💡 Зачем это читать:
Если ты когда-то хотел запустить свой продукт, но откладывал из-за «недостатка ресурсов» — это история для тебя.
Если тебе интересно, как рождаются реально полезные вещи — из боли, рутин, неудобства — тебе сюда.
Если ты хочешь понять, как мыслит команда, которая делает сервис для реальных людей, а не питчей — ты на месте.
🛠️ О чём конкретно будем рассказывать:
Зачем вообще всё это понадобилось
– как идея родилась из личной рутины
– голосовые, заметки, неуспевание фиксировать мысли
– «хочу просто сказать и получить нормальный текст»
С чего было начало технической части
– Python + библиотеки для распознавания речи
– эксперименты с Vosk, Whisper
– первые сломанные скрипты и первая фраза, которую система распознала
Почему Telegram и MVP за пару дней
– запуск без фронта и лишней сложности
– простой бот, отправляешь голос — получаешь текст
– реакция друзей: «Эммм… Это ты сделал?»
– как фиксили баги в реальном времени
Работа с текстом: сделать не просто транскрипт, а читаемый текст
– как начали «чистить» речь
– от удаления "э-э", "ну", до перестроения структуры.
– И создания правильного форматирования с разбиением на абзацы
Сайт, демка, первые фидбеки
– как собирали сайт для демонстрации
– кто первые пользователи, как реагировали
– какой фидбек оказался самым неожиданным
Что было самым сложным
– не техническая часть
– не бот
– а сделать так, чтобы продукт был «невидимым», простым и реально полезным
Что будет дальше
– продолжаем тестирование и доработку
– активно собираем фидбек, чтобы сделать продукт ещё лучше
– в ближайших статьях расскажем о новых фичах и о том, как развиваем систему дальше
Как пришла мысль разработки продукта?
Я по профессии специалист по компьютерным сетям и программист. Основная часть моего времени уходит на работу с кодом, но иногда хочется разобраться и в чём-то новом. Так я решил изучить тему право интеллектуальной собственности — просто для себя.
Чтение началось бодро: статьи, материалы, заметки. Но через какое-то время заметил, что информации становится слишком много. Прочитал абзац — вроде понятно. Перешёл к следующему — и тут понял, что не могу вспомнить, что было в предыдущем. Всё смешивается. Начал ловить себя на том, что читаю одно и то же несколько раз, потому что просто не удерживается в голове.
Тогда я решил записывать. Казалось бы, логично: фиксировать ключевые мысли, чтобы потом не забыть. Сразу вспомнились студенческие конспекты — быстро записать и забыть. Но когда стал делать это сейчас, уже осознанно, стало понятно, что такое способ обучение крайне не эффективный.
Во-первых, я начал писать от руки — и быстро столкнулся с тем, что потом с трудом разбираю свой почерк. Иногда вообще не могу понять, что хотел сказать. Во-вторых, редактировать такие записи практически невозможно. Ошибся — надо зачеркивать. Хочешь вставить мысль — уже негде. Всё выглядит одинаково важным, найти нужное потом тяжело.
Я решил поискать, как люди в целом ведут конспекты, чтобы делать это эффективнее. Обратился к ChatGPT — он выдал список из семи основных техник:
7 популярных методов конспектирования:
Метод Корнелла
Разделение страницы на три части: ключевые слова, основные записи и краткое резюме. Это помогает структурировать информацию и облегчить повторение.
Метод обрисовки (Outline)
Классическая иерархия: заголовки и подпункты, удобен для логической структуры.
Картирование (Mind Map)
Основная тема в центре, от неё расходятся подтемы, помогает визуализировать связи.
Метод боксов (Boxing Method)
Информация делится на блоки, каждый с одной темой, что ускоряет поиск.
Метод предложений (Sentence Method)
Короткие предложения без структуры, удобно для быстрого фиксирования информации.
Метод таблиц
Информация в виде таблицы с терминами, определениями, примерами и комментариями, удобно для сравнений.
Цифровой метод (Zettelkasten)
Каждая мысль — отдельная карточка, между ними устанавливаются связи, идеален для долгосрочной базы знаний.
Каждый метод интересен по-своему, но все они требуют усилий: остановиться, переосмыслить, оформить. Иногда на это уходит больше времени, чем на само чтение — особенно если хочется не просто написать, а понять и потом использовать.
Я понял, что в моём ритме это не работает. Нужно было что-то быстрее и проще — тогда я начал экспериментировать.
Я заметил, что лучше всего усваиваю материал, когда пересказываю его. Даже не кому-то, а самому себе. Это помогает закрепить смысл в голове. Так родилась идея проговаривать ключевые мысли вслух.
Я стал читать абзац, а затем кратко пересказывать его на своём языке — без заучивания, просто чтобы проверить, понял ли я суть. В этот момент включал запись на телефоне. Получались короткие голосовые заметки по 20–30 секунд.
Позже я прослушивал их или переводил в текст с помощью распознавания речи. Это оказалось неожиданно удобно: голосовые фрагменты не перегружены деталями, в них остаётся главное — и это мои собственные формулировки.
Так я пришёл к формату, который действительно сработал: понятный пересказ — в аудио. Без лишней структуры и ручной писанины. А при необходимости — всё можно превратить в текст, структурировать, сохранить или передать системе, которая поможет с анализом.
Этот подход оказался значительно эффективнее привычных заметок. Я больше не пытался записать всё подряд — только то, что действительно понял. Это экономило время и помогало лучше усваивать материал.
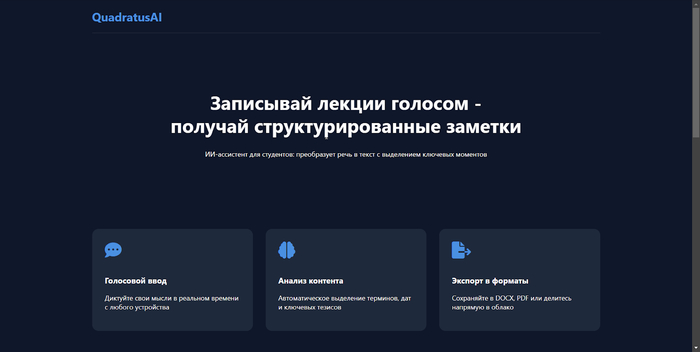
Со временем появилась потребность автоматизировать процесс — и тогда я решил сделать веб-сервис, который бы помог сохранять и обрабатывать голосовые заметки. Для быстрого запуска я сначала настроил сохранение записей в Telegram, как самый простой и доступный способ. Подробно о реализации, сложностях и технических деталях расскажу чуть ниже.
Главное, что я понял — самый простой способ иногда оказывается самым эффективным. Важно просто найти тот формат, который подходит именно тебе.
2. С чего было начало технической части
Всё началось с идеи, которую я придумал в голове, и с опросов среди друзей, чтобы понять, кому этот продукт может быть полезен. Я быстро понял, что идея голосовых заметок и их автоматического преобразования в текст могла бы быть полезной в разных сферах: от образования и бизнеса до повседневных задач. Это стало основой для следующего шага.
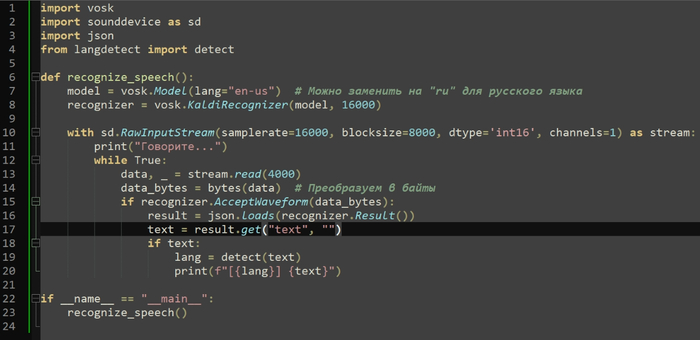
Затем я начал изучать основные фреймворки для работы с распознаванием речи. В первую очередь обратил внимание на Python и библиотеки для распознавания голоса, такие как Vosk и Whisper, а также на коммерческие решения от крупных компаний, таких как Яндекс. Это дало мне представление о том, что доступно в плане технологий.
Мой первоначальный план был прост: я хотел превратить голос в текст, затем обработать текст с помощью алгоритмов для выделения ключевых слов и идей, а затем передать это пользователю через веб-интерфейс. Я выбрал Django для бекенда, так как он казался идеальным выбором для быстрого старта.
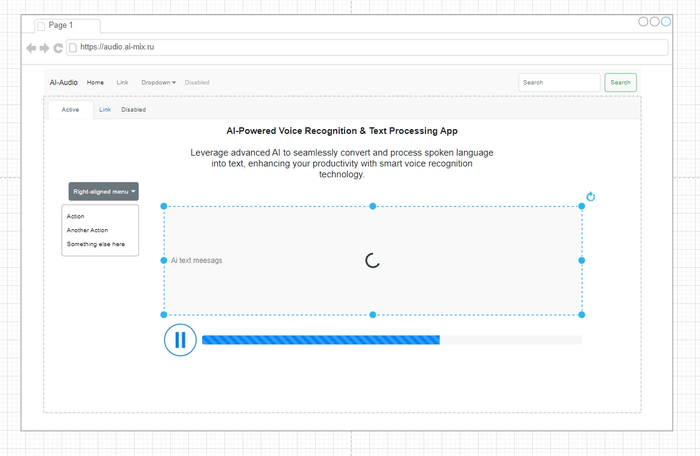
Приблизительный макет проекта Визуал
Я начал с экспериментов с различными фреймворками, включая Vosk и Whisper. Решение использовать локальные нейросети для распознавания голоса оказалось одним из наиболее подходящих вариантов, так как оно позволило работать без зависимости от облачных сервисов. Однако, после нескольких тестов и установки моделей для распознавания, я понял, что интеграция будет сложнее, чем я ожидал.
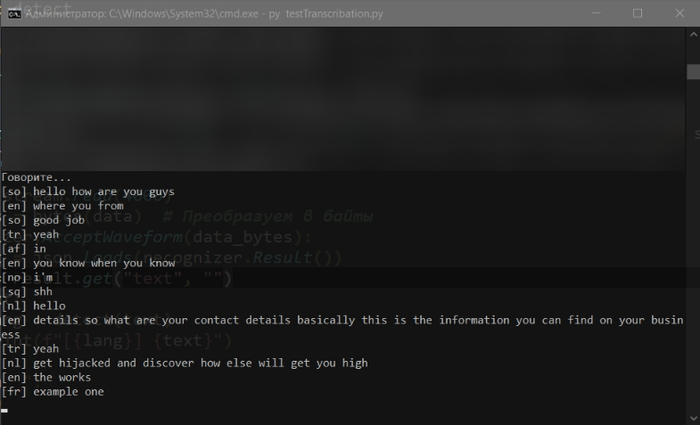
Вариант тестов английской модели (легкие быстрые модели для экспериментов)
Далее я провел оценку времени, которое займет реализация всего проекта: от разработки фронтенда и бекенда до интеграции голосового распознавания и создания пользовательского интерфейса. Примерные расчёты показали, что на весь процесс может уйти от 3 до 6 месяцев.
Рассчитав, что времени на реализацию будет достаточно, я решил сосредоточиться на тестировании технологии и на том, как она работает в реальных условиях. И в какой-то момент, уже наблюдая за развитием технологий в этом сегменте, я увидел, что те компании, о которых я думал, уже сделали то, что я собирался только начать.
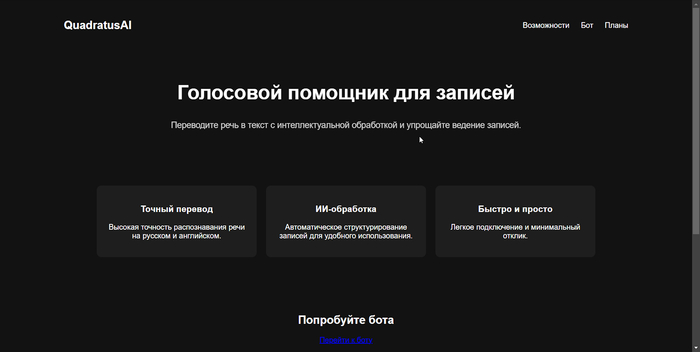
3. Почему Telegram и MVP за пару дней QuadratusAI
После серии тестов с распознаванием речи на базе Vosk и Whisper, а также после анализа конкурентов, стало ясно: времени на полноценную реализацию проекта — с фронтендом, бэкендом, пользовательским интерфейсом и всей обвязкой — нет. Разработка сайта с названием QuadratusAI, его подключение к распознаванию и создание визуального интерфейса могла бы занять месяцы. Это был бы хороший следующий шаг после получения обратной связи, но не первоочередной.
Я понял, что нужно запускаться максимально быстро, без лишних слоёв сложности. Так родилась идея Telegram-бота — простого, понятного и доступного для всех моих знакомых. Никакого веб-интерфейса, никаких регистраций — только Telegram, только голос и текст.
Я сел в выходные и полностью сосредоточился на создании минимального жизнеспособного продукта (MVP). На тот момент у меня не было опыта написания ботов для Telegram, и весь код оказался в одном файле — громоздком и запутанном. Я не до конца понимал, как правильно организовать взаимодействие с Telegram API, как обрабатывать разные события и команды. Несмотря на это, базовая логика работала: ты отправляешь голосовое сообщение — получаешь текст в ответ.
Первые пользователи, в основном друзья, были удивлены:
«Эммм… Это ты сделал?» — такой была типичная реакция.
Параллельно с этим шла "боевой режим" — баги и ошибки устранялись прямо во время использования. Например, где-то не обрабатывались ошибки при скачивании файла, где-то Telegram возвращал неожиданный формат. Всё это приходилось чинить на лету.
Позже я начал добавлять функциональность — например, подключил облачную текстовую нейросеть, чтобы дополнительно очищать распознанный текст, убирать артефакты речи, структурировать его. Следующим шагом стало выделение ключевых слов и добавление эмодзи, чтобы текст выглядел более живо и дружелюбно в формате Telegram-сообщений.
Также в планах появилось ещё множество идей: распознавание спикеров, интеллектуальная фильтрация, интеграция с внешними сервисами. Но запуск через Telegram дал главное — возможность быстро проверить гипотезу, получить реальные отклики и продолжать развивать идею без длительных задержек на подготовку.
4. Работа с текстом: сделать не просто транскрипт, а читаемый текст
Распознавать речь — это только половина задачи. Вторая, не менее важная часть — превратить сырую транскрипцию в читабельный, структурированный текст, пригодный для восприятия.
На этом этапе началась работа с «очисткой» речи: удаление слов-паразитов, таких как «э-э», «ну», «короче», избавление от лишних пауз, повторов и артефактов устной речи. Одной только транскрипции было недостаточно — нужна была перестройка структуры фраз, чтобы текст был логически связанным и не терял смысла.
Все эти задачи решались через разные промты и тесты — постоянно пробовались новые интерпретации, варианты запросов к языковой модели. Цель была одна: оставить суть, вычистив шум. И шёл поиск оптимального баланса: чтобы и смысл сохранялся, и текст становился ближе к «человеческому» письму — со склонениями, правильным порядком слов и логикой изложения.
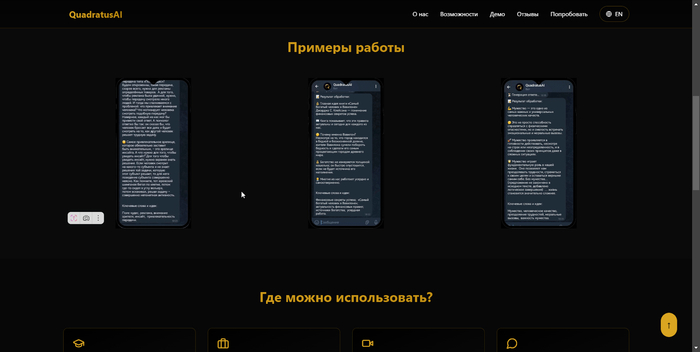
5. Сайт, демка, первые фидбеки
После создания рабочего Telegram-бота появилась идея подготовить демонстрационный сайт QuadratusAI.
Цель — презентовать проект, собрать первые отзывы и протестировать реакцию аудитории. Также это был шаг в сторону будущего полноценного веб-интерфейса.
Пример с использованием DeepSeek
Генерация сайта с помощью нейросетей
Для ускорения процесса разработки было решено использовать нейросети и ChatGPT.
План состоял в следующем: описать идею, получить сгенерированный HTML/CSS/JS-код и как можно быстрее развернуть результат.
Однако на практике генерация сайта оказалась далекой от идеала. В ответах модели были ошибки, неполные блоки, либо слишком сложная структура.
Была предпринята попытка использовать полный стек генерации, включая React + TypeScript, но пришлось дорабатывать код вручную, местами редактируя результат через Cursor (IDE), а местами просто «допиливая» вручную по частям.
Вместо задуманного чистого HTML + CSS + JS получилось решение на React + TypeScript + CSS, так как только в такой связке нейросеть выдавала более-менее стабильный результат.
После исправления основных багов началась работа по наполнению:
Вставка и оформление скриншотов демо-бота.
Подготовка визуальных блоков с описанием возможностей.
Перевод описания на английский язык для международной аудитории.
Сайт был размещён на бесплатном хостинге для сбора первых фидбеков.
Итоговая сборка и отладка заняли примерно неделю — иронично, но, как потом показалось, было бы быстрее написать всё с нуля вручную. Тем не менее, опыт стал важным шагом в проверке инструментов и подходов.
6. Что было самым сложным
Самым сложным в проекте оказалось не разработка, не интеграции и даже не баги. Эти проблемы решаются с помощью технологий и терпения. Настоящая сложность была в том, чтобы продукт был настолько простым, что пользователь даже не задумывался, как он работает.
Задача заключалась в создании интуитивно понятного и мгновенного взаимодействия без лишних шагов и ожидания. Чтобы пользователь не думал, куда нажимать или что ждать.
Архитектура была разделена на два компонента:
Первый — Telegram-бот. Он лёгкий и минималистичный, принимает голосовые сообщения и отправляет обратно текст. Обработка голоса не происходит на этом сервере, что делает его быстрым и простым.
Второй — сервер для обработки данных. Здесь происходит распознавание речи, очистка текста от лишних слов, структурирование и добавление эмоджи. Этот сервер выполняет все сложные операции, но скрыт от пользователя.
Такой подход позволил разделить критическую логику от пользовательского интерфейса. Это обеспечило гибкость в масштабировании и обновлениях без риска повлиять на работу фронтенда. Система может тестироваться и улучшаться без видимых изменений для пользователя.
Результат — простота использования: отправил голосовое сообщение — получил готовый текст. Без загрузок и прогресс-баров. Вся сложная логика скрыта, что делает продукт «невидимым» для пользователя.
Мы уже добились немалых результатов. Простой, но мощный инструмент, который когда-то казался идеей, теперь полностью работает, избавляя от множества рутинных задач. Всё, что нужно сделать, это просто сказать — и система превращает ваш голос в чистый, структурированный текст.
От разработки до тестирования — мы сосредоточились на том, чтобы пользователю не приходилось думать о том, как всё работает. Бот в Telegram работает без лишних шагов и интерфейсов. Система обрабатывает голос, очищает его от ненужных слов, выделяет ключевые моменты и возвращает результат, как если бы это была самая естественная часть общения.
Но мы не останавливаемся. Уже сейчас мы собираем фидбек и работаем над улучшением функционала. Скоро появятся дополнительные возможности, которые сделают продукт ещё проще и удобнее. Мы уверены, что эта простота и эффективность помогут вам избежать сложностей с записью мыслей и идей в любой ситуации.
Пробуйте, и вы сами увидите, как это может быть полезно в повседневной жизни. Заходите на сайт, тестируйте в боте — и почувствуйте, как это работает.
Как вы чаще всего фиксируете свои идеи или заметки?