. Чтобы персонажи адаптировались к специфике геометрии среды, исследователи включили в модель метод для аугментации данных. Это позволяет случайным образом сменять 3D геометрию среды, при этом сохраняя контекст изначального действия. Благодаря такому подходу нейросеть обучается действовать в отличных друг от друга средах.
Что внутри нейросети
Архитектура системы состоит из gating сети и сети для предсказания движений. Gating сеть принимает на вход подвыборку параметров текущего состояния и вектор целевого действия. На выходе gating сеть отдает коэффициенты для блендинга предыдущих действий, которые используются для предсказания следующего действия. Сеть для предсказания движений принимает на вход переменные контроля позы и траектории персонажа и выход gating сети. Затем модель предсказывает параметры следующего действия.
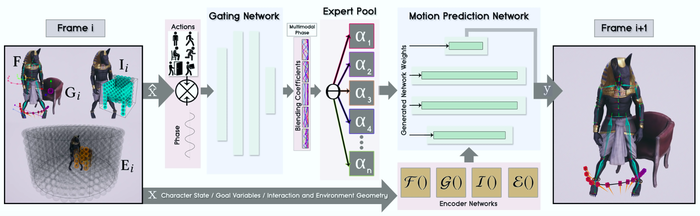
Визуализация составных частей нейросети
Проверка работы модели
Показать полностью
2
1
Нейросеть от Samsung научила Распутина петь голосом Beyonce

Исследователи из Центра ИИ компании Samsung в Кембридже и Имперского колледжа в Лондоне создали end-to-end генеративно-состязательную сеть (GAN), которая анимирует и синхронизирует движения лица на 2D-изображении с аудиозаписью, содержащей голос. Благодаря этому создается впечатление, что голос с аудиоклипа принадлежит лицу на изображении.
Модель синхронизирует движения губ, движение бровей, а также делает синтезирует мигание глаз, чтобы сделать изображения более естественными. Синхронизация губ со звуком сегодня часто реализуется путем пост-редактирования или с использованием компьютерной графики.
Исследователи полагают, что модель может быть использована для автоматического создания говорящих голов персонажей в анимационных фильмах, заполнения пробелов при пропусках видеокадров во время видеозвонков с низкой пропускной способностью или для обеспечения лучшей синхронизации губ или дублирования фильмов на иностранных языках. Технология также может быть использована для других манипуляций с поддельными персонами.
В примерах, которыми поделились исследователи на YouTube: мертвый русский мистик Распутин, поющий песню Beyonce «Halo», рэперы 2Pac и Biggie, исполняющие свои работы, и Альберт Эйнштейн, цитирующий цитату об общем языке науки. Дополнительные примеры и документ с описанием модели можно найти на этом сайте. Код модели опубликован на github, и вы можете самостоятельно проверить ее работу.
Эта новость появилась через месяц после того, как центр ИИ компании Samsung в Москве представил AI для анимации 2D-изображений без 3D-моделирования. Это технология, которая может быть использована для создания более правдоподобных цифровых аватаров или глубоких подделок.
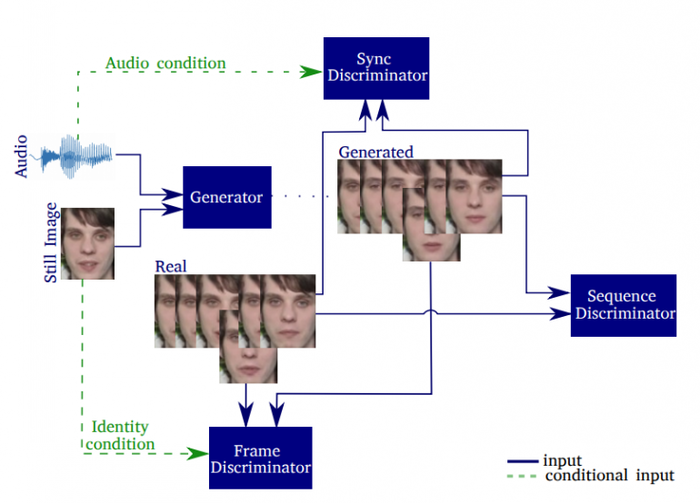
Модель использует 3 дискриминатора, чтобы объединить разные аспекты, влияющие на восстановление изображений
Модель использует 3 дискриминатора, ориентированных на детализацию кадров (frame discriminator), синхронизациию изображения с аудиозаписью (synchronization discriminator) и реалистичности выражений лица (sequence discriminator). Выполняется оценка вклада каждого компонента в модель. Сгенерированные видео оцениваются на основе резкости, качества реконструкции, точности считывания по губам, синхронизации, а также их способности генерировать естественные моргания.
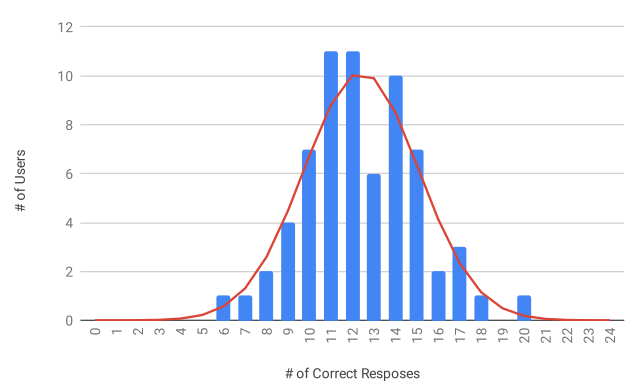
Распределение результатов Тьюринг-теста на сайте модели
Еще раз github
и еще раз Сайт модели
Показать полностью
2
1