
Кино вино и домино
3 поста
3 поста
26 постов
35 постов
13 постов
9 постов
11 постов
— человечество будет разделено на две неравные части;
— человечество будет разделено на две неравные части по неизвестному нам параметру;
— человечество будет разделено на две неравные части по неизвестному нам параметру, причем меньшая часть форсированно и навсегда обгонит большую;
Для лиги лени: tldr.
Во первых строках моего письма к Вам, разлюбезные моему сердцу читатели, хочу сообщить, что на моем текущем месте работы закрыли найм из РФ, оставили только текущий просев, «вдруг повезет». Не потому, что мы такие жадные (и это тоже, конечно), но:
1) Приближается Праздник, Ханука, Йоль, Рождество, потом Тет.
Текущие проекты или доделываются, или переносятся, тем штатом что есть. Есть эмпирическое правило, что последний срок приема проекта – 14 декабря, потом только подписание закрывающих документов, итд.
2) В РФ в части фирм выплата годовых бонусов обычно идет в январе-феврале, иногда марте, и, конечно, мало кто хочет упустить 2-3-6 окладов. Кое-где в РФ (и не в РФ) и 12 месячных окладов могут выплатить. После выплат, особенно если кому-то обещали 3 оклада, а дали 1, со словами «времена такие», ситуация с свободными сотрудниками значительно меняется.
Поэтому сейчас напрягаться нет смысла, пусть HR спокойно закроют свой год.
3) Уехавшие из РФ «сколько-то» сотрудников уже обжились, втянулись, и начинают стандартную рабочую миграцию. Они точно знают что хотят, чего могут, учат (и до этого учили) иностранные языки, и они «уже тут». Это помогает.
4) Почти все, за редкими исключениями, кто хотел и мог, а не хотел «10к$ после налогов, могу ставить винду»:
или уже уехали,
или доделывают проекты и едут,
или точно решили не ехать (хотя могли бы),
или, только говорят, что они то хотели бы, но ничего не делают для этого. Иностранный язык – не учили и не учат, современные практики чего угодно – не знакомы,
или их реальный уровень очень далек от «сеньоров». Подпись в почте есть, знаний нет.
Русский рынок кандидатов, готовых к переезду и при этом годных, выгребен, а новые кандидаты на нем стали «доучиваться из перспективных джунов» гораздо реже.
Некому доучивать. Негде массово доучиваться.
Что же творится с самим рынком?
Для начала немного информации о загнивающем, с Реддита.
Переводить не буду, и так все понятно.
IRA - An individual retirement account . В РФ этого нет, в РФ все пенсионные накопления контролируются государством, прямо или косвенно. Это как национальное достояние – когда надо, то национальное, когда дивиденды, то все не так однозначно.
PTO - Paid time off. Оплачиваемый отпуск.
CPI - Consumer Price Index. Индекс потребительских цен.
Here's what we did in the past couple of years:
Average wages are at ~$100,000/y.
Right now the CEO's base wage is just shy of $200,000/y.
5% profit sharing pool for all the employees. (CEO is outside of this pool)
5% matching on IRA's
Stock options for all employees.
Two weeks PTO for all positions plus all holidays.
Two weeks additional PTO that can be used during the summer months when the business is slow. This can be traded for a 4% raise.
Work culture that respects people. We've never denied a PTO request.
Management treats workers with respect.
Work from home available for all positions at least once or twice a week.
Annual reviews for performance bonuses and CPI wage increases.
We don't ask people to work outside of regular work hours unless it is an event and there is a ton of notice or a huge emergency. Then call are under five minutes.
We treat everyone to a nice lunch at a sit down restaurant as a group once a month.
Large Christmas bonuses
I avoid saying things like "We are a work family!" (You all ruined that for me.) I'm aware that people are trying to support their real families primarily. We also never have a "pizza party".
Вы скажете «ууу, всего сто, это же из них налоги 99.95%», и будете правы. Потому что:
Согласно информации, опубликованной Business Insider, сотрудники Microsoft поделились данными о своих зарплатах и карьерном росте, что дало возможность проанализировать финансовые условия в компании. В результате выяснилось, что средняя зарплата инженера-программиста в Microsoft варьируется от 148 436 до 1 230 000 долларов в зависимости от уровня должности, который может быть от 59 до 69. Однако среди сотрудников нового отдела искусственного интеллекта, созданного в марте, средняя зарплата составляет впечатляющие 377 611 долларов.
Для рынка РФ ситуация сложнее, и на это влияет много факторов.
Некоторые «импортозаместители» узнали, что написать новый блокнот недостаточно.
Некоторые «импортозаместители» узнали, что написать только новый веб интерфейс к ceph или linstor недостаточно, а shared lvm – не очень надежная конструкция.
Некоторые «импортозаместители» узнали, что для перехода на KVM нужно минимум в 1.5 раза больше железа. Недавно вышедшее сравнение «VM density» - Сравнение VMware vSphere 8 Update 3 и Red Hat OpenShift Virtualization: в 1.5 раза больше ВМ и на 62% больше транзакций – перевод, оригинал показывает почему.
Все, кто на самом деле интересовался вопросами производительности и плотности, отлично знали и про работу планировщика в Linux, и про проблемы балансировки нагрузки – все это было оттестировано в РФ еще году в 2015-2020. Только не в публичных группах. Все знали, но игнорировали.
Есть указ, что надо переходить, но переходить до сих пор некуда, так чтобы переходить «под ключ».
Заниматься переходом тоже некому.
Да и не выгодно это, серьезно заниматься переходом – на отсутствие кадров можно списать что угодно.
Пока 9 из 10 российский работодателей испытывают ужасающий дефицит высококвалифицированных низкооплачиваемых работников, ничего меняться не будет.
О каком переходе речь, если РФ до сих пор не то что делать, а даже понимать не хотят, что MAES-512, xor49, AES256 / SFR и RDA/RDS не одно и то же, хотя очень просто. Проще чем KVM в ядре. Но нет. Опять же, кому надо, тот в курсе.
Дороги Анны Фирлинг идут куда надо.
Поэтому наблюдаем что?
Наблюдаем, что по Top Countries by Computing Power – по графе Maximum performance (TFlops) Россия отстает от Саудовской Аравии.
Методика не очень ясна. Хотя, если учитывать мощность xAI Colossus, то понятно, откуда разрыв.
Как это влияет на рынок труда в целом?
Напомню, что рынок труда не един.
Есть Москва, и есть остальные субъекты РФ. ДС Can Be Only One
Есть несколько больших блоков «трудовых резервов» - тут и техническая поддержка, от поддержки рабочих мест до FSE (field service engineer , который и код пишет), и поддержка инфраструктуры разных размеров, и разработка – как коммерческая на Java, C (++,#, Objective), Swift, и далее, так и страдающая на грани нищеты российская embedded. Отдельно живет поддержка по настоящему взрослых решений, и промышленных, где туда-сюда перемещают ковш в 50 тонн стали, и финансовых, где за остановку на пару часов не похвалят.
Напомню, что в прессе есть «блок на негатив», на СМИ «Хабр» – вплоть до бана за «неприятные» новости.
Можно: писать про то, что 9 из 10 российский работодателей испытывают ужасающий дефицит высококвалифицированных низкооплачиваемых работников,
Нельзя: писать про то, что провал «импортозамещения в ИТ» - результат того же стиля управления, что в авиации:
Основной причиной перестановок в руководстве крупнейших российских производителей гражданских самолетов стал проведенный по поручению правительства летом текущего года аудит Объединенной авиастроительной корпорации (ОАК), головной компанией которой является «Ростех». Об этом со ссылкой на собственные источники пишет «Коммерсантъ». Как утверждают источники, аудит зафиксировал проблемы проектного управления в ОАК, которое «критически не соответствует масштабу и сложности».
25.11.2024 У авиазаводов разлетелось руководство
12.12.2024 Полет вправо. Сможет ли Россия опять строить пассажирские авиалайнеры?
Или того же стиля в микроэлектронике:
06 Декабря 2024. Как выяснил CNews, в отношении зеленоградской микроэлектронной компании «Ангстрем» введена процедура наблюдения. Это решение принято по заявлению банка «Зенит» о признании должника банкротом было принято 2 декабря 2024 г.
Cnews
Статистика? Взяться каким-то статистическим данным просто неоткуда:
компании публикуют фейковые вакансии, чтобы показать «как бы найм»,
сотрудники делают фейковые резюме, чтобы их не отслеживали с текущего места работы.
Рынок труда сегментирован настолько, что у троих бывших коллег в РФ:
у первого заплата с 2020 выросла с 150к до 450к рублей. Ноет, что ему уже предлагают 600к, но три оклада премии терять не хочет.
у второго выросла с 2020 с 150 до 250. Ноет, что нормальной работы нет.
третий работу ищет, но не находит, с лета.
Почему так?
Первый работает, так скажем, около разработки, и сам немного пишет. Как немного. Сотню строк в месяц на С#. По иностранному это будет Site Reliability Enginer (SRE).
Второй – толковый линукс-администратор, не самый плохой лидер администраторов, но. Очень любит работать руками, но не любит программировать. Баш скрипт написать может, использовать гит – уже нет, алгоритмы и структуры данных – совсем нет. Английский собирается пойти учить минимум с 2018.
Третий – наглядный пример того, что бизнес – это не про «человеческие» отношения. Человеку всего 40, со своих 25 он стремился уйти в руководство, показать какой он лидер и начальник, и в итоге имеет остаточный технический беграунд, но. Но по состоянию на 10 лет назад. Имеет огромный руководящий опыт – но в рамках той структуры, которой больше нет. Я очень рад, что мне не надо думать, можно ли его нанимать, потому что его сначала надо переучивать – потому что тут возникает проклятый вопрос «зачем». Его технические знания остались на уровне 2012 - 2014 года, где нет такого множества вариаций на тему контейнеров и оркестрации. Свой docker-compose.yml «сейчас» он не напишет, а для скачивания готового, и его редактирования, нужен специалист 20-25 лет, с окладом не в ожидаемые этим кандидатом 600к рублей, а в честные джуновские 1500$. Только джун пойдет учиться дальше, оставаясь в пределах 1500-2000$, а тут куда идти? Живая трагедия менеджмента младшего и низшего среднего звена, разучившегося работать головой, а не языком.
Дополнительно можно сказать, что:
Первый коллега имеет и разговорный английский, и публичный гит, и не в любой момент, но может выйти на международный рынок и за 3-6 месяцев релоцироваться в Чехию.
Второй не может выйти на международный рынок. Нет разговорного английского = дорога дальше Москвы закрыта, да и для роста квалификации нужен разговорный* английский.
* Разговорный английский в данном случае не означает, что ты всегда правильно выбираешь использование a, the, no article, а то, что для тебя нет проблемы в том, чтобы сесть и прочитать 2-5-10 страниц английского технического текста, и написать с десяток вопросов по нему. При необходимости – понять, о чем тебе говорит англо (скорее, индо-английская или китае-английская поддержка), и ответить на какие-то вопросы. Когда два человека заинтересованы, чтобы их поняли, и для обоих английский не родной, проблемы чтения первой k, и прочих my phone went green green, не так существенны.
То, что индусская техподдержка идет строго по скрипту, это проблема куда больше, чем когда с той стороны такой Irish, что из трубки разве что Гинесс не приходится выливать.
И аналогично, европейская поддержка из Венгрии может и говорит по английски лучше, чем Сингапур, но технический уровень совсем разный.
Третий. Не знаю, что советовать третьему. Иногда нужны играющие тренеры, то есть люди, совмещающие лидерскую и техническую функции. Коллега откровенно не дотягивает до технического лидера, но сможет ли он стать организационным лидером, да еще и на его уровне дохода – сложно сказать.
ИТ рынок сейчас представляет собой выборку 6 скиллов из 36, а то и 7 скиллов из 49 – и вопрос в том, устроит ли нанимающую сторону его сочетание опыта, руководящих и технических знаний по выборке. Где то будут хотеть знания ArgoCD, где-то GitHub Actions, а где-то образ несут руками в тестовую среду, но зато у них огромные требования по ELK или Splunk. Угадать нельзя. Надо ходить по интервью и спрашивать, что на самом деле хочет нанимающий менеджер.
Еще очень, очень нужны вменяемые руководители проектов с техническим бекграундом, умеющие общаться с людьми. Невменяемых любителей покричать на заказчика, и поугрожать уволить свою команду, в избытке, но про это я отдельную статью уже переписываю, потому что вышло слишком сложно для хабра
Переход от тримодального к бимодальному рынку
Тримодальный характер зарплат разработчиков теперь не секрет, я как-то не догадался поискать англоязычные статьи на эту тему, а они есть.
В РФ же пока дело идет к бимодальному распределению, то есть:
Группа А. Малый и средний бизнес
Совокупные требования к квалификации в этой группе растут быстрее оклада. То есть, чтобы получать в этой группе 2 раза больше, нужно не только знать в два раза больше технических подробностей, или не писать код в два раза быстрее и с большим покрытием тестами, а еще и знать смежные отрасли, и руководить группой как лид, и подтягивать вновь прибывших как бадди. В какой-то момент требования по квалификации выходят на уровень супермена – нужно знать весь стек, используемый на предприятии, причем не просто знать, а активно эксплуатировать и развивать. Как тот персонаж из «проекта Феникс», которым затыкали все дыры.
В этой группе существует потолок – твой оклад и доход не может быть выше, чем у твоего руководителя. Его оклад и доход не может быть выше, чем у его руководителя.
Бонусами идут 100% офис, рассуждения «мы команда, нужна проактивность», бесполезные (но красивые) секретарши, двойной комплект HR, и запущенный бухучет, где на балансе стоят и «карандаши черные канцелярские - 2 шт», и «комплекс - шкаф вычислительный ШВ-40Ю-Г1200-2ВБ-МБР – 1 шт» ценой 25 миллионов.
Вам, может, смешно, но я на утилизацию в 2016 году сдавал мышки с шариком, потому что их поставили как особо ценные на учет еще в 2006 году, до изменения правил учета.
В какой-то момент число кандидатов, соответствующих таким требованиям, и настолько не ценящих себя, что они готовы на 100% офис, становится равно 0, а затем и FF – ставка есть, сотрудник уволился, и стало их FF.
Начинается зловещая долина завышенных требований, сектантов разных карго-культов, от старых «мы семья» и «работать у нас большая честь» до нью-ейдж «приветствуется инициатива» и «раньше тут был Боромир, он все делал в разы лучше, быстрее и дешевле, вот уволился, неблагодарный. И никто не хочет просто сесть и сделать нормально, но дешево».

Группа В. Крупный бизнес, построенный вокруг международных практик и стандартов
Нельзя сказать, что за карго-культистской долиной и перевалом Великого Принятия совсем уж пони-ленд. Хотя бы потому, что, хотя дружба - это магия, но магия несанкционированная. Там хватает своих мрачных историй, регуляторов, и заседаний Комитета по организации комитетов. Временами, конечно, хочется все бросить и пойти собрать что-то из исходников. Но за этим перевалом почему-то действительно начинает работать многое из того, что пытались рассказать культисты.
И то, что проактивность имеет значение, и вовсе не то, где инициатива и инициатор.
И то, что способность слушать и пытаться понять, о чем вообще говорит собеседник, пусть путано и со своей точки зрения, может или предотвратить развитие ситуации в проблему, или принести полезный и прибыльный контракт. У культистов это называется «эмоциональный интеллект», что не имеет никакого отношения к примерно измеряемой величине «интеллект», но скорее относится к тестам Войта-Кампфа и пост-травматическому базовому тесту.
И то, что тайм менеджмент и управление временем – крайне нужный навык.
И то, что токсичность и «большая, но токсичная фирма» - не просто слова.
И, даже то, что такой монстр, как «коуч» - вовсе не монстр, их разведение для получения сушеной селезенки имеет высокое народно-хозяйственное значение. У дикого коуча вкус селезенки действительно, гнилостный.
И секретарши не просто так красивые.
Но.
Всё что там работает, работает только потому, что внутри заложено исключительное недоверие к надежности человека. Шагов влево-вправо не предусмотрено, установленные процедуры нельзя обойти. Не потому, что обходить нельзя, но потому, что многие постоянно пытаются. Из таких, если их вовремя направить проверять решения на стендах, вырастают хорошие специалисты, знающие почему «не надо так», а не повторяющие «это нехорошо, потому что нехорошо». The Right Stuff.
И именно поэтому там уже не только 1С, но, зачастую, SAP. Да, это очень дорого.
При этом, технически, там то же самое. Те же x86, местами arm. Местами раньше был HPE Superdome, Spark, PS700 и прочие наглядные пособия из редбука.
Местами при этом экономия на том, на чем вроде и нельзя, но пока работает, то можно.
Но.
Найм в этот сектор теряется за массой пустых вакансий блока А.
Найм в этот сектор зачастую идет по реферальным приглашениям – когда ты знаешь людей, люди знают тебя, и зовут к себе. Не потому, что ты суперзвезда, нет. Ты просто готов работать по правилам, и, если надо, предлагать их менять, а не нарушать. В остальном, почти все то же самое, фрукт-фрукт.
И во всем этом очень интересно, как AI во всех видах уже сейчас меняет рынок труда на западе. Рост продуктивности разработчиков, предварительно, 5-15%. Куда это движение утащит низкобюджетный сегмент российского рынка, сложно предсказать.
Примечание. Изначально текст писался для хабра, но статью удалили с формулировкой «слишком сложно, и обидно для среднего читателя хабра, нет таких зарплат в РФ, вы все врете». Ссылки на хабр удалены.
Для ЛЛ: тактическая победа «синица в руке сейчас любой ценой» иногда дает стратегический проигрыш.
Необходимое примечание: статья технически сложная, сложнее, чем может осилить средний посетитель слизнябра, поэтому будет на Пикабу.
Когда-то в России и правда жило беспечальное юное поколение, которое улыбнулось лету, морю и солнцу – и выбрало «Пепси». Сейчас уже трудно установить, почему это произошло. Наверно, дело было не только в замечательных вкусовых качествах этого напитка.
Еще в сентябре
Пришлось слетать, а затем и поехать на малую родину. Так вышло, что заодно встретил одну тян из тех, что когда-то ..
Сейчас, наконец, свел разрозненные заметки и выдохнул.
Жила была девочка Марина (Марианна Юрьевна Еотова, если кому интересно). Была она веселая, добрая, детей любила. Сам процесс тоже. Но, так вышло, что я на этой Марине не женился, а женился, в данной истории не важно кто. Пусть, Евгений, добрый мой приятель, но не с берегов Невы, а с берегов .. другой, очень известной по книгам и фильмам, реки.
Вот с тех пор, сдается мне, у Еотовой на меня большой зуб. Но не такой, чтобы не дать мне второй (третий, в ж) шанс.
Слушал в том же городе старых приятелей, и начались у меня флешбеки.
Сначала про региональный российский бизнес, в части ИТ.
Приходит бизнес в ИТ - раздобудь к утру ковер . Есть частная (тактическая) задача, которую надо решить. В данном случае это была задача «сделать отказоустойчивый сервис».
Важное примечание. Именно сервис, а не приложение.
Есть больше двух решений, даже целая область решений. Можно сделать не отказоустойчивый (Fault Tolerance (FT)), а высоко доступный (HA) сервис. Если не упираться в HA на уровне VM, то для высокой доступности сервисов есть разные варианты: балансировка фронта, от F5 до haproxy, и Always on cluster, в том числе Always On availability groups, и Patroni, и что-то высокодоступное на уровне хранения, начиная от простой котлетки с пюрешкой.
Самое простое решение - общее хранилище с 2 контроллерами, 2 коммутатора, 2 ноды, 2 ИБП, 2 балансера, или 2-node vSAN Cluster, или Storage Spaces Direct 2 Node Hyper-V Cluster, или .. еще какие то варианты «всего по два и более». Если же надо, чтобы это можно было обслуживать нормально, а не выключая на всю ночь, то нужно не 2, а 2+1 ноды, и кластеризация системы, и подумать про применимость k8s / k3s, и много чего еще нужно.
И ты говоришь бизнесу – идея, конечно, хорошая, но давайте сделаем проект, оценим угрозы, требования, проведем пилот, попробуем, может там подводных камней полно.
Что говорит уточка? Кря кря.
Что говорит российский бизнес? Долго, времени думать нет, денег нет, давайте опенсорс – я тут читал слизнябр, Сбербанк весь перешел на опенсорс, надежно, доступно, ну подумаешь упало. А ты вон какой, оказывается - мы тебя почти на помойке нашли, отмыли, отчистили, на работу взяли, а ты нам фигвамы рисуешь. Сразу видно, ненадежный тип, зачем вообще с тобой связались.

Индейская национальная народная изба
После этого у российского регионального ИТ есть два пути:
– согласиться делать из спичек и желудей максимально дешево, зато сейчас. Диски домашнего класса (consumer SATA, consumer grade SSD), локальный raid контроллер с помойки из 2010 года, никакой отладки, пилота, тестов.
- уволиться. Потому что построение из спичек и желудей называется кроилово, а кроилово ведет к попадалову. Прибыль будет у кабанчика, а проблемы у тебя. В среднесрочной перспективе, то есть когда (не если, а когда) эта конструкция упадет, ты будешь виноват в любом случае. Даже если ты написал 10 служебных записок, что так делать нельзя, и ты снимаешь с себя ответственность.
В первом варианте все довольны - бизнес решил тактическую задачу сейчас и дёшево.
На этот гниловатый каркас накручивается и построение «как смогли», и отсутствие документации, потому что – «я же делал, я вспомню».
Один раз так сделали, два - и все, возникает привычка каждый раз решать только эту тактическую задачу. Не обращая внимания на накопительный эффект , технический долг, и в целом.
Внезапно переход, откуда не ждали
Приходит к тебе в гости Еотова, как обычно – вечером кино посмотреть, потом чаю с булочкой, и на печку, с необычайным предложением – жениться. Ты, вроде, и не против, - и Еотова нормальная (то есть, это ты так думаешь, не определяя норму), и ничего плохого в идее нет, и вы по 3-5 дней подряд вместе проводите. Но что-то тебя в этой идее, не то чтобы настораживает, но ты предлагаешь сначала сделать пилотный проект – пожить вместе месяц-два, в отпуск вместе съездить, посмотреть на отказоустойчивость будущей ячейки общества. Потому что, мало ли.
И.
Что говорить уточка? Кря кря.
Что говорит Еотова – долго, времени думать нет, надо было сразу соглашаться. Я тут читала воменру и пикабу – все сразу взамуж, ковер и телевизор. А ты вон какой, оказывается - я тебя почти на помойке нашла, отмыла, отчистила, а ты мне фигвамы рисуешь. Сразу видно, ненадежный тип, зачем вообще с тобой связалась.
Дальше у тебя два пути:
- Покаяться, и срочно бежать в ЗАГС. И ждать, когда чего-то пойдет не так.
- Расходиться.
Вы идете в ЗАГС, и на этот гниловатый каркас накручивается и построение отношений «как смогли», и отсутствие понимания.
Один раз так Еотова сделала, два - и все, возникает привычка каждый раз решать только эту тактическую задачу. Не обращая внимания на накопительный эффект «опять продавили и кто молодец? Я молодец», и в целом.
В общем, так они и жили - спали врозь, а дети были
Бизнес прожал ИТ на кривое, дешевое, и не обслуживаемое решение один раз. Два раза. Три. Зависимость от каждой следующей системы растет по экспоненте, система не обслуживается совсем, простой все дольше. И ты начинаешь удивительные истории - ну я же говорил, ну вы тупые, не меня не слушали. Вы виноваты.
Нет.
Это решение изначально говно, все знали, что это говно, но ты его сделал, и сделал не один раз.
Меня так учили ? Всех учили. Но зачем же ты оказался первым учеником, скотина этакая?
Какая связь с Еотовой? Похожая. Один раз решение «прожать» сработало, затем начинаются одни проблемы, вторые, третьи – и Еотова каждый раз выбирает «продавить». Раз, два..
В какой-то момент бизнес решает наказать ИТ – плохо работаете, делайте хорошо!
В какой-то момент Еотова решает наказать тупого Сычева. Надуться, но не сказать, на что.
Сотрудник в ИТ опять выбирает, уйти или остаться. Уходить страшно. И остается.
Сычев опять выбирает – признать, что виноват по умолчанию, или уйти. И остается.
Бизнес доволен, очевиден тактический выигрыш - задача в моменте решена, ИТ стало слушаться.
Еотова довольна – взбрыкнувший Сычев прижат к ногтю, все работает.
Пришла беда, откуда не ждали.
Внезапно случается обычное дело. Сервер ломается, raid 5 умирает на ребилде, consumer SSD спустя полгода умирает под базой данных. Насмерть. Бекапы? Под них разве надо было делать резервы? Давно надо пойти бы купить второй сервер, и решить деньгами один раз, но это же дорого. Сервера нет, данных нет, документации нет, система стоит.
Оказывается, что тут были прочие важные данные от других сервисов, и начинается каскадный отказ. И, в лучшем случае, можно срочно побежать на рынок, и купить хоть какой сервер, но потерянные данные уже не вернуть. И хорошо, если ломается сервер, а не построивший это ИТ-специалист, который или ломается совсем, на него надевают деревянный макинтош и в его доме играет музыка. Или просто увольняется.
Бизнес идет на рынок, и удивляется, что за региональный «типа справедливый, по мнению бизнеса» прайс – никто не идет работать. Все хотят x*2 от мнения бизнеса, а посмотрев на то, что там построено – не готовы даже за деньги. Потому что зачем, если можно иметь x*2 без этой головной боли.
Внезапно случается обычное дело. Муж ломается, говорит – дальше сами. Все, как хотите. И тут выясняется, что резервного мужа нет, а он тянул очень, очень многое. Но пойти на рынок за новым мужем нельзя. И как-то быстро решить вопрос с новым сервером мужем тоже нельзя, нет магазина готовых мужей.
Тян идет на брачный рынок, и удивляется, что за ее «типа справедливое предложение – с ваc оклад, с нее ничего» – никто не хочет бороться. Все хотят борщи, ежедневные устные отчеты. И даже с обещанием борщей, посмотрев с чем придется иметь дело, не готовы даже разово отвезти в Турцию летом. Потому что можно отвезти не Еотову, а бухгалтершу, регулярно сдающую отчеты задним числом.
Что делать то?
Аудит бизнеса, проведенной сыном маминой подруги, сообщает, что вот ЭТО чинить нет смысла. Один раз можно, но, если считать честные человеко-часы на ремонт и поддержку конструкции, то это тактический тупик. Можно, но бессмысленно. Нужно менять подход в целом. Да, это работало, но сломалось, и сломается еще раз. Но делать новое дорого. Бизнес говорит – вас просили починить что есть, а не советы давать. До вас тут были такие же, за деньги любой сможет, а вы явно не смогли получить наше уважение, его надо заслужить, и еще лучше – заработать демонстрацией, что вы можете это починить недорого, лучше бесплатно, еще лучше бесплатно научить тех, кто остался.
Сын маминой подруги говорит «окей», и уходит.
Аудит Еотовой, проведенной в тот же вечер сыном маминой подруги, сообщает, что как было – не будет. Надо переделывать все, надо срочно идти получать нормальную профессию, потому что вебкам для Еотовой закрыт по возрасту. Но это сложно, надо учиться (вебкаму, кстати, тоже). Еотова говорит – вас просили дать денег, а не советы давать. До вас тут были такие же, тоже хотели бесплатной любви, а ее надо заслужить, и еще лучше – заработать демонстрацией серьезности намерений.
Сын маминой подруги говорит «окей», и уходит.
Бизнес может разово решить задачу в виде нового сервера, задорого и до «как пойдет».
Проблему бизнеса это не исправит - надо менять схемы, надо менять поведение команды и методы и процессы руководителя, который это натворил.
И бизнес (разбалованный легким решением) начинает искать серебряную пулю - давайте купим / поставим магию, чтобы она заранее говорила, что сейчас все сломается. И ещё бы сама чинила. Такая магия есть. Только к ней нужен колдун, чтобы правильно сварить зелье, и много чего.
Еотова может разово решить задачу «нет денег», но это так себе решение. Проблему Еотовой это не исправит - надо менять поведение, надо найти в себе смелость признать, откуда это.
Еотова начинает искать краткие курсы по ойти, там же ни за что платят денег - надо всего то полгода поучиться и сразу седло большое, ковер и телевизор, ну и, конечно, слабовольные ойтишники при деньгах, так и ждут Еотову.
У бизнеса возникает проблема - не хотят люди в это лезть и все. Сразу говорят - это не легаси, это спички и желуди, нет смысла это чинить, надо все строить с ноля, и рефакторинг. Долго дорого.
Бизнес плачет в прессе – айтишники зажрались, не идут к нам.
У Еотовой начинается страдание. Мужик пошел не тот, не добивается, вместо этого говорит - мадам, отношения это как бы про борщи, и про «оба слушают в обе стороны», а не то, что ваш прошлый муж вас в попу целовал, кстати а где он .
Может ли бизнес исправить ситуацию? Да. Для этого надо бизнесу заказывать аудит и делать программу 'что не так'. Признать, что нет быстрого тактического решения.
Может ли Еотова войти в ИТ? Да. Для этого Еотовой надо говорить с людьми, и спрашивать – я хочу в ИТ, что не так с моим учебным планом. Признать, что нет быстрого тактического решения.
Будет ли это делать бизнес? Может да, может нет. Часть бизнеса до сих пор верит, что работать у них – большая честь, и гораздо лучше и проще иметь дело пусть не с умным, но контролируемым ИТ специалистом. Даже если он снова построит дешево и плохо.
Будет ли это делать Еотова? Может да, может нет. Еотова до сих пор верит, что встречаться с ней в ее 35 – большая честь, и что ей гораздо лучше и проще иметь дело пусть не с умным, но контролируемым мужем. Даже если он сделает Еотовой второго ребенка, и пропадет.
Что делать в такой ситуации зажравшемуся айтишнику, нужно ли:
А) Доказывать региональному бизнесу, что он может это сделать, и терять год на получение опыта с окаменевшим легаси, только чтобы доказать бизнесу .. чего-то ?
Или выбирать такой стек и набор практик, за который платят больше, а проблем с ним в разы меньше? Временами, конечно, скучая по студенческим годам, коду на дельфи?
Б) Доказывать Еотовой, что можно спокойно жить лучше, и терять год на то, чтобы убедиться в том, что Еотова как выбирала «я всегда права», так и выбирает?
Или рассматривать поле более дорогих и более комплексных решений, например – поехать в Таиланд, если вы понимаете, о чем я. Временами, конечно, скучая по студенческим годам, и молодой Еотовой?
Для ЛЛ: ESXi – не linux, но есть нюансы
Продолжаем неторопливо вести отбор кандидатов из РФ, присутствую иногда на интервью, как Non-sogreedychatGPT, слушаю, что рассказывают кандидаты.
Надо заметить, что уровень кандидатов из РФ продолжает движение в сторону давно забытых терминов из методов расчета косинуса фи. Ну, вы знаете что там (или нет). Недорогие методы улучшения резюме – в стиле «доверьтесь нам, мы знаем, как писать», в итоге работают не в пользу кандидатов, особенно если экспертные эксперты пишут в резюме кандидатов «Unix Mint» и Esx VCentre.
Если кто-то забыл, или не знал:
Для Unix все началось с The Bell System . Да, тот самый Александр Белл (Alexander Graham Bell), про которого слышал что-то примерно 1 из 10 человек.
Bell System прикупила Western Electric Company, из Western Electric Company выделилась Bell Telephone Laboratories, в которой три Отца - Деннис Ритчи (Dennis MacAlistair Ritchie, 9.9.1941 – 12.10.2011), Кен Томпсон (Kenneth Lane Thompson 4.2.1943 –жив), Брайан Керниган (Brian Wilson Kernighan 30.01.1942 – жив) и сделали первый Unix. Вместе с The C Programming Language, Кен Томпсон еще и в Go отметился. Разумеется, надо вспомнить и Джо Осанну (Joe Ossanna), и Малкольма Дугласа Макилроя (Malcolm Douglas McIlroy).
Наследники и многочисленные потомки того, первого, Unix до сих пор живы, здоровы. Кто-то уже умер (Berkeley Unix), но успел породить наследников – OpenBSD и Darwin.
Для GNU\Linux все началось в 1983 году, когда Ричард Столман (Richard Stallman ) стал продвигать идею - GNU - "GNU's Not Unix!" Предполагалось, что проект GNU будет весь свободный, и без всякого кода из Unix, и с ядром GNU Hurd. Что было дальше, написано и без меня – в статье Linux kernel.
Для ESXi все началось в 2001, когда на рынок вышел ESX (тогда без i), изначально запускавший, в том числе, ядро Linux как приложение для управления остальными виртуальными машинами (и прочее по мелочи).
Если быть чуть точнее, то:
VMware 1.0 – 15.05.1999
VMware GSX Server 1.0 – что то в 2001
VMware ESX 1.0 Server – 23.03.2001.
GSX Server 2.0 – 15.07.2002
Почитать про ностальгию, и не только почитать – можно тут
Такая коммерциализация чистых идей вызывала определенное недовольство, одновременно VMware ESX стал превращаться в VMware ESXi – и в итоге превратился, первый релиз (VMware ESXi 3.5 First Public Release) случился ровно на новый год 31 -12 – 2007, билд 67921 (VMware ESXi Release and Build Number History https://www.virten.net/vmware/esxi-release-build-number-history/#esxi3.5 )
Все бы хорошо, но 4 августа 2006 Кристофер Хелвиг (Christopher Helwig) решил, что VMware не соблюдает GPL:
Until you stop violating our copyrights with the VMWare ESX support nothing is going to be supported. So could you please stop abusing the Linux code illegally in your project so I don't have to sue you, or at least piss off and don't expect us to support you in violating our copyrights. I know this isn't you fault, but please get the VMware/EMC legal department to fix it up first.
https://lkml.org/lkml/2006/8/4/112
В 2011 году Conservancy решила до получила отчет о нарушениях GPL в ESXi BusyBox. Попытки мирно решить вопрос в стиле «все не отдадим, но обсудим» - закончились в 2014, в вольном пересказе сайта, рекомендациями самим почитать GPL.
Then, in early 2014, VMware's outside legal counsel in the USA finally took a clear and hard line with Conservancy stating that they would not comply with the GPL on Linux and argued (in our view, incorrectly) that they were already in compliance.
Frequently Asked Questions about Christoph Hellwig's VMware Lawsuit
5 марта 2015 года Conservancy подала в суд на VMware в Германии, с текстом «дайте денег» - Conservancy Announces Funding for GPL Compliance Lawsuit
Темой по-прежнему был BusyBox, но авторы иска пытались показать, что часть компонентов прямо использует куски кода от Christoph Hellwig – от
scsi_setup_command_freelist (14.8148% кода) до
scsi_remove_single_device (99.0566% кода) -
Contribution and Similarity Analysis of Christoph Hellwig's Linux Code as found in VMware ESXi 5.5
В итоге все оказалось еще сложнее, потому что свелось к выяснению, можно ли взять vmkLinux (опубликованный под GPLv2), и сделать магию, цитата
A lot of Linux code has been extracted into vmkLinux; this is a shim between Linux drivers and the vmkapi interface. The intent here is to provide an environment where almost unmodified Linux drivers can interface to the proprietary vmkernel. This means vendors don't have to write two drivers, they can re-use their Linux ones. Of course, large parts of various Linux sub-systems' API are embedded in here. But the intent is that this code is modified to communicate to the vmkernel via the exposed vmkapi layer. It is conceivable that you could write a vmkWindows or vmkOpenBSD and essentially provide a shim-wrapper for drivers from other operating systems too.
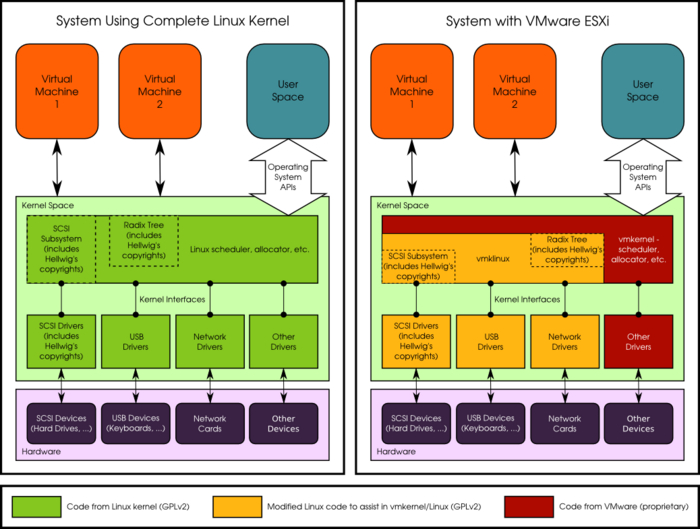
Или нельзя вот так вжух и магия.
VMware считала что можно
Почти одновременно с этим в суде шло дело Патрика МакХарди (Patrick McHardy) – начавшееся в 2016 (The Importance of Following Community-Oriented Principles in GPL Enforcement Work), и закончившееся в 2018 отзывом дела - с оплатой Патриком судебных издержек (Бывший лидер Netfilter прекратил дело о нарушении GPL и выплатит судебные издержки)
К 2020 году Патрик так всех достал, что в суд подали уже на него. (Разработчики Netfilter отстояли коллективное принятие решений при нарушении GPL)
Но, сейчас не про него.
7 августа 2016 немецкий суд решил, что Хелвиг не прав.
9 августа 2016 было объявлено про подачу апелляции.
Все это сопровождалось заявлениями типа «еще не поздно покаяться» - «VMware could still choose to do the right thing here, admit that they did not meet the terms of the GPL and acquiesce to Christoph's request.» Appeal Moving Forward in GPL Compliance Suit Against VMware
28 февраля 2019 суды закончились, суд Германии решил, что Хелвиг не прав:
VMware is pleased with the February 28, 2019 decision of the German appellate court in Hamburg to dismiss Mr. Hellwig’s appeal and let stand the regional court’s decision to dismiss Mr. Hellwig’s lawsuit.
VMware’s Update to Mr. Hellwig’s Legal Proceedings
VMware Linux lawsuit moves closer to a resolution
VMware Announces Plans to Remove Non-complying Code, Hellwig Decides Not to Appeal
Апелляционный суд встал на сторону VMware в деле о нарушении GPL
Что в итоге?
Сначала, еще в 2017 году, начиная с ESXi 6.0 6921384, VMware заблокировали поддержку Microsoft Legacy Network Adapter, точнее Net-tulip - community драйвер DECchip 21140 Ethernet. Билд 5572656 с ним работает, билд 6921384 – уже нет. Стенды (nested) на Hyper-v стали бесполезны, да и в KVM приходится ставить в настройках:
--network network:default,model=vmxnet3
Deploying a nested version of VMware ESXi 7.0 on KVM ,
Running nested VMware ESXi 8.0 host under KVM hypervisor
С версии 7.0 (2020/04/02 – 15843807) из ESXi выкинули поддержку старых драйверов «от всего», причем, зачастую, именно Linux драйверов. Вой стоял до небес, как же так, дисковому контроллеру, серверам и сети всего по 10 лет, производитель не хочет их поддерживать, и теперь никак старые Linux драйвера не внедрить, проклятые VMware, почему они не возьмут и сами не напишут драйвер. Не понятно, чего орали – вот суд, вот его поддержка. Хотя, все уже сказано тут.
Про Community Network Driver for ESXi, читать, конечно, никто не собирался, как и про VMware Flings.

К чему пришли
VMware by Broadcom – по прежнему отличный (кроме цены, но, если ее платит организация, и экономия не идет на вашу премию – то какая разница?) выбор для почти всего
VMware Workstation 17.6 Pro – бесплатен для некоммерческого использования.
ESXi – отлично ставится даже на ASUS NUC 14 , по прежнему может (хотя это и не рекомендовано) загружаться с USB флешки, хотите дома Intel Neural Processing Unit (NPU) – пожалуйста.
Хотите гипервизор и управление «чтобы работали из коробки и не требовали System Center Virtual Machine Manager и не ломались от того, что производитель закрыл очередной баг в гипервизоре» - вот, пожалуйста, vCenter.
Хотите нормально документированный и уже почти не взрывающийся СХД – есть два варианта vSAN (OSA\ESA), только не нанимайте на его запуск – не умеющих и не желающих читать vSAN HCL «специалистов с дипломом», которые принесут вам Samsung 870 EVO на кеш и домашние SATA диски на хранение.
Не желающих читать, к сожалению, очень много.
Заканчивается всегда одинаково, исключений нет – система ломается, «специалисты по объявлению» начинают ее чинить перезагрузкой и перестановкой системы – система умирает окончательно от расхождения метаданных. Все.
Хотите стильных контейнеров – есть tanzu.
Хотите сети – есть NSX
Хотите в облако – пожалуйста - Azure, AWS.
Хотите сами быть провайдером – главное, готовьте много денег. Очень, очень много. Зато оно работает, причем пока что в РФ не видно, чтобы было чем его импортозаместить так, чтобы работало.
Всякое есть, и что очень важно – это «всякое»:
- документированное (если не лениться читать),
- с большим англоязычным комьюнити, конференциями, бесплатной учебой онлайн,
- не очень часто ломающееся само по себе. Хотя и бывало, и от новых патчей никто не застрахован.
Минусы? Дорого.
Чтобы «нормально» работало, нужно «нормальное сертифицированное железо».
Чтобы «нормально» работало, нужна подписка на поддержку. Это не значит, что оно постоянно ломается, это значит, что сложные задачи проще делегировать профессионалам. Главное, пройти первого босса – Кумара.
Чтобы «нормально» работало, нужно смотреть, кого нанимаете. Сломать кривыми руками можно что угодно, если долго стараться.
Альтернативы?
Конечно есть! Есть отличная книга про альтернативы, имя автора слишком известно, чтобы его называть:
Все моральные эффекты происходят от физических причин, с которыми они связаны самым абсолютным образом: барабанная палочка бьет по туго натянутой коже, и удару отвечает звук – если нет физической причины, то есть нет столкновения, значит, не будет и эффекта, не будет звука. Особенно нашего организма, нервные флюиды, зависящие от природы атомов, которые мы поглощаем, от видов или количества азотистых частиц, содержащихся в нашей пище, от нашего настроения и от тысячи прочих внешних причин - это и есть то, что подвигает человека на преступления или на добродетельные дела и зачастую, в течение одного дня, и на то и на другое. Это и есть причина порочного или добродетельного деяния, которую можно сравнить с ударом в барабан, а сотня луидоров, украденная из кармана ближнего, или та же сотня, отданная нуждающемуся в виде подарка, - это эффект удара или полученный звук. Как мы реагируем на эти эффекты, вызванные первичными причинами? Можно ли ударить в барабан так, чтобы не было ни одного звука? И разве можно избежать этих отзвуков, если и они сами, и удар, их вызвавший, - всего лишь следствие явлений, не подвластных нам, настолько далеких от нас и настолько не зависящих от нашего собственного организма и образа мыслей? Поэтому очень глупо и неестественно поступает человек, который не делает того, что ему хочется, а сделав это, глубоко раскаивается. И чувство вины и угрызения совести являются не чем иным, как малодушием, которое следует не поощрять, а напротив, искоренять в себе всеми силами и преодолевать посредством здравомыслия, разума и привычек. Разве помогут сомнения, когда молоко уже скисло? Нет. Посему надо утешиться и понять, что угрызения совести не сделают поступок менее злодейским, ибо они всегда появляются после поступка и очень редко предотвращают его повторение. Истинная мудрость заключается вовсе не в подавлении своих порочных наклонностей, потому что с практической точки зрения они составляют единственное счастье, дарованное нам в этом мире, и поступать таким образом - значит стать собственным своим палачом. Самое верное и разумное - полностью отдаться пороку, практиковать его в самых высших проявлениях, но при этом обезопасить себя от возможных неожиданностей и опасностей.
Если вы дочитали
Альтернативы всем продуктам выше, и не только им, конечно, есть. Некоторые из них работают даже лучше, особенно в умелых руках. Некоторые же наоборот, имеют привычку ломаться сами собой, и в ходе 1-2 итераций «сломали – починили» начинает возникать вопрос, сколько же альтернативная инсталляция стоит на самом деле. Сколько для нее нужно железа, сколько альтернативная инсталляция потребляет электричества, в том числе на работу кондиционеров. Сколько людей, и какой квалификации (и стоимости) нужны люди. Какая надежность требуется, в часах простоя в год. Для разных условий, требований и организаций выводы могут быть совершенно разными. Причем, как в случае Росреестра - 2018, выводы могут быть совершенно внезапными. Но выводы выводами, а чему-то это кого-то научило? Вовсе нет.
Научили ли кого-то, например - Drweb, случаи МТС, СДЭК и КБ Радуга? Нет.
С мест сообщают: молодежь в РФ УЖЕ НЕ ТА:
Более того, у молодых людей сейчас сформировалось болезненное отношение к нарушению личностных границ. Поэтому замечание по работе воспринимается как наезд на личностные границы. Иными словами, они путают, где эти границы — важная и серьезная вещь, а где право начальника быть недовольным выполненной работой. Отчасти это связано с их нарциссическим образом жизни и времяпрепровождением», — сказал психолог.
Это он еще не в курсе, что в советское время по телевизору и в кино показывали аниме, Летающий корабль-призрак и Босоногий Ген, так союз и развалили.
Что еще слышно
В российских HR телеграм каналах (я там не сижу, но особо яркое мнение иногда читаю) активно обсуждается увольнение толи 100, толи 100500 разработчиков, менеджеров и не понятно кого, сами знаете откуда, но не из доктор веб.
HR в радости – наконец то на рынке труда будет сломлен тренд от этих, ужасно жадных, и не желающих работать на барена, чертовых айтишников. Вот они то сейчас внизу поползают, а мы выбирать будем.
Это очень забавно, если подумать. Я пока не очень понимаю, как работает именно международный найм, но в российском HR сообществе последние лет, минимум, 10, может и 15 – присутствует попытка убедить друг друга, что никаких проблем с наймом нет, проблема в айтишниках.
Кто то слишком много кушать!

Если пойти чуть глубже, то HR правы
– если бизнес и руководство поощряют такую позицию, и
- если бизнес и руководство не заинтересовано в получении реальной картины,
то у бизнеса все хорошо. Пока дешевый низкокачественный труд (он же спортивное администрирование – когда дешевле решить задачу массовым ручным трудом, а не автоматизацией) присутствует на рынке, ситуация не изменится.
Приключение пакетишки
Для ЛЛ: сложности отладки производительности дисковых подсистем в среде виртуализации.
Каждый вечер, когда солнце прячется за верхушки сосен, на небе зажигаются звезды, а где-то в лесу неподалеку начинает ухать сова, которую мы уже два месяца не можем поймать, чтобы сварить из нее суп, - так вот: каждый раз, когда на нашу свалку опускается темнота, вся детвора собирается вокруг ржавого чайника в пустой нефтяной цистерне на западной окраине, чтобы попить кипятка, съесть по кусочку сахара и послушать сказку на ночь.
(проследовать за кроликом)
Зашел в нашем колхозном клубе разговор о том, как в конфету "подушечку" варенье попадает, и постепенно перешли на то, как данные из приложения попадают на диск, и где можно на граблях попрыгать, и на взрослых, и на детских.
Итак, у нас есть «данные».
Если речь заходит о том, что надо быстро и много работать с хоть сколько-то большими объемами данных, то обычно у производителя есть рекомендации «как лучше организовать дисковое пространство». Обычно. Но не всегда.
Общеизвестно, что:
Microsoft SQL работает с страницами по 8 кб, а сохраняет данные экстентами (extent) по 8 страниц – 64 Кб, и рекомендации для MS SQL - cluster (NTFS allocation) size в 64 Кб. (1) . Все просто, все понятно, и.
И даже есть статья Reading Pages / cчитывание страниц про Read-Ahead (Упреждающее чтение) экстентами по, вроде как, 64к, хотя прямо на странице этого не указано.
Для Oracle все тоже как-то описано – есть статья Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap) Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap)
Для PostgreSQL на Windows пишут просто: и так сойдет!- The default allocation unit size (4K) for NTFS filesystems works well with PostgreSQL.

Что там рекомендуют в проприетарном Postgrepro?
Да ничего, вместо документации и тестов – обсуждение на тему 8Kb or 4Kb ext4 filesystem page size из 2019 года.
Ладно, для простоты (более полная и занудная версия про размеры страниц в памяти будет на Пикабу) будем считать (хотя это и не всегда верно), что из приложения в Linux вылетит пакет размером 4к в сторону диска.
И, в первую очередь пакет попадет в буфер ОС, оттуда отправится в очереди, потом в драйвер диска, затем операция будет перехвачена гипервизором, и перенаправлена туда, куда гипервизор посчитает нужным. Если вы работаете не в среде виртуализации, а в контейнерах, то там все еще интереснее.
Настоящие проблемы только начинаются
Пропустим ту часть, где Linux отвечает приложению, что информация точно записана, инфа сотка, если вы понимаете, о чем я.
Дальше у пакета, в зависимости от настроек гипервизора, есть варианты, например:
Отправиться в путешествие по сети здорового человека блоками по 2112 байт.
Правда если вы альтернативно одаренны, и не следите за ретрансмитами, отброшенными пакетами, не настроили ano и mpio, то вы на ровном месте, на бильярдном столе яму найдете. И в ней утонете. Или наоборот, медленно высохнете (Slow drain in Fibre Channel: Better solutions in sight )
Отправиться в путешествие по сети бедного человека tcp блоками – в iSCSI или в NFS. Нарезка «по питерски» на блоки от 1500 до 9000 – на ваш вкус.
Отправиться в путешествие по сети нормального человека – в iSCSI или в NFS, но в Ge UDPwagen, со всеми остановками – DCB, lossless ethernet, congestion control.
И, самый неприятный вариант – отправиться на локальные диски, потому что по бедности ничего другого нет, и это самый плохой вариант. То есть, почти самый плохой, но есть нюансы.
Почему этот вариант плох?
Потому что, в случае проблем в стеке богатого человека, вы можете увидеть задержки в гостевой системе, задержки в системе гипервизора, посмотреть QAVG, KAVG, DAVG и сказать – проблемы где-то тут. Конечно, иногда приходится и в vsish ходить, и про Disk.SchedNumReqOutstanding знать, а то, что еще хуже, читать по не русски всякие документы типа vSAN Space Efficiency Technologies
В случае проблем в стеке не такого богатого человека – вы можете просто взять и включить:
Get-VM | Format-List Name,ResourceMeteringEnabled
Enable-VMResourceMetering -VMName NameOfVM
Get-StorageQoSFlow -CimSession ClusterName | Sort-Object InitiatorIOPS -Descending | select -First 5
Что делать в остальных случаях, я как-то не очень понимаю, потому что load average покажет что угодно, кроме того что мне интересно, а iotop и sysstat хороши, но показывают не то, что мне надо. Хотя - и так сойдет, главное не забывать валить вину на кого угодно.
Но и это не самая большая проблема, потому что на этом месте в игру вступает
БОЛЬШОЕ ФИНАЛЬНОЕ КРОИЛОВО
И, наконец, данные начинают приземляться на диски
Тут кто-то вспомнит выравнивание разделов (partition alignment), но это параметр, про который стоит помнить, и иногда проверять.
Самая простая часть кроилова, это IO amplification. С ним все просто, пришел пакет в 512 байт на 4к разметку – пришлось делать много операций. Открываете статью Cluster size recommendations for ReFS and NTFS из списка литературы, читаете. Потом возвращаетесь к началу этой заметки, и делаете ААА, вот про что это было.
Особенно больно будет, если у вас на хосте развернута любое программно-определяемое хранилище – хоть vSAN, хоть storage space, хоть storage space direct.
Там вы еще полной ложкой поедите не только IO amplification, но и Storage Spaces Direct Disk Write-Caching Policy, CSV BlockCache, и на сладкое - alternate data streams, вместе с Read-Modify-Write
Just a dose that'll make you wish you were born a woman
Более сложная часть шоу начинается с «мы купили какой-то SSD, поставили его в какой-то raid-контроллер, оно поработало, а потом не работает, мы купили SATA NVME и оно тоже не работает на те деньги, которые мы за него отдали, караул помогите ограбили».
Лучше этого шоу – только то самое, на Walking Street, ну вы знаете.
После такой фразы можно только посочувствовать, но пионер, то есть внешний подрядчик, должен быть вежливым, вне зависимости от того, что бабка, то есть заказчик, говорит*.
Сначала вспомним термины.
Solid-State Drive, SSD. Это диск. Может быть:
NAND (NOT-AND gate)) – SLC, MLC, TLC,
3D NAND (Vertical NAND (V-NAND) / 3D NAND ) - 3D MLC NAND, 3D TLC NAND, а там и QLC недалеко - QLC V-NAND. Какой там тип level cell, не так важно на данном этапе.
3D XPoint. Ох, как он был хорош, как мощны были его данные. Но, все. Optane больше нет, и не будет.
Compute Express Link (CXL) – не видел пока.
Non-Volatile Memory Express (NVMe) – это протокол, но есть NVMe U.2 и есть NVMe U.3
Serial Attached SCSI (SAS) – тоже протокол
SFF-8643 (Mini SAS HD) , SFF-8654 (x8 SlimSAS) , SFF-8639 –разъемы.
Universal Backplane Management - одна из возможностей, или функций, как хотите называйте, у контроллеров Broadcom 9500 (и не только).
Вспомнили?
Сходу суть: При включении SSD через RAID контроллер, и, особенно, через старый RAID контроллер, с его тормозной маленькой сморщенной памятью и усохшей батареей, и последующих тормозах, дело не только в фоновых операциях, всех этих Garbage Collection и TRIM, и даже не в балансировке нагрузки, а в том что контроллеры, года примерно из 2015-2018, вообще работают с новыми SSD отвратительно, и еще хуже, если это новый, но дешевый SSD, видевший некоторое Г.
Рекомендации типа «если у вас в контроллере нет JBOD, то просто сделайте RAID 0 на все» - есть, но их последствия, прямые и косвенные, описаны в статье Using TRIM and DISCARD with SSDs attached to RAID controllers (смотрите список литературы).
Контроллеры tri-mode – не позволяют получить из SSD NVME всю его скорость, а скорее привносят проблемы.
Больше проблем приносит, разве что, Intel VROC.
И, что самое интересное
У SSD есть свой микроконтроллер, в котором есть своя прошивка. Получить от вендора SSD, того же Micron, список исправлений между версиями – наверное, можно. Но на официальном сайте есть обновленный микрокод (прошивка), и только микрокод. Никаких релиз нот с описанием. Просто прошивайтесь.
А на какую, интересно, версию прошиваться, если производитель гипервизора у себя в списке совместимости указывает версию, которой у вендора на сайте нет?
Итого
Отладка «что так медленно-то» может начаться со стороны DBA, и в итоге оказаться где-то на уровне обновления микрокода RAID контроллера, или на уровне обновления прошивки диска.
Пока SCSI команды и нагрузка доедут до физических дисков – с ними чего только не происходит, и проблемы могут быть на любом уровне. Например, с уровнем сигнала (мощности) на оптическом SFP по пути.
Хуже всего сценарий, когда из соображений «кроилово» и «нечего читать – сбегали и купили Samsung 870 EVO , ведь дома на нем ИГОРЫ ОТЛИЧНО РАБОТАЮТ» . Иногда из соображений кроилова покупается продукт «для дома», рассчитанный на работу 4 часа в день при температуре +25, причем настроенный на задачу «загрузить игру – сохранить игру», а не 24*7 обрабатывать потоки данных при температуре +35.
ЗАПОМНИТЕ, КРОИЛОВО ВЕДЕТ К ПОПАДАЛОВУ.
Если вы собрали систему на домашних компонентах, она будет работать до первого падения какого-то из компонентов, потом превратится в тыкву. Как и данные. И их не вытащить. Никак не вытащить. Совсем никак.
Будьте готовы.
Хотя нет. Лучше не будьте. Когда все сломается, то:
- наймите на восстановление данных пару идиотов,
-один из которых эффективный менеджер,
- который не умеет читать вообще, зато может пушить первого
- второй думает, что он умеет читать, думает что умеет думать, и лучше знает, что ему делать (Эффект Даннинга — Крюгера), вместо того чтобы: прочитать, что ему пишут, записать что понял, спросить правильно ли он понял, переписать, и сделать хорошо. А плохо не сделать.
Эта парочка качественно и надежно похоронит то, что еще оставалось.
А уж если они привлекут к решению проблем AI, не пытаясь понять, что AI может насоветовать, то будет просто караул
Список литературы
Set the NTFS allocation unit size to 64 KB
SQL Server 2005 Best Practices Article
Disk Partition Alignment Best Practices for SQL 2008 Server
Improve Performance as Part of a SQL Server Install (2014)
Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap)
Oracle on VMware Collateral – One Stop Shop
2022 SQL Server on Linux: Scatter/Gather == Vectored I/O
2024 Performance best practices and configuration guidelines for SQL Server on Linux
The default allocation unit size (4K) for NTFS filesystems works well with PostgreSQL: PostgreSQL on FlashArray Implementation and Best Practices
Block Size on MSSQL on Linux
(тут мне стало лень оформлять)
Using esxtop to identify storage performance issues for ESXi (multiple versions)
https://knowledge.broadcom.com/external/article/344099/using-esxtop-to-identify-storage-perform.html
What is the latency stat QAVG?
https://www.codyhosterman.com/2018/03/what-is-the-latency-stat-qavg/
Troubleshooting Storage Performance in vSphere – Part 1 – The Basics
https://blogs.vmware.com/vsphere/2012/05/troubleshooting-storage-performance-in-vsphere-part-1-the-basics.html
Анализ производительности ВМ в VMware vSphere. Часть 3: Storage
https://habr.com/ru/companies/rt-dc/articles/461127/
Get Hyper-V VM IOPS statistics
https://pyrolaptop.co.uk/2017/07/07/get-hyper-v-vm-iops-statistics/
Tips and Tools for Microsoft Hyper-V Monitoring
https://www.nakivo.com/blog/tips-and-tools-for-microsoft-hyp...
Identifying storage intensive VMs in Hyper-V 2016 Clusters
https://bcthomas.com/2016/10/identifying-storage-intensive-v...
How to Monitor Disk IO in a Linux System
https://www.baeldung.com/linux/monitor-disk-io
What is VMware vsish?
https://williamlam.com/2010/08/what-is-vmware-vsish.html
vSphere ESXi 4.1 - Complete vsish configurations (771 Total)
https://s3.amazonaws.com/virtuallyghetto-download/complete_vsish_config.html
Advanced Disk Settings для хостов VMware ESX / ESXi.
https://vm-guru.com/news/vmware-esx-esxi-advanced-settings
Cluster size recommendations for ReFS and NTFS
https://techcommunity.microsoft.com/t5/storage-at-microsoft/cluster-size-recommendations-for-refs-and-ntfs/ba-p/425960
Why Intel killed its Optane memory business
https://www.theregister.com/2022/07/29/intel_optane_memory_dead/
How CXL may change the datacenter as we know it
https://www.theregister.com/2022/05/16/cxl_datacenter_memory/
Кабели для подключения NVMe к контроллерам Broadcom
https://www.truesystem.ru/solutions/khranenie_danny/424809/
Тестирование NVMe SSD Kioxia CD6 и CM6
https://www.truesystem.ru/review/424664/
Что нужно знать о стандарте U.3
https://www.nix.ru/computer_hardware_news/hardware_news_viewer.html?id=211282
Broadcom® 95xx PCIe 4.0 MegaRAID™ and HBA Tri-Mode Storage Adapters
https://serverflow.ru/upload/iblock/583/ehhvql2l0gn06v02227c...
Понимание SSD-технологии: NVMe, SATA, M.2
https://www.kingston.com/ru/ssd/what-is-nvme-ssd-technology
NVMe и SATA: в чем разница?
https://www.kingston.com/ru/blog/pc-performance/nvme-vs-sata
vSAN — Выбор SSD и контроллеров
https://vgolovatyuk.ru/vsan-controller/
FTL Design for TRIM Command
https://vgolovatyuk.ru/wp-content/uploads/2019/07/trim_ftl.pdf
Using TRIM and DISCARD with SSDs attached to RAID controllers
https://www.redhat.com/sysadmin/trim-discard-ssds
SSD TRIM command support and Adaptec RAID adapters
https://ask.adaptec.com/app/answers/detail/a_id/16994
New API allows apps to send "TRIM and Unmap" hints to storage media
https://learn.microsoft.com/en-us/windows/win32/w8cookbook/new-api-allows-apps-to-send--trim-and-unmap--hints-to-storage-media?redirectedfrom=MSDN
TRIM mdadm - How to set up SSD raid and TRIM support?
https://askubuntu.com/questions/264625/how-to-set-up-ssd-raid-and-trim-support
vSAN support of NVMe devices behind tri-mode controllers
https://knowledge.broadcom.com/external/article?legacyId=88722
Memory usage on Azure Stack HCI/Storage Spaces Direct
https://jtpedersen.com/2020/10/memory-usage-on-azure-stack-hci-storage-spaces-direct/
Deploy Storage Spaces Direct on Windows Server
https://learn.microsoft.com/en-us/windows-server/storage/storage-spaces/deploy-storage-spaces-direct
Microsoft Storage Spaces Direct (S2D) Deployment Guide
https://lenovopress.lenovo.com/lp0064.pdf
How to Enable CSV Cache
https://techcommunity.microsoft.com/t5/failover-clustering/how-to-enable-csv-cache/ba-p/371854
CSV block cache causes poor performance of virtual machines on Windows Server 2012
https://support.microsoft.com/sl-si/topic/csv-block-cache-causes-poor-performance-of-virtual-machines-on-windows-server-2012-88b35988-a964-30ba-98d9-9b89d0a39d35
Mirror accelerated parity (MAP) - https://learn.microsoft.com/en-us/windows-server/storage/refs/mirror-accelerated-parity
ReFS Supported Deployment Scenarios Updated
https://blog.workinghardinit.work/2018/04/17/refs-supported-deployment-scenarios-updated/
ReFS Accelerated VHDX Operations
https://aidanfinn.com/?p=18840
dedicated journal disk – точнее, старая статья Storage Spaces Performance Analysis – Part 1 https://noobient.com/2015/09/18/storage-spaces-performance-analysis-part-1/
Storage Innovations in Windows Server 2022
https://techcommunity.microsoft.com/t5/storage-at-microsoft/storage-innovations-in-windows-server-2022/ba-p/2714214
Reverse engineering of ReFS
https://www.sciencedirect.com/science/article/pii/S1742287619301252
Forensic Analysis of the Resilient File System (ReFS) Version 3.4
https://d-nb.info/1201551625/34
vSAN Space Efficiency Technologies
https://core.vmware.com/resource/vsan-space-efficiency-techn...
Импортозамещение: Что же могло пойти не так. Обзор – от FPGA до сайтов знакомств
Читал статью с воодушевляющим лозунгом
«С внедрением государственных инициатив у российских разработчиков появляется уверенность, что к 2030 году более 70–80% компаний переориентируются на использование локального оборудования»
и подумал – в самом деле, что же может пойти не так? Отличный же план, надежный, как швейцарские часы.
Для ЛЛ : капитанство унылое
Часть 1. Российское «железо»
Почему-то авторы подобных статей зачастую считают, что технологии не могут быть утрачены. Что тут сказать? В СССР были технологии, позволившие осуществить посадку аппаратов на Луну, Марс и даже Венеру, перемещение луноходов 1 и 2 по Луне, возврат лунного грунта. Были.
Аналогично, на Микроне и схожих производствах были, или обещали быть, отдельные элементы производства, или отдельные производства элементов по 250-180-130 нм технологии, и речь шла про переход на 90-65.
2022, цитата:
На форуме «Микроэлектроника-2022» резиденты ОЭЗ "Технополис Москва" АО «Микрон» и ООО «НМ-Тех» подписали соглашение о сотрудничестве для постановки технологий и запуска производства на мощностях НМ-Тех.
Микрон окажет содействие в освоении таких продуктов как:
двухинтерфейсная СБИС для применения в платежных картах «МИР»;
интегральные микросхемы для паспортно-визовых документов с биометрией и для полисов ОМС.
Ну и как, два года прошло? Освоили ?
Теперь же, как пример успешного успеха, подается совместное предприятие с Планаром на или производство, или разработку, или локализацию, или 250, или 300, или 350 нм степперов, описанное в прессе в стиле «Будет вообще отлично, а как и когда – не ваше дело, это лекция для колхозников».
Можно посмотреть и на интересные факты, например, из чего сделан ускоритель нейронных сетей Mustang-F100-A10 от Ниешанц-автоматика
Или спросить, куда пропал FPGA при переходе от Континент 3.9 IPC-3000FC к линейке Континент 4.
Проект вроде есть, одним из проектов, над которым работает наш отдел "Аппаратного обеспечения Континент", является модуль (плата расширения) криптоускорителя на базе ПЛИС Xilinx Kintex Ultrascale+. – но на него никого не ищут, а на схожую вакансию в Москве - искали кого-то на зарплату курьера (Инженер-разработчик ПЛИС (RTL/FPGA) от 173 000 ₽ до вычета налогов) .
Kintex™ 7 FPGA – c 14 февраля 2022 называется AMD Kintex. Техпроцесс - 28нм.
Usergate схож - Обещали год назад выкатить вот вот FPGA, yо вот беда – в блоге UG на хабре предпоследняя статья 21 авг 2023 в 10:34, последняя - 9 авг в 12:00 .
1 статья в год. И все.
Можно сравнить заявленные характеристики Континентов и УГ с простым Fortinet FortiGate 6500F:
IPS Throughput 2 170 Gbp
NGFW Throughput 2, 4 150 Gbps
Threat Protection Throughput 2, 5 100 Gbps
Не говоря о чем-то сложнее, типа Palo Alto PA-7050
В чем проблема с FPGA и нанометрами, спросите вы, ведь у вашего дедушки был тот самый Волк, ловящий яйца (Электроника 24-01 «Ну, погоди!») – то есть Nintendo EG-26 Egg серии Game & Watch.
Да нет никакой проблемы, все разобрано еще 2 года назад.
Точно так же нет никаких проблем ни у гражданских связистов, ни у военных «вообще», а в докладе Royal United Services Institute (RUSI) (Silicon Lifeline: Western Electronics at the Heart of Russia's War Machine / Кремниевый спасательный круг: западная электроника в сердце российской военной машины) – клевета, и вот это все.
Это всё, что я могу сказать о войне во Вьетнаме и про приятные мечты о российском железе.
Часть 2. Цена перехода в первом приближении
В первом приближении может показаться, что переход на импортозамещенный сервер – это просто и легко. Шварценеггер не может, а я смогу, и это действительно так, если у вас 1 (один) сервер. И даже 2(два). И даже по 2 (два) процессора в каждом. На такой сервер даже можно поставить Linux с KVM.И он даже будет работать.
Чему там не работать?
Процессор Intel Xeon, материнская плата с разводкой дорожек (и слоев) от китайского вендора 2-3 эшелона, на которую в РФ кое-как выполнили поверхностный монтаж китайских же силовых элементов, на китайском станке, китайским припоем. Сделано у нас(С).
Картон для коробок точно из РФ. Насчет картоноделательной машины и красок я уже не уверен.
Корова, конечно, государственная китайская, а все что она дает – молоко там, телят – уже наше (С).
Память – на выбор из 3, Micron, Samsung и Hynix.
SSD – на выбор из InnoGrit, Marvell, Maxio, Phison, Silicon Motion (SM), SandForce, Samsung.
IPMI на выбор ASPEED AST2500 и AST2600 (2700 и 2750 я пока не видел).
Все это отлично, пока серверов 1-2. Как только требуется малейшая автоматизация, даже не ironic, хотя бы redfish – ой, как там все отвратительно. Как хорошо сохраняются настройки BIOS и boot selector при обновлении, вы не узнаете, пока не начнете с этим сталкиваться.
Linux с KVM тоже работает, и работает очень неплохо, пока не начинаешь уточнять нюансы. Например, что и почему написано в статье The Linux Scheduler: A Decade of Wasted Cores, или где посмотреть что-то аналогичное по содержанию сессии VMware Explore US 2023 Breakout Session - CEIT1319LVR Extreme Performance Series: Performance Best Practices by Mark Achtemichuk, Valentin Bondzio, видео CEIT1319LVR, или Extreme Performance Series 2022: SAP HANA 8-Socket Performance или Extreme Performance Series 2024: Enabling and Optimizing GenAI Workloads with LLMs ?
Но все работает. В демо стенде на 3 сервера. Без нагрузки и испытаний. Почему в демо только трисервера, спросите вы? Потому что к импортозамещенной внешней SAS полке больше серверов не подключить, а купить российскую СХД в демо стенд – на СХД денег нет, на Broadcom Brocade G720 денег нет тем более, как и Mellanox MSN2410-CB2FO (48-port 25GbE + 8-port 100GbE), а их для стенда надо два, причем и тех и других – часть бизнеса в РФ очень консервативна и предпочитает FCP. И, глядя на некоторых как-бы-сетевых-инженеров, я отлично понимаю почему.
Часть 3. Качество предлагаемого продукта
Как только мы начинаем обсуждать комплект поставки:
- железо,
- плюс поддержка железа,
- плюс гарантия на железо (с сроком поставки и штрафами - SLA,
- плюс возможности автоматизации настройки железа»,
- плюс качество работы любого импортозамещенного форка Openstack под маркой «это вовсе и не форк ветки 3-5 летней давности»,
плюс расчет стоимости железа под Ceph или (кстати, неплохой) vitastor, то выясняется, что людей, готовых с этим всем работать – не так много на рынке.
Точнее, готовых получать много денег полно, но могущих что-то, кроме как плакать «не работает» – очень мало. Потому что очень многих готовых, и могущих работать – забрали в Европу, а оставшихся «готовых» просто мало. Работать с этими комплексами, еще и в малых объемах, им совсем не интересно.
При этом, внутренние решения яндекса и вк – не тиражируемы, то есть «готовой коробки как Windows + S2d» или “VSAN ready nodes” или «Nutanix» - просто нет. Все импортозаместительные базовые продукты (ОС +виртуализация) вообще не готовы к эксплуатации в проде даже с требованиями 12*6, не говоря уже про 24*7*365.,
Достигнутый уровень - 8*5*300 - когда сервер может ночь лежать. Конфигурацию библиотек при этом надо зацементировать, иначе получить из кластера тыкву можно одним неловким upgrade –y. Забудьте про обновления.
И это все как-то работает до того момента, когда ваша импортозамещенная имитационная безопасность даже не предлагает, а требует поставить продукт, импортозамещенный, антивирусосодерщащий, не идентичный натуральному, внутрь гипервизора. Как работает этот продукт, не знает даже поддержка разработчика, но как влияет на работу, видно по тому, что, по оценкам экспертов, уровень задымленности и средняя температура в офисе после установки повышаются на 4%.
Часть 4. Цена перехода во втором приближении
Железо. Обходится на 30% дороже. На 20%, потому что производство должно окупиться, и на 10%, потому что на каждые 5..20 купленных серверов нужно сразу покупать еще один - на свой склад в резерв. Это не говоря про СХД. И не говоря про SDS. SDS просто нет таких, «чтобы просто работали, а не вот это все». Таких, чтобы реально работали, и были готовы показать ПМИ и багтрекер.
Люди, готовые поддерживать и настраивать эти конструкции «чтоб работало нормально», а не «запустилось и ок» - дорогие, капризные, и .. и.
И в ходе недавних интервью (хотели мы нанять пару человек внутри РФ, чтобы возможно, кого-то потом забрать к себе на запад (или на восток)), выяснился неприятный сюрприз – очень много людей, не понимающих фундаментальных вещей, но пытающихся подменить их верой и шаблонами. Это давно не новость - российское ИТ комьюнити давно переродилось из комьюнити в какую-то смесь цеховой структуры конца 19 века и клуба майнеров. Во всех чатах «российской федерации майнинга» плачут раз в месяц, дескать «я думал, тут будет про майнинг, а вы мне картинки аквариуса на ракете показываете». Like enough; you wouldn't look to find a bishop here, I reckon, говорил в таких случаях одноногий Джон Сильвер, он же окорок.
Поиск людей крайне осложнен тем, что все больше людей в ИТ в РФ может пересказать стандартное мнение (windows плохой, linux хороший), но, как только начинается разговор чуть серьезнее «перезагрузите компьютер», когда надо уже залезать в связки tcpdump + strace, или действовать в гибридной инфраструктуре – все, сушите весла сэр. Если попросить такого кандидата-энтузиаста посчитать, во сколько обойдется внедрение CEPH на хотя бы 100 Тб полезной емкости с доступностью N+2, и хотя бы 150.000 IOPS 4к блоком на запись, то записи такого торможения не публиковали с полета Луны-25 от 19 августа 2023. Почему 150к, спросите вы? Столько дает младшая СХД одной фирмы - и по калькулятору, и по факту, без дедупа и коррекции.
Если же нужен человек, способный залезть в исходники KVM, и посмотреть что там, и при этом рассказать, что там в кролике, а не выполнить
git clone https://git.openstack.org/openstack-dev/devstack && ./stack.sh
то их нет даже в типа-разработчиках-дистрибутивов. В паре интеграторов были.
Часть 5. Российские облака
Тут могло быть видео «это просто праздник какой-то» с Владимиром Этушем, но, кажется, его нет на рутубе.
В российских облаках прекрасно, наверное, все. Куда не ткни – везде больно. Лежать неделю в год, то есть иметь не заявленные 9.99, а фактические 98% - это еще очень хорошо. Лимиты на IOPS – везде, функционала «выжать много IO в российском облаке, кроме как фактически выдать заказчику отдельный сервер с NVME» - нет.
Но NVME raid – это не то же самое, что даже VROC. При том, что VROC по качеству - это почти самое отвратительное, что я видел, сразу после Базиса, и чуть лучше Broadcom VMware до выхода update 3 и Windows до выхода сервис пак 3.
Storage vmotion между типами дисков урезан настолько, что даже о перемещении десятков Тб нагруженной базы, речь почти не идет. Обновления флейворов нет, и не предвидится. Я, конечно, и в DSC могу, и ансибл могу, руками могу, но как так то?
Часть 6. Работнику это все зачем? Да и менеджменту тоже
И вот мы приходим к самому мягкому.
В русскоязычной части интернетов очень любят говорить про окраинный капитализм, мировой коммунизм, и прекрасную советскую власть с самым лучшим мороженым. Кто-то даже может процитировать классика
«Капитал, — говорит „Quarterly Review“, — избегает шума и брани и отличается боязливой натурой». Это правда, но это ещё не вся правда. Капитал боится отсутствия прибыли или слишком маленькой прибыли, как природа боится пустоты. Но раз имеется в наличии достаточная прибыль, капитал становится смелым. Обеспечьте 10 процентов, и капитал согласен на всякое применение, при 20 процентах он становится оживлённым, при 50 процентах положительно готов сломать себе голову, при 100 процентах он попирает все человеческие законы, при 300 процентах нет такого преступления, на которое он не рискнул бы, хотя бы под страхом виселицы. Контрабанда и торговля рабами убедительно доказывают вышесказанное
Томас Джозеф Даннинг
Про торговлю рабами под страхом виселицы надо вспомнить (или узнать), что:
Асье́нто (исп. reale asiento, букв. «королевское согласие») — предоставлявшееся испанской монархией частным лицам и компаниям с 1543 по 1834 гг. монопольное право на ввоз в испанские колонии рабов-негров из Африки. По итогам Войны за испанское наследство Утрехтский мир (1713) предоставил право асьенто Великобритании на 30 лет. Первый министр Роберт Харли передал монополию на торговлю с испанскими колониями частной Компании Южных морей, которая в обмен приняла на себя непомерно выросший за годы войны государственный долг.
в 1841 году Конвенция великих европейских государств признала работорговлю морским разбоем и дала крейсерам право осмотра кораблей, подозревавшихся в совершении такой торговли, невзирая на флаг.
Что означало повешение для команды перехваченного контрабандного перевозчика рабов где-то с 1715 до 1841.
Но перехватывали примерно 3 (три) % потока.
Однако, все эти принципы работают только в случае, когда владелец предприятия сам им руководит, что характерно или для малых предприятий, или до того, как в фирму приходит большой бизнес, и.
И начинается Кафка. Только не грефневая, а та, которая Замок.
Линейный персонал
Линейному персоналу все это импортозамещение что есть, что нет. Все равно будет куплен самый дешевый вариант железа, и только в том минимальном количестве, которое скажут «купить». Дорогое оно, дороже привычной Супермикры. На это железо проще поставить пиратский Windows, потому что купить Windows легально в РФ почти нельзя, но пока за это не наказывают. Linux – сложно, остается развернуть какую-то обертску над KVM-QEMU, тот же Proxmox Virtual Environment, или даже devstack . Неплохие бесплатные решения, даже есть какое-то резервное копирование из коробки. Покупать без нужды тот же Openstack, только старый, с русификацией и грамоткой? Спасибо, но денег нет.
При этом, внедряемые решения на Proxmox или Openstack понятны и распространены. Это значит, что при смене работы и HR, и нанимающий менеджер увидят в резюме кандидата знакомые им слова KVM – Proxmox – Openstack. Кандидат с опытом – это всегда хорошо. Но любой импортозамещающий продукт при этом будет рынку не очень знаком – их слишком много, чтобы запоминать. На слуху только Брест (потому что Астра это Дебиан, хоть и старый, и внутри открыто пишут что OpenNebula), и Альт – эти сами по себе с их Альт Сервер Виртуализации, то есть Proxmox.
Работа с импортозамещением не дает линейно-инженерному персоналу навыков, полезных на рынке труда РФ с точки зрения оклада и квалификации. Docker дает. K8s дает. KVM дает. Proxmox, openstack, openshift, opennebula – уже под вопросом. Прочее импортозамещение – ничего не дает, подменяя знание «как это работает» - ритуалом. Точно так же, как любая работа руками, без средств автоматизации. Redfish хорошо, только у вас точно на него лицензии куплены ? Хотя бы Intel® Data Center Manager (Intel® DCM) или хотя бы Supermicro Update Manager (SUM) развернуты ? У импортозамещения точно есть аналоги? Точно точно?
Эффективные совы среднего звена
Самое активное противодействие внедрению импортозамещения идет выше уровня линейного персонала. Внедрить любое импортозамещение так, чтобы оно работало – крайне сложно. Возможно, но долго, дорого, и очень человеко-зависимо. ВК может. Яндекс может. Остальные могут поговорить и показать слайды, про прекрасное будущее потом, после оплаты.
При этом официально декларируется, что незаменимых у нас нет, и быть не должно. С точки зрения управления, иметь резерв по функциям людей – нужно, но это постоянно перерождается в крайности. Например, «типа незаменимому сотруднику» надо постоянно показывать, что он на самом деле никто, потому что если он продолжит демонстрировать отсутствия чинопочитания и преданности на уровне собаки, то коллектив может увидеть, что так можно.
Тушканчики не могут собирать орехи, но можно поставить себе и им в КПИ, что они научатся. Бельчонок не нужен.
Процесс внедрения требует людей, которые что-то могут. Но такие люди постоянно демонстрируют полнейшее отсутствие чинопочитания. Практически, бунтовщики, и гораздо эффективнее соврать, что чего-то внедрено и проведено (хотя на самом деле – нет), чем с такими людьми работать. Эффективные совы своими решениями по сохранению своего положения могут сорвать что угодно.
Большие филины
Для многих покажется странным, но современному менеджменту в РФ первична демонстрация (от менеджмента - вверх, к ЛПР, людям принимающим решения) и лояльности, и энтузиазма в исполнении приходящих сверху решений. При этом успешность определяется соблюдением баланса между двумя крайностями. Решение сверху при этом не обсуждается, не подвергается сомнению, но при этом допускается и не исполнение решения сверху при наличии достаточного и приемлемого сегодня оправдания. У уж тем более, критика решения не допускается, но можно и свалить вину на подчиненных (не всегда, потому что нет плохих подчиненных – кто-то просто не умеет управлять), и сказать что все готово, просто немного опаздываем, и просто отчитаться что все готово, когда на самом деле не готово ничего. Пока вверенная фирма и система находится в неких допустимых рамках состояния, то тактические решения вида «скроить сейчас, а с проблемами будут разбираться те, кто будет после меня» - повсеместная практика.
Если посмотреть на состояние внедрения импортозамещения при таком подходе, то окажется, что для отчетности можно делать что угодно, если это не видно «сразу».
И про сайты знакомств
Самое интересное в этом подходе, применяемом сверху донизу, так это то, что он отлично виден не только в ИТ, но и в судьбе сайтов знакомств. До сами знаете когда в РФ не было конкурентов Тиндеру и с неким отставанием Badoo. Мамба, лавпланет и прочая старая система была не эффективна уже тогда, но как-то работала. Pure был на любителя.
2022 год, Коммерсант:
“Ъ” опросил популярные сервисы знакомств об итогах их работы в 2022 году. В «Мамбе» рассказали, что выручка по итогам прошлого года сократилась на 10%, однако чистая прибыль удвоилась. Согласно данным Kartoteka.ru, в 2021 году доходы АО «Мамба» составили 1 млрд руб., чистая прибыль — 24 млн руб.
2023, ТЖ
В 2023 году выручка компании увеличилась почти вдвое и составила 1,61 млрд рублей, а прибыль выросла в четыре раза — до 450 млн рублей.
Но при этом:
В среднем рост российских игроков на рынке дейтинговых сервисов по скачиваниям год к году в среднем составил 20−30%. В настоящее время их ежемесячная аудитория составляет около 7 млн человек, еще около 3 млн пользуются сервисами на десктопах и мобильных версиях сайтов (без установки приложений). В деньгах рынок просел почти в три раза с февраля 2022 года по июль 2023 года — со $417 тыс до $130 тыс. еженедельно.
То есть, при росте доходов российских сервисов и росте их аудитории – совокупный доход и совокупная аудитория сервисов падают. Дайвинчик тоже уже сдулся, по слухам.
То есть:
В ИТ: Импортозамещением «массово» действительно заниматься некому, и денег нет. И так у всех ок – российские «заместители» отчитываются про рост доходов. Реклама на ракете крутится – бабки мутятся.
В дейтинге: Нет смысла серьезно замещать сервис – доходы и так растут, а крики некоторых безденежных донов, что «подставь название любого продукта» совсем не Тиндер, криками и останутся – денег у них все равно нет. Реклама крутится – бабки мутятся.
Идеальная ситуация со всех сторон – одним не очень надо, другим нечего предложить, и есть огромное поле для разговоров и маневрирования. Главное – белое не надевать, и новое платье короля не обсуждать слишком детально.
Для лиги лени: нытье какое-то и унылые цифры про software-defined storage, что там как.
Немного теории - Software-defined storage, что это
Лет 20 назад, в 2004 году, когда я еще ходил в школу, и читал комиксы про всамделишные приключения сексуального вампира, системы хранения данных жили отдельно (за дорого и очень дорого), сервера отдельно. Только-только вышел SQL Server 2000 Service Pack 2 (SP2), кластеризация на уровне сервиса была у SQL (кто хочет, найдет статью Clustering Windows 2000 and SQL Server 2000, Brian Knight, first published: 2002-07-12) , и вроде, в Oracle RAC.
Почему было такое деление? Потому что расчет четности и двигание блоков данных туда-сюда – операция, с одной стороны математически не самая простая, с другой – рутинная, использовать под них относительно медленный процессор общего назначения, хоть x86, хоть уже умершие к тому времени Motorola 68060 и еще живые UltraSPARC II, не очень рационально.
К середине 2010х ситуация постепенно изменилась. Производительность x86 выросла, цена за операцию упала. Со стороны классических СХД еще в 2015 в тех же 3Par стоял отдельный модуль для расчета чего-то-там, в Huawei Oceanstor v2 можно было покупать отдельный модуль LPU4ACCV3 Smart ACC module, но основная нагрузка уже считалась на x86 - HPE 3PAR StoreServ 7000 уже был на Intel Xeon. К 2019 Huawei перешел на Arm, точнее на Kunpeng 920.
Примерно в то же время, а точнее в Microsoft Windows Server 2012 появилась поддержка динамических рейдов в виде Storage Spaces, плюс появился SMB Direct и SMB Multichannel, к R2 Добавились local reconstruction codes, в 2016 Server появилась новая функция – S2D, storage space direct, но это уже старая история, а там и ReFS подоспел, с своей защитой данных от почти чего угодно, кроме своей дедупликации и своего же патча на новый год (January 2022 Patch Tuesday KB5009624 for Windows Server 2012 R2, KB5009557 for Windows Server 2019, and KB5009555 for Windows Server 2022.)
Все бы было хорошо и там, и тут, НО.
Но. S2D поддерживается только в редакции Datacenter, а это не просто дорого, а очень дорого. На то, чтобы закрыть этими лицензиями небольшой кластер серверов на 20 – уйдет столько денег, что проще купить классическую СХД.
Но. Если у вас в кластере работает хотя бы 1 (одна) виртуальная машина с Windows Server, вы все равно обязаны лицензировать все ядра всех узлов кластера лицензиями Windows Server. Тут уже надо считать, что выгоднее – попробовать закрыть все узлы лицензиями STD, с их лимитом в 2 виртуальные машины на лицензию, или лицензировать Datacenter.
Но. При этом все равно можно НЕ иметь нормальной дедупликации и компрессии (DECO) на Datacenter, НО иметь вечные проблемы со скоростью, если ваша система настроена криворукими интеграторами или таким же своим же персоналом, набранным за 5 копеек, и который тестирует скорость СХД путем копирования файла. Или путем запуска Crystal Disk mark с настройками по умолчанию.
Попутно получая проблемы с резервным копированием, если вы DECO включили, а руководство по резервному копированию с DECO Windows Server не прочитали.
Все очень просто: если экономим на кадрах, то покупаем классический выделенный СХД, в нем в разы меньше настроек и ручек, которые может крутить пользователь в GUI. Масштабируем емкость покупкой новых полок. Скорость так просто не масштабируется, как у вас стоит 2 или 4 или 8 контроллеров, так они и стоят (до 16 контроллеров, если вам очень надо).
Это не уменьшает проблем с обслуживанием, на классической СХД тоже очень желательно проводить обновление и прошивки СХД, и прошивки дисков. На некоторых СХД раньше (10-15 лет назад) обновление прошивки вполне могло привести к потере разметки и потере данных (ds4800). Но там порой и замена дисков вела к факапам, как на ds3500. Но и наоборот, в IBM была версия прошивки, которая работала 1.5, чтоли, года. Но и не прошиваться нельзя – как недавно вышло с дисками HPE и не только, которые работали ровно 40.000 часов (Dell & HPE Issue Updates to Fix 40K Hour Runtime Flaw, update to SSD Firmware Version HPD8 will result in drive failure and data loss at 32,768 hours of operation, FN70545 - SSD Will Fail at 40,000 Power-On Hours и так далее).
С как-бы всеядными MSA (старых версий) можно было сделать самому себе больно иначе – купить саму СХД, а диски туда поставить подешевле, даже SATA с их надежностью (Latent Sector Error (LSE) rate) в «1/10(-16)», и получить проблемы при ребилде даже в Raid 6. Прошиваться страшно, не прошиваться тоже страшно, зато использовать левые диски не страшно.
Можно собрать комбо: дешевые кадры, дешевые сервера, дешевые диски – и иметь проблемы с доступностью, скоростью, отказоустойчивостью, полной потерей данных, и прочим.
Выбор цены решения – это выбор бизнеса, а ваш выбор как работника – работать с кроиловом, и потом нести ответственность при попадалове, которое вы же и выбрали, работая с кроиловом, за тот же мелкий прайс.
Почему Windows 2025 и storage space? Ведь есть же ..
Есть. На рынке РФ, кроме storage space и S2D, есть:
VMware by Broadcom vSAN. Есть специалисты, нет возможности купить напрямую нормальную подписку.
Высокие требования к оборудованию – нужны не бытовые дешевые SSD.
Высокие требования к людям - очень нужны умеющие и любящие читать люди.
Нужно планирование перед внедрением.
Нужна вменяемая сетевая команда, которая сможет настроить хотя бы DCB + RDMA и не впадает в священный ужас при виде Mellanox.
Nutanix. Давно ушел и с российского рынка, да и на мировом как-то скатывается в нишевое решение. Ограничения те же, что для vSAN.
Ceph. Есть и такие решения, но. Для его промышленной эксплуатации, а не в варианте «оно сломалось и не чинится, что же делать» нужны отдельные люди. Таких людей в РФ человек.. ну 20 - 40. Один из них – автор статьи Ceph. Анатомия катастрофы. Статью советую прочитать.
И это решение, если вы хотите хоть какой-то скорости, начинается с фразы «если у вас еще нет 200G коммутатора и карт, то вначале хватит и 100G, по два 100G порта на хост». Демо-стенд можно запустить хоть на 1G. Работать даже на 10G будет очень болезненно. Если еще на стадии демо начать задавать неудобные вопросы про RDMA и Active-active, то будет еще больнее. Почти так же больно, как спрашивать, можно ли использовать сервера, на которых развернут Ceph, под Openstack. И как его, Ceph, бекапить на ленты, как обеспечить аналог Veeam Direct SAN Access или Commvault Direct-Attached Shared Libraries или аналог Metro / Replication / Stretched Clusters
Остальные решения, особенно импортозамещающие, не стоят и рассмотрения. Проблема с ними всеми одна и та же – их разработчики имеют очень ограниченное представление о том, как работает ядро, как с ядром и драйверами взаимодействует виртуализация, что может быть намешано в сетевом стеке и как обрабатывать задержки в реальной среде. Наиболее эпичное падение у коллег в РФ было совсем недавно, когда пустой демо-стенд упал сам по себе. Не помню, с разносом данных в не восстановимую кашу или просто умер совсем, вплоть до переустановки всего кластера. И это я не вспоминаю о нагрузке при блоках разного размера, проблемах мониторинга, скорости работы Redundant Array of Independent Nodes (RAIN) и проблемах со скоростью при использовании четности (parity), а точнее при возникновении write amplification. И затем посмотрим, у какого из этих решений есть мониторинг, а у какого – система резервного копирования не на уровне приложений внутри виртуализации.
Альтернатива - иметь сложные интимные отношения с drbd, Patroni (PostgreSQL + Patroni + etcd + HAProxy), Stolon, Corosync, PaceMaker, BDR, bucardo, Watchdog – и постоянный риск split-brain. Рядом еще плавает RAFT и CAP theorem. Так можно докатиться до знаний про global transaction identifier (GTID) и Commit Sequence Number (CSN).
Все упирается в проблему человеков.
Или у вас большая организация с базой знаний, обучением, передачей опыта, и как-то это будет работать.
Или вы рано или поздно получите черный ящик, потому что настраивавший это человек (1 производственная штатная единица) уволился, и как это работает - никто не знает.
Если вам безразличен вопрос доступности и целостности ваших данных, то ничего страшного не произойдет.
Изначальные проблемы Storage space без direct
Это дорогое решение, необходимо считать что почем, в том числе лицензии.
Erasure coding (EC) в GUI в нем (и в S2D) был в 2016 и 2019 сервере реализован на уровне «ну как смогли». Из GUI можно было настроить Mirror и Raid-5 (single parity), настройка Raid-6 (dual parity) требовала, почему-то, толи 7 толи 8 дисков, не понятно зачем, и давала какую-то безумную физическую деградацию, раз в 10 кажется при настройках «всего по умолчанию», а про вынос журнала на отдельный диск никто не пишет, и публично вроде не тестировал.
Схема развертывания
Поскольку мне только посмотреть, то я попробую посмотреть, что будет на домашнем ноутбуке. SSD + Windows 11 + VMware Workstation Pro 17, недавно ставшая бесплатной для домашних пользователей.
Схема тестирования
Для тестов будет выделен отдельный (конечно виртуальный) диск – сначала на 40 Гб, чтобы посмотреть на то, сколько вытянет на нем Atto benchmark, по сравнению с таким же тестом, но без виртуализации.
Там же попробую DiskSPD – с настройками:
Образ для тестов – 10 Гб, тестирование:
1 файл, 1блок, 1 поток, 100% чтения, 50/50, 0/100 % записи. Продолжительность – 30 секунд прогрев – 10 секунд. Блок данных 4 к и 64 к. Форматирование раздела .. хм. Тоже надо посмотреть, конечно, write amplification это не игрушка.
1 файл, 1,2,4, 8 потоков и очереди 4, 8, 16 и 32.
В вариантах Mirror, parity GUI.
Объем, конечно, большой выходит, но, надеюсь, автоматизация мне немного поможет, не вручную же это каждый раз прописывать.
Или сокращу объем проверок, если надоест.
Получу представление, сколько может в теории дать мой ноутбук и сколько тратится на виртуализацию второго типа.
Затем попробую собрать в storage space 4, 6 и 8 дисков – через GUI, и посмотрю, что и как.
Моя глобальная цель – не столько посмотреть на падение скорости, сколько
1) посмотреть на варианты настроек Erasure coding (EC) в GUI и в CLI (это я в виртуальной среде сделать могу)
2) посмотреть, влияет ли, и если влияет то как, размер блока и четность.
Сразу видны подводные камни – у меня виртуализация 2 типа, поэтому приземляемый в файл в реальной ОС блок данных – будет работать в итоге с фактической разметкой NTFS, можно получить порядочный штраф.
В рабочей среде такого, конечно, не будет, но размер блока важен и при создании LUN на классической СХД. Там хотя бы пресеты есть, это иногда помогает.
Сначала посмотрим, что там с диском
Get-WmiObject -Class Win32_Volume | Select-Object Label, BlockSize | Format-Table –AutoSize
Или более классическим путем –
fsutil fsinfo ntfsinfo c:
Ничего интересного,NTFS BlockSize – 4096 (Bytes Per Sector : 512, Bytes Per Physical Sector : 4096, Bytes Per Cluster : 4096 (4 KB), Bytes Per FileRecord Segment : 1024
С глубиной очереди 4, Atto дает удручающие для конца 2024 года 100 мб/сек на запись и 170 мб/сек на чтение, 25к IOPS /40k IOPS, разгоняясь до 750/1300 мб/сек для блока 64 кб (и падая до 10 к/ 20к IOPS). Старый SATA SSD, откуда там чудеса?
Поставлю очередь 8, а тестирование ограничу размерами от 4 до 64. Стало ли лучше? Стало. 25к IOPS на запись, и 55 к IOPS на чтение для 4к блока, 16 и 20 к к IOPS для 64 к блока.
DiskSPD
Что читать: https://github.com/microsoft/diskspd
Качаем DiskSPD с github, распаковываем , кладем в C:\Diskspd\amd64 , делаем папку test, делаем первый тест
.\diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\Diskspd\test\test0001.dat > test0000.txt
И идем читать инструкцию.
-t2: указывает количество потоков для каждого целевого или тестового файла.
-o32: указывает количество невыполненных запросов ввода-вывода для каждого целевого объекта на поток
b4K: указывает размер блока в байтах, КиБ, МиБ или ГиБ. В этом случае размер блока 4K
-r4K: указывает на случайный ввод-вывод
-w0: указывает процент операций, которые являются запросами на запись (-w0 эквивалентно 100 % чтения)
-d120: указывает продолжительность теста
-Suw: отключает кэширование программной и аппаратной записи
И получаем (бадабумс) - 310.39 MiB/s , 80к I/O per s - 55000 на первый тред и 25000 на второй (округленно).
На этом месте пока прервусь, надо подумать как сделать удобнее.
Для ЛЛ: облака - это история даже не про TCO, RPO, RPM, и прочие непонятные слова. Все куда проще: это про CAPEX, OPEX и ROI
Облака 2024, как они себя чувствуют
Amazon Web Services, Inc. – образован в 2002 году, AWS (Cloud computing) – в 2006.
За 2022 год доходы (Revenue) составили 80 миллиардов долларов (US$80 billion)
операционная прибыль (Operating income) – 22.3 миллиарда (US$22.8 billion)
Microsoft Azure – образован в 2008, доходы за 2023 – 62 миллиарда долларов ($62 billion), прибыль – 21.9 миллиарда долларов ($21.9 billion) источник
Общий объем рынка -
Public cloud software as a service (SaaS) revenue 2024 - 247 bn USD
Public cloud platform as a service (PaaS) revenue 2024 - 176 bn USD
Public cloud infrastructure as a service (IaaS) end-user spending 2024 - 180bn USD
Источник
С чем бы это сравнить.. а вот, национальное достояние
Выручка от продаж, млн. руб в 2021 году - 10 241 353 – при курсе ЦБ 72.1464 = 141,952 млн. USD
Прибыль от продаж, млн. руб. в 2021 году - 2 411 261 – при курсе ЦБ 72.1464 = 33,421 млн. USD
Или: Яндекс Облако - За 2021 год выручка Yandex Cloud выросла в 3 раза —
до 2,9 млрд рублей.
при курсе ЦБ 72.1464 = 40.2 млн долларов.
Плюсы и минусы технической части облаков
Плюсы и минусы большой тройки облаков – AWS, Azure, GGP - много раз обсуждались, и нет смысла развернуто повторять их еще раз.
В плюсах и быстрое масштабирование, и резервирование хоть в локальном, хоть в гео-варианте, и 2-3-6 копий данных, и сервисы, которых вне некоторых облаков просто нет – начиная от Azure Accelerated Networking (AccelNet) и заканчивая давно известным Power BI.
В минусах – риски неправильного авто масштабирования, или простоя на 4..7 дней – как недавно в МТС , хотя МТС , и не они одни, возможно, просто не рассказывают про потери. Или полного удаления данных – как в Яндексе и недавнее удаление UniSuper в GCP
Стадии перехода инфраструктуры
Я не могу сутками рассказывать правду о том, что бизнес в моём родном краю считается успешным, когда начинается у чужого гаража, при свете найденного фонарика
Перевод инфраструктуры от 3 системных блоков под столом до хотя бы аренды стойки в ЦОД достаточно дорог. Дорог во всем – нужно обосновать покупку оборудования хотя бы по схеме N+1, дисков по схеме N+2, нужно два коммутатора, два маршрутизатора, возможно даже вместо коммутатора придется купить свитч*, а вместо маршрутизатора - роутер, потом купить канал до офиса, и оплатить интегратора на запуск. Потому что "свои проверенные админы" не могут запустить что-то сложнее 1с. Нанять людей, готовые это обслуживать, и ездить в ЦОД. Причем, купить оборудование «абы какое» уже не подойдет.
Конечно, можно купить веток, глины и желудей, собрать программно-определяемое решение на абы чем, потом набрать альтернативно одаренных, которые будут это эксплуатировать как умеют, и которые не умеют и не хотят читать даже на русском то, что им пишут, а делают все по своему. Это можно.
Это не запрещено.
Читатели одного чата в телеграмме (точнее, одного из немногих, посвященных не главному криптану всего Рунета, и не поисками виноватого в том, что модераторы удалили элитный флуд - кто лучше, тот кто майнит на проде по любви к деньгами, или тот кто майнит для борьбы с капитализмом) наблюдали вышеописанную драму, растянувшуюся на 10 дней. При этом продукт (решение) пытался выжить, как мог и как умел, но умельцы смогли его добить. Вручную, и только с четвертой попытки, сделав в точности обратное тому, что им советовали.
* разница между коммутатором и свичем проще, чем вы думаете. Коммутаторы делают Qtech и Eltex, свичи делает Cisco, Juniper, HPE (Arista), Huawei, Extreme , Mellanox.
После, или во время перехода от трех системных блоков в подсобке, к ЦОД, появляется гибридная инфраструктура – часть нагрузки в ЦОД, часть в облаке, часть все так же - в бывшей кладовке.
Но и у арендуемой стойки есть масса ограничений – например, при современных «горячих» процессорах и видеокартах, и при сохранении лимита в 5 киловатт на луч на стойку по подаче питания, и ограничениям отвода тепла в массе российских как-бы ЦОД и даже как-бы тир-3-но нет, поставить туда 2-3 GPU кластера на 2-4 видеокарты можно, но на этом и все. Дальше или надо искать другой зал (иногда в том же ЦОД) с хотя бы 10 КВт на луч, а если там будет еще и теплоотвод получше, а если еще и жидкостное охлаждение можно собрать – то это просто мечта.
Все это технические проблемы, которые можно пересчитать в стоимость закупки серверов, кондиционеров, ИБП, сетевого оборудования.
Проблемы, когда ИТ отдел всерьез начинается задумываться о переезде в облако, начинается с появлением даже зачатков своей разработки, пусть даже это свои модули в 1с, и особенно остро проявляются в тех случаях, когда к организации начинают предъявляться требования 152-ФЗ ПД, 177-ФЗ 187-ФЗ КИИ и прочие радости типа 846, 1912, 887, 193,194,141 .. ну, вы знаете.
Продукты, предлагаемые на этом рынке, можно разделить на две большие группы
– не работают даже на 10% от того, что должны заменить, но с сертификатом (1.5 продукта)
– не работают даже на 10% от того, что должны заменить, без сертификата (еще штук 25 продуктов)
По такому признаку, как «безудержно глючат разными способами» разделить продукты невозможно, ни программные, ни аппаратные. Начиная от отсутствия штатных функций, заканчивая split brain прямо во время пилотного проекта, с попутным превращением данных в кашу.
На этом месте уже руководитель ИТ и директор по финансам начинают считать деньги так, как никогда не считали.
Потому что для соответствия всему – надо утроить штат ИТ и купить то, что в обычной жизни было не надо. Это дорого, это очень дорого.
При этом раньше можно было купить железа на 5 лет, и прикупать по чуть чуть. Сейчас так не выйдет.
Облака - это про управляемость и уход от физики к разделению бюджетов
Все начинается с того момента, когда к вам или приходит регулятор, или возникает риск настоящих штрафных санкций. Пока потери бизнеса виртуальны, пока это "ну подумаешь пол-дня не работали", ничего не произойдет. Как только за потерями сервиса начинаются штрафы от заказчиков, или письма от регуляторов, тут же встает вопрос подсчета "Сколько же нам надо денег потратить для обеспечения сервиса хотя бы в виде 9 рабочих часов, с 9 до 9, в 6 дней в неделю", и второй вопрос - во сколько обойдется переход на 24*7*365.
И именно тут бизнес начинает покряхтывать, судорожно хвататься за сердце, кошелек, звонить сыновьям подруги и иным методом пытаться узнать - почему так дорого-то???? Почему надо два гарантированных луча питания, почему надо не 3 бытовых, а 5 промышленных кондиционеров, почему надо то, се, зачем нужен дежурный штат, почему в штат сразу нужен электрик, и сколько стоят люди, готовые это хотя бы посчитать. И заодно, что особенно актуально в услових РФ, какое импортозамещение сможет сделать А-А метрокластер, или, хотя бы, растянутый кластер, не превратив все в кашу при первой же потере кролика, который потащит за собой control plane, который нельзя сделать ни по настоящему высоко доступным (не по бумагам, а по результатам ПСИ), и который не устроит кашу из данных при split brain или потеря свидетеля.
И именно тут довольный начальник сисадминов начинает показывать, во сколько обходится желание соседнего отдела в виде "нам сейчас надо 20 гб места, но вы нам дайте сразу терабайт, и не просто нарисуйте, а закупите, но за свой бюджет". Каждый гигагерц и гигабайт отражен в бюджете, проведен через закупку, и просьбы в стиле ранней Масяни "вы как-нибудь так" приходят в конце месяца в виде счетов с разбивкой.
Послесловие
И затем у вас на 3 дня падает ЦОД госзнак.

