

Нужен бокс Usb под 2 Nvme с аппаратныv raid 1
Айтишники подскажите, второй день не могу найти девайс...
Что-то небольшое, надежное. .Спасибо
Айтишники подскажите, второй день не могу найти девайс...
Что-то небольшое, надежное. .Спасибо
После того как я прикупил себе RAID контроллер Adaptec 71605

и решил заново установить на Dell OptiPlex 990 SFF гипервизор ESXi, что-то пошло не так, а именно сборка образов и прочая чёрная магия в течение нескольких дней не принесли ожидаемого результата, то установщик не узнаёт мой сетевой адаптер:
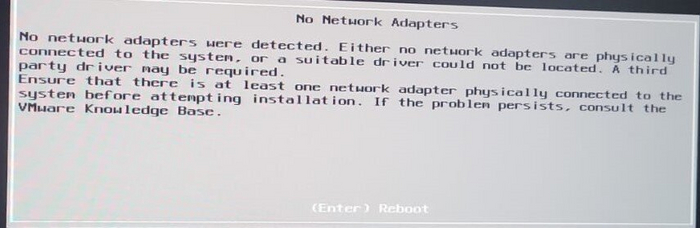
то не видит RAID контроллер, то все вместе, а то вдруг все видит, но на этапе установки ругается на мои вшитые в образ VIB с драйверами ссылаясь на какие-то зависимости:
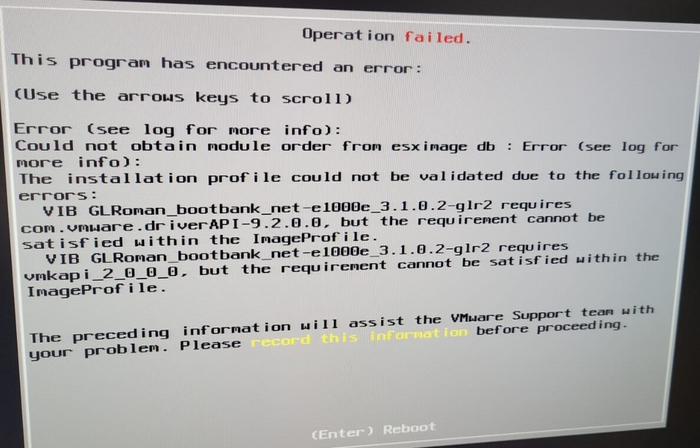
Этот момент мне несколько поднадоел и решил я в качестве эксперимента накатить последнюю версию Proxmox, вот как есть, без каких-либо изменений и она без проблем установилась на текущую конфигурацию, увидела и RAID контроллер и сетевую карту, да всё настолько легко прошло, что я решил перенести на неё все мои виртуалки. Собственно сам перенос из файла .ovf выполняется одной единственной командой qm importovf 103 /home/Win11/Win11.ovf local-lvm:

qm importovf 103 /home/Win11/Win11.ovf local-lvm
103 - идентификатор VM, /home/Win11/Win11.ovf - путь к файлу .ovf, local-lvm - путь к хранилищу на гипервизоре proxmox
В случае с Windows импорт я делал прямо из .ovf файла который получил путем экспорта с ESXi, там было достаточно заменить scsi0 на sata0 в конфигурационном файле /etc/pve/qemu-server/103.conf и добавить сетевой адаптер.
В итоге ОС запускается и работает без проблем:
А вот в случае, когда я переносил машину Debian с Home Assistant, первоначально у меня она была перенесена из .ovf в VMware Workstation, поскольку, пока я копался с настройкой Proxmox, надо было чтобы HA продолжал работать, затем когда всё готово было к переносу, я сделал экспорт Debian с HA и затем экспорт уже на Proxmox, всё завелось с полпинка, даже после проброса USB ZigBee Sonoff 3.0 dongle - не пришлось колдовать с Zigbee2MQTT, он заработал сразу. На волне успеха побежал импортировать свою виртуалку с Debian, которая с такой же лёгкостью не поднялась, а дело было в том, что на VM с HA у меня был BIOS, а на второй UEFI, тут то и зарылась проблема, понял я это не сразу и даже потратил немного времени, перенес виртуалку сначала в VMware Workstation, оттуда сделал экспорт, затем импорт в Proxmox и ничего не заработало, но оно и не удивительно. Теперь конкретнее, что необходимо было сделать если вы переносите таким способом VM Debian UEFI. После выполнения импорта на гипервизор в настройках виртуалки:
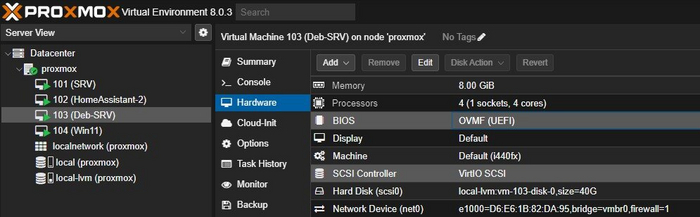
в разделе hardware поправим BIOS на UEFI и SCSI Controller меняем на VirtIO SCSI
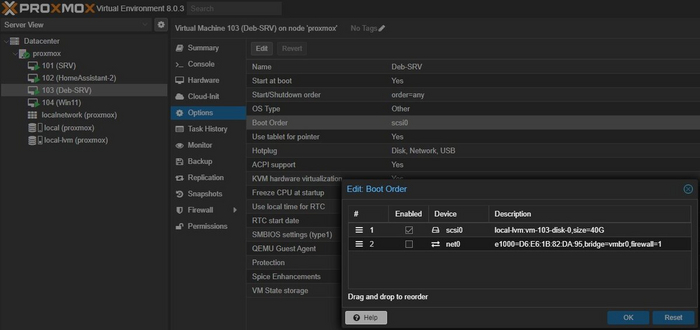
в options => boot order отмечаем первым пунктом наш диск
Сетевой адаптер добавить не забываем, они всегда слетают после импорта.
Далее необходимо запустить виртуалку и в консоли сразу же нажать ESC чтобы попасть в настройки UEFI, пройти по пути:
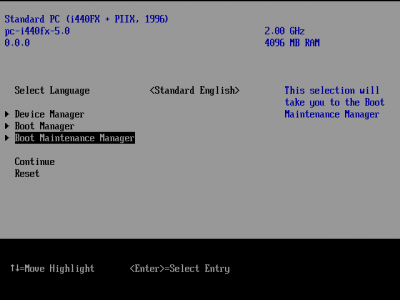
Boot Maintenance Manager =>
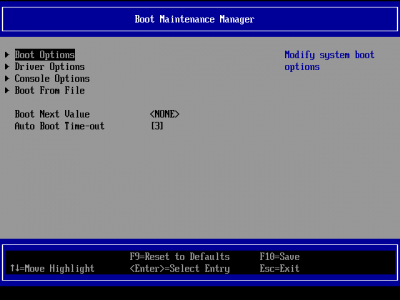
Boot Options =>

Add Boot Option =>

выбрать диск с EFI загрузчиком (он там будет единственный в большинстве случаев)
Далее пройти по пути до самого загрузчика:



(в случае с Debian - это shimx64.efi) выбрать его

зайти в меню Input the description вписать любое название для загрузчика
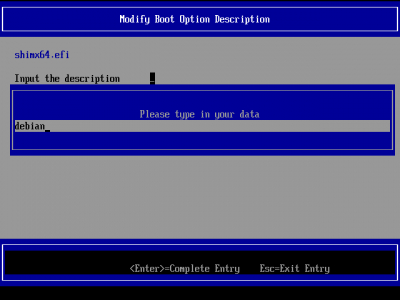
например debian
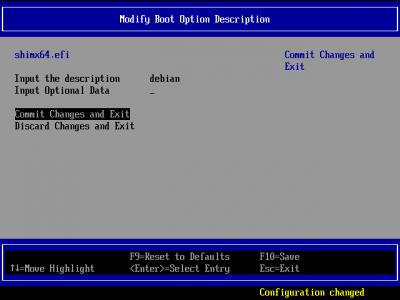
подтвердить нажатием Commit Changes and Exit
Далее изменить загрузку по умолчанию:
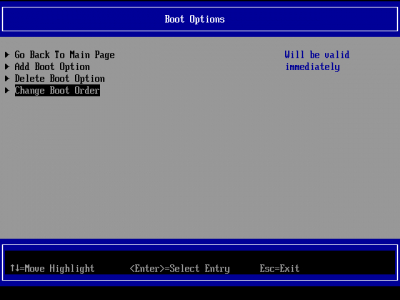
зайдя в меню Change Boot Order

там нажимаем Enter и плюсиком перемещаем debian на первый пункт и нажимаем Enter

подтвердить нажатием Commit Changes and Exit

нажимаем Reset
виртуалка перезагрузится
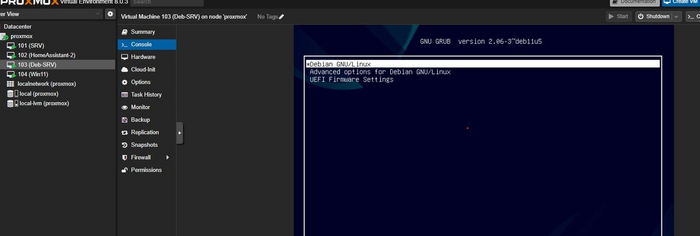
и вы должны будете увидеть Grub и успешно загрузиться в Debian
Кому интересна тематика умного дома, прошу в мой телеграмм канал, там регулярно пишу о своих идеях, сценариях, реализациях и прочих темах DIY, IoT, CS.
Всем привет, выручайте.
Случайно удалил том диска raid 0 массива. В массиве было 2 диска, сейчас отображаются оба с не размеченной областью. Новый том и разметку не создавал, на диски ничего не записывал. Кто знает, подскажите, пожалуйста, как восстановить том/вытащить данные из дисков? Пожалуйста, только конкретную информацию кто имел подобный опыт. Спасибо!
Для ЛЛ: несвязный набор ссылок про что-то душное.
Как пелось в одной песне -
We're going down, down, all the way down
We're heading deeper down
going down > Ph'nglui mglw'nafh Cthulhu R'lyeh wgah'nagl fhtagn
Все началось с того, что мне прислали очередную ссылку на разговор в российской майнинг-группе. Некий юзер начал плакать – как так, у меня NVME не дает в raid больше 100к IOPS, как страшно жить, ведь отдельный Samsung обещает :
Samsung 980 Pro SSD Random Write 4K QD32 Up to 1,000,000 IOPS
Samsung 990 PRO - while 4TB even higher random read speed of up to 1,600K IOPS.
Samsung обещает. Не забывая про то, что там стоит памяти 4 гб - Samsung 4GB Low Power DDR4 SDRAM
Но есть нюанс.
Давать то дает, но не под постоянной нагрузкой, и поэтому для бизнес-задач с нагрузкой 24*7 не годится – будут непредсказуемые падения скорости, когда контроллер решит заняться внутренними операциями.
Дальнейшая дискуссия между сторонами показала, что ни ноющему, ни основному составу майнинг-группы не понятно, зачем ему нужно именно столько, и куда он будет их девать.
Я, в свою очередь, очень удивился – откуда у людей руки растут. Пошел спросил результаты тестов у других коллег на одиноких NVME, без всяких железных raid. Seq WR, все такое.
Блок 4к, зеркало, очередь 16 , 100% чтение – 1600к IOPS
Блок 4к, зеркало, очередь 16 , 70/30 чтение – 850k IOPS на чтение, 350k IOPS на запись
Блок 64к, зеркало, очередь 16 , 100% чтение – 650к IOPS
Блок 64к, зеркало, очередь 16 , 70/30 – 250k / 100 k IOPS
Блок 64к, зеркало, очередь 16 , 100% запись – 150 k IOPS
Результаты, конечно, не показательны - разве что для того, чтобы было с чего разговор начинать. Значимо (в 1.5 раза) влияет и число потоков на файл (точнее, соотношение числа ядер процессоров и потоков на файл – как пишут в руководствах, In general it is recommended to use 1 CPU for testing and use the same number of threads), и количество файлов, точнее используемых в тесте разделов, и тонкие или толстые диски, и так далее.
В тестах выше был MS Server 2019, это тоже имеет значение – в MS Server 2025 обещали улучшить работу с NVME
Чтение по теме:
Use DISKSPD to test workload storage performance
Windows Server 2025 Storage Performance with Diskspd
Command line and parameters
Customizing tests
Best Practices Guide for Using the DiskSpd Performance Test Tool
Performance benchmarking with Microsoft Diskspd on Nutanix
На все это намазывается не только размер блоков, но и число выделяемых дескрипторов\очередей \прочего (внутри СХД, внутри системы, внутри везде, как тех же буферных кредитов – от которых можно получить Slow-Drain), особенно если у вас не локальные диски, а СХД.
И все равно в реальном мире можно нарваться на, цитата:
Setup: Dorado 18000, iSCSI, ESXi 7.0.3 (2x25Gb)На виртуальном диске 100 ГБ запускаю нагрузку FIO 70% read, IO Size 32 KB, вижу на datastore и на dorado одинаковый Read IO Request Size 32 KB.
На виртуальном диске 1024 ГБ тот же тест, та же нагрузка. На ВМ вижу 32 KB, на Datastore уже 25-26 KB на чтение. Запись идёт так же 32 KB. На Dorado соответственно тоже видно на чтение блок стал 25-26 KB.
Решение:
Причина мультипликации IO и несоответствия размеров блоков установлена!Проблема возникает при превышении объёма в 32 ТБ открытых VMDK файлов на хосте.
Накладные IO вызваны нехваткой кэша указателей блоков для открытых vmdk файлов.
Этот кэш необходим для быстрого обращения к открытым блокам VMFS без дополнительного доступа к метаданным из файловой системы.
При утилизации кэша больше 80% включается механизм вытеснения блоков указателей.
Вытесняются наименее активные блоки указатели и включаются (с чтением метаданных с vmfs) новые блоки. Отсюда возникает полученный нами overhead, т.к. нагрузочное тестирование, что FIO, что vdbench запрашивает блоки хаотично и по всему объёму.
Размер кэша задаётся advanced параметром:
VMFS3.MaxAddressableSpaceTB = 32 - Maximum size of all open files that VMFS cache will support before eviction mechanisms kick in
Его максимальное значение 128. При установке 128 - проблема с накладными IO в тестах уходит. Можно для целей тестирования выставить его в 128.
Увеличение кэша ведёт к накладным расходам по памяти, при значении по умолчанию 32 используется 128 МБ памяти. При максимальном значении 128 используется 512 МБ оперативной памяти.
В прод нагрузке вряд ли стоит увеличивать этот кэш, но посмотреть по хостам можно занятые объёмы кэшей командой:
esxcli storage vmfs pbcache get
В реальной жизни нет нагрузки со 100% активными блоками, как в синтетических тестах. Если, к примеру, активны только 20% всех блоков открытых VMDK и их указатели, соответственно попадают в кэш, то мы сможем иметь 160 ТБ открытых VMDK на хосте, при этом активные блоки указателей по-прежнему кэшируются без особого снижения производительности.
Поэтому ответ на исходный вопрос
«Но хотя-бы 400k IOPS почему никак не вытаскиваются из одного сервера с 10 дисков-то?» -
простой.
Наймите специалиста, если сами не можете. Все вытаскивается.
Дальше мне стало интересно, что же используют чуть более богатые фирмы, которые могут себе позволить потратить денег.
Оказалось, достаточно много всего, но, как всегда – есть нюансы.
Пропустим ту часть, где обсуждается «зачем столько». Сын маминой подруги сказал что можно, и дальше по классике -
НЕТ ДЕНЕГ НЕТ
@
НЕТ Я АДМИН
@
Я НИЧЕГО В ЭТОМ НЕ ПОНИМАЮ
@
ЭТО ГОСКОНТОРА ВЗЯЛИ МЕНЯ
Проблема применимости, про нее не стоит забывать.
Если у вас хотя бы 3-4 сервера с дисками, то зачем вам локальный RAID при наличии S2D и vSAN? Что с S2D, что с vSAN на 6-8 серверов можно получить 1-5 миллионов IOPS на чтение блоком 4к, при этом имея (с оговорками) и erasure coding, и, для S2D, ReFS Mirror-accelerated parity, и Data Deduplication, и в vSAN тоже много чего есть, и будет больше.
Но, к делу.
Что может выдать контроллер Broadcom MegaRAID 9670W-16i ? Посмотрим.
Broadcom MegaRAID 9670W-16i RAID Card Review.
Выглядит неплохо – до 240 SAS/SATA, до 32 NVME. Но, как только дело доходит до записи, все становится не так неплохо: для RAID 10 – Optimal
4KB Random Reads (IOPs) - 7,006,027
4KB Random Writes (IOPs) - 2,167,101
Но, есть нюанс.
Broadcom MegaRAID 9670W-16i - Storage controller (RAID) - 16 Channel - SATA 6Gb/s / SAS 24Gb/s / PCIe 4.0 (NVMe) 05-50113-00 – 1500$.
В соседнем тексте упомянули
Adaptec 3258upc32ix2s Cc 3258upc32ix2s Smartraid - 2000$. Тоже не очень дешевое решение для старого сервера.
Хотите быстрее? Нет препятствий патриотам. Только отечество не наше:
With a single SupremeRAID™ card, users can achieve extraordinary results, boasting up to 28M IOPS and 260GB/s. Supporting up to 32 native NVMe drives, it empowers exceptional NVMe/NVMeoF performance while enhancing scalability, server lifespan, and cost-effectiveness.
Supermicro and SupremeRAID™ Data Protection Solution
Performance results with SupremeRAID™ software version 1.5 on SupremeRAID™ SR-1010
2 миллиона IOPS в R5 на запись, пожалуйста.
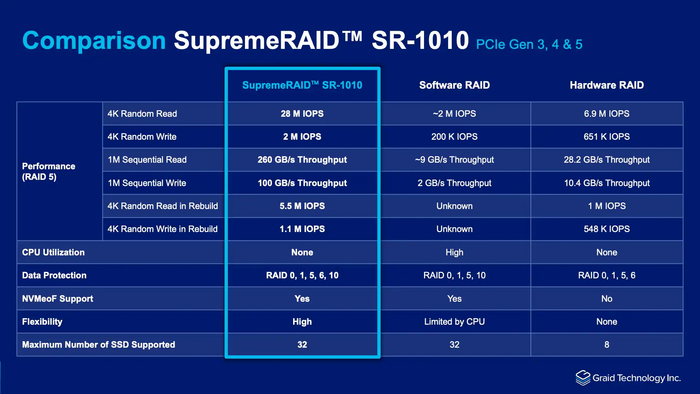
Performance results with SupremeRAID™ software version 1.5 on SupremeRAID™ SR-1010
Но, есть нюанс.
Graid SupremeRAID GRAID-1000 - 2600 $.
Graid SupremeRAID SR-1010 - 4000 $.
Не хотите карту? Нет проблем, Xinnor xiRAID.
Производительности это решение дает достаточно – до 65/8 миллионов IOPS (Xinnor xiRAID установил новый рекорд производительности среди NVMe-массивов с PCIe 5.0 SSD от Kioxia).
Говорившие «врети!» Graid даже убрали свой отчет с сайта – вот он был:
A Comparative Analysis: SupremeRAID™ NVMe® & NVMe-oF™ RAID vs Xinnor xiRAID Software RAID,
и вот его не стало.
Однако, забрать его успели сюда - Graid GPU-powered RAID card outperforms Xinnor software, картинки сами смотрите, читайте. И читайте, если интересно:
https://xinnor.io/blog/performance-guide-pt-1-performance-ch...
https://xinnor.io/blog/performance-guide-pt-2-hardware-and-s...
https://xinnor.io/blog/performance-guide-pt-3-setting-up-and-testing-raid/
Причем тут GPU?
Да при том. Graid SupremeRAID™ SR-1010 – это RTX A2000 (Ampere), и ее еще 70 ватт сверху, к и так не холодным NVME и CPU.
Вы, конечно, спросите, зачем это все?
И правильно сделаете. Идут такие решения, и подобное для тех, кому слишком дорого взять Nvidia DGX (Deep GPU Xceleration).
Дело не только в «дорого».
Набор для начинающих «по взрослому» - Nvidia DGX GB200 NVL72:
120 киловатт.
1.4 тонны.
Водяное охлаждение.
На 1 (одну) стойку.
Поэтому Equinix уже год рассказывает, какие они молодцы, и они на самом деле молодцы – столько электричества подвести, и столько тепла вывести, это вам не стойки по 5 киловатт на луч продавать.
У кого же денег не просто много, а неприлично много, и так знают те три слова, что я узнал в сегодня лет: weka, vastdata, vast.ai.
WEKA Data Platform for NVIDIA DGX BasePOD with H100
WEKA NVIDIA DGX A100 Systems (BasePOD)
The VAST Data Platform
Теперь там еще и Cosmos.
Концовка.
Тут должна быть какая-то не скомканная концовка, но я ее так и не придумал.

Первая группа создавшая RAID массив(1984)
Избыточные массивы независимых дисков превосходят диски мэйнфреймов
Дэвид Паттерсон, Гарт Гибсон и Рэнди Кац из Калифорнийского университета в Беркли представили статью «Дело об избыточных массивах недорогих дисков (RAID)» в 1988 году, в которой утверждалось, что массив из нескольких недорогих дисков, предназначенных для приложений ПК, может превзойти один большой дорогой мэйнфреймовый диск.

Прототип FrankenRAID в Калифорнийском университете в Беркли (ок. 1992 г.)
Концепция зеркалирования уже была хорошо известна, и некоторые системы хранения уже были построены вокруг массивов небольших дисков, однако их аббревиатура (позже измененная на Redundant Array of Independent Disks) стимулировала интерес к подходу и привлекла коммерческих поставщиков.

RAID The First — состоял из 28 5,25-дюймовых SCSI-дисков (1989)
Новаторская работа, которая привела к RAID, включает зеркальное дисковое хранилище Tandem Computers в ее Non-Stop Architecture и зеркальные подсистемные дисковые накопители RA8X (теперь известные как RAID уровня 1) DEC в ее системах HSC50 и HSC 70 в начале 1980-х годов. DataVault Thinking Machines использовал коды исправления ошибок (RAID 2) в массиве дисковых накопителей. Накопитель IBM 353 использовал аналогичный подход в начале 1960-х годов. Патентные заявки инженеров IBM, Нормана Кена Оучи (1977) и Брайана Кларка и др. (1988) раскрыли методы, используемые в последующих версиях RAID. Ранние независимые поставщики RAID включают Adaptec и Array Technology, которая была основана в 1987 году и последовательно приобретена Seagate, Tandem и EMC.

Современная подсистема RAID
Развился ряд стандартных схем, называемых уровнями, каждая из которых имеет множество вариаций. Уровни RAID и связанные с ними форматы данных стандартизированы Ассоциацией индустрии сетевых систем хранения данных (SNIA) в стандарте Common RAID Disk Drive Format (DDF). Сегодня большинство серверных и сетевых хранилищ основаны на RAID, и многие пользователи ПК используют аппаратные или программные RAID-системы на своих собственных машинах.
Приключение пакетишки
Для ЛЛ: сложности отладки производительности дисковых подсистем в среде виртуализации.
Каждый вечер, когда солнце прячется за верхушки сосен, на небе зажигаются звезды, а где-то в лесу неподалеку начинает ухать сова, которую мы уже два месяца не можем поймать, чтобы сварить из нее суп, - так вот: каждый раз, когда на нашу свалку опускается темнота, вся детвора собирается вокруг ржавого чайника в пустой нефтяной цистерне на западной окраине, чтобы попить кипятка, съесть по кусочку сахара и послушать сказку на ночь.
(проследовать за кроликом)
Зашел в нашем колхозном клубе разговор о том, как в конфету "подушечку" варенье попадает, и постепенно перешли на то, как данные из приложения попадают на диск, и где можно на граблях попрыгать, и на взрослых, и на детских.
Итак, у нас есть «данные».
Если речь заходит о том, что надо быстро и много работать с хоть сколько-то большими объемами данных, то обычно у производителя есть рекомендации «как лучше организовать дисковое пространство». Обычно. Но не всегда.
Общеизвестно, что:
Microsoft SQL работает с страницами по 8 кб, а сохраняет данные экстентами (extent) по 8 страниц – 64 Кб, и рекомендации для MS SQL - cluster (NTFS allocation) size в 64 Кб. (1) . Все просто, все понятно, и.
И даже есть статья Reading Pages / cчитывание страниц про Read-Ahead (Упреждающее чтение) экстентами по, вроде как, 64к, хотя прямо на странице этого не указано.
Для Oracle все тоже как-то описано – есть статья Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap) Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap)
Для PostgreSQL на Windows пишут просто: и так сойдет!- The default allocation unit size (4K) for NTFS filesystems works well with PostgreSQL.

Что там рекомендуют в проприетарном Postgrepro?
Да ничего, вместо документации и тестов – обсуждение на тему 8Kb or 4Kb ext4 filesystem page size из 2019 года.
Ладно, для простоты (более полная и занудная версия про размеры страниц в памяти будет на Пикабу) будем считать (хотя это и не всегда верно), что из приложения в Linux вылетит пакет размером 4к в сторону диска.
И, в первую очередь пакет попадет в буфер ОС, оттуда отправится в очереди, потом в драйвер диска, затем операция будет перехвачена гипервизором, и перенаправлена туда, куда гипервизор посчитает нужным. Если вы работаете не в среде виртуализации, а в контейнерах, то там все еще интереснее.
Настоящие проблемы только начинаются
Пропустим ту часть, где Linux отвечает приложению, что информация точно записана, инфа сотка, если вы понимаете, о чем я.
Дальше у пакета, в зависимости от настроек гипервизора, есть варианты, например:
Отправиться в путешествие по сети здорового человека блоками по 2112 байт.
Правда если вы альтернативно одаренны, и не следите за ретрансмитами, отброшенными пакетами, не настроили ano и mpio, то вы на ровном месте, на бильярдном столе яму найдете. И в ней утонете. Или наоборот, медленно высохнете (Slow drain in Fibre Channel: Better solutions in sight )
Отправиться в путешествие по сети бедного человека tcp блоками – в iSCSI или в NFS. Нарезка «по питерски» на блоки от 1500 до 9000 – на ваш вкус.
Отправиться в путешествие по сети нормального человека – в iSCSI или в NFS, но в Ge UDPwagen, со всеми остановками – DCB, lossless ethernet, congestion control.
И, самый неприятный вариант – отправиться на локальные диски, потому что по бедности ничего другого нет, и это самый плохой вариант. То есть, почти самый плохой, но есть нюансы.
Почему этот вариант плох?
Потому что, в случае проблем в стеке богатого человека, вы можете увидеть задержки в гостевой системе, задержки в системе гипервизора, посмотреть QAVG, KAVG, DAVG и сказать – проблемы где-то тут. Конечно, иногда приходится и в vsish ходить, и про Disk.SchedNumReqOutstanding знать, а то, что еще хуже, читать по не русски всякие документы типа vSAN Space Efficiency Technologies
В случае проблем в стеке не такого богатого человека – вы можете просто взять и включить:
Get-VM | Format-List Name,ResourceMeteringEnabled
Enable-VMResourceMetering -VMName NameOfVM
Get-StorageQoSFlow -CimSession ClusterName | Sort-Object InitiatorIOPS -Descending | select -First 5
Что делать в остальных случаях, я как-то не очень понимаю, потому что load average покажет что угодно, кроме того что мне интересно, а iotop и sysstat хороши, но показывают не то, что мне надо. Хотя - и так сойдет, главное не забывать валить вину на кого угодно.
Но и это не самая большая проблема, потому что на этом месте в игру вступает
БОЛЬШОЕ ФИНАЛЬНОЕ КРОИЛОВО
И, наконец, данные начинают приземляться на диски
Тут кто-то вспомнит выравнивание разделов (partition alignment), но это параметр, про который стоит помнить, и иногда проверять.
Самая простая часть кроилова, это IO amplification. С ним все просто, пришел пакет в 512 байт на 4к разметку – пришлось делать много операций. Открываете статью Cluster size recommendations for ReFS and NTFS из списка литературы, читаете. Потом возвращаетесь к началу этой заметки, и делаете ААА, вот про что это было.
Особенно больно будет, если у вас на хосте развернута любое программно-определяемое хранилище – хоть vSAN, хоть storage space, хоть storage space direct.
Там вы еще полной ложкой поедите не только IO amplification, но и Storage Spaces Direct Disk Write-Caching Policy, CSV BlockCache, и на сладкое - alternate data streams, вместе с Read-Modify-Write
Just a dose that'll make you wish you were born a woman
Более сложная часть шоу начинается с «мы купили какой-то SSD, поставили его в какой-то raid-контроллер, оно поработало, а потом не работает, мы купили SATA NVME и оно тоже не работает на те деньги, которые мы за него отдали, караул помогите ограбили».
Лучше этого шоу – только то самое, на Walking Street, ну вы знаете.
После такой фразы можно только посочувствовать, но пионер, то есть внешний подрядчик, должен быть вежливым, вне зависимости от того, что бабка, то есть заказчик, говорит*.
Сначала вспомним термины.
Solid-State Drive, SSD. Это диск. Может быть:
NAND (NOT-AND gate)) – SLC, MLC, TLC,
3D NAND (Vertical NAND (V-NAND) / 3D NAND ) - 3D MLC NAND, 3D TLC NAND, а там и QLC недалеко - QLC V-NAND. Какой там тип level cell, не так важно на данном этапе.
3D XPoint. Ох, как он был хорош, как мощны были его данные. Но, все. Optane больше нет, и не будет.
Compute Express Link (CXL) – не видел пока.
Non-Volatile Memory Express (NVMe) – это протокол, но есть NVMe U.2 и есть NVMe U.3
Serial Attached SCSI (SAS) – тоже протокол
SFF-8643 (Mini SAS HD) , SFF-8654 (x8 SlimSAS) , SFF-8639 –разъемы.
Universal Backplane Management - одна из возможностей, или функций, как хотите называйте, у контроллеров Broadcom 9500 (и не только).
Вспомнили?
Сходу суть: При включении SSD через RAID контроллер, и, особенно, через старый RAID контроллер, с его тормозной маленькой сморщенной памятью и усохшей батареей, и последующих тормозах, дело не только в фоновых операциях, всех этих Garbage Collection и TRIM, и даже не в балансировке нагрузки, а в том что контроллеры, года примерно из 2015-2018, вообще работают с новыми SSD отвратительно, и еще хуже, если это новый, но дешевый SSD, видевший некоторое Г.
Рекомендации типа «если у вас в контроллере нет JBOD, то просто сделайте RAID 0 на все» - есть, но их последствия, прямые и косвенные, описаны в статье Using TRIM and DISCARD with SSDs attached to RAID controllers (смотрите список литературы).
Контроллеры tri-mode – не позволяют получить из SSD NVME всю его скорость, а скорее привносят проблемы.
Больше проблем приносит, разве что, Intel VROC.
И, что самое интересное
У SSD есть свой микроконтроллер, в котором есть своя прошивка. Получить от вендора SSD, того же Micron, список исправлений между версиями – наверное, можно. Но на официальном сайте есть обновленный микрокод (прошивка), и только микрокод. Никаких релиз нот с описанием. Просто прошивайтесь.
А на какую, интересно, версию прошиваться, если производитель гипервизора у себя в списке совместимости указывает версию, которой у вендора на сайте нет?
Итого
Отладка «что так медленно-то» может начаться со стороны DBA, и в итоге оказаться где-то на уровне обновления микрокода RAID контроллера, или на уровне обновления прошивки диска.
Пока SCSI команды и нагрузка доедут до физических дисков – с ними чего только не происходит, и проблемы могут быть на любом уровне. Например, с уровнем сигнала (мощности) на оптическом SFP по пути.
Хуже всего сценарий, когда из соображений «кроилово» и «нечего читать – сбегали и купили Samsung 870 EVO , ведь дома на нем ИГОРЫ ОТЛИЧНО РАБОТАЮТ» . Иногда из соображений кроилова покупается продукт «для дома», рассчитанный на работу 4 часа в день при температуре +25, причем настроенный на задачу «загрузить игру – сохранить игру», а не 24*7 обрабатывать потоки данных при температуре +35.
ЗАПОМНИТЕ, КРОИЛОВО ВЕДЕТ К ПОПАДАЛОВУ.
Если вы собрали систему на домашних компонентах, она будет работать до первого падения какого-то из компонентов, потом превратится в тыкву. Как и данные. И их не вытащить. Никак не вытащить. Совсем никак.
Будьте готовы.
Хотя нет. Лучше не будьте. Когда все сломается, то:
- наймите на восстановление данных пару идиотов,
-один из которых эффективный менеджер,
- который не умеет читать вообще, зато может пушить первого
- второй думает, что он умеет читать, думает что умеет думать, и лучше знает, что ему делать (Эффект Даннинга — Крюгера), вместо того чтобы: прочитать, что ему пишут, записать что понял, спросить правильно ли он понял, переписать, и сделать хорошо. А плохо не сделать.
Эта парочка качественно и надежно похоронит то, что еще оставалось.
А уж если они привлекут к решению проблем AI, не пытаясь понять, что AI может насоветовать, то будет просто караул
Список литературы
Set the NTFS allocation unit size to 64 KB
SQL Server 2005 Best Practices Article
Disk Partition Alignment Best Practices for SQL 2008 Server
Improve Performance as Part of a SQL Server Install (2014)
Oracle Workloads and Redo Log Blocksize – 512 bytes or 4k blocksize for redo log (VMware 4k Sector support in the roadmap)
Oracle on VMware Collateral – One Stop Shop
2022 SQL Server on Linux: Scatter/Gather == Vectored I/O
2024 Performance best practices and configuration guidelines for SQL Server on Linux
The default allocation unit size (4K) for NTFS filesystems works well with PostgreSQL: PostgreSQL on FlashArray Implementation and Best Practices
Block Size on MSSQL on Linux
(тут мне стало лень оформлять)
Using esxtop to identify storage performance issues for ESXi (multiple versions)
https://knowledge.broadcom.com/external/article/344099/using-esxtop-to-identify-storage-perform.html
What is the latency stat QAVG?
https://www.codyhosterman.com/2018/03/what-is-the-latency-stat-qavg/
Troubleshooting Storage Performance in vSphere – Part 1 – The Basics
https://blogs.vmware.com/vsphere/2012/05/troubleshooting-storage-performance-in-vsphere-part-1-the-basics.html
Анализ производительности ВМ в VMware vSphere. Часть 3: Storage
https://habr.com/ru/companies/rt-dc/articles/461127/
Get Hyper-V VM IOPS statistics
https://pyrolaptop.co.uk/2017/07/07/get-hyper-v-vm-iops-statistics/
Tips and Tools for Microsoft Hyper-V Monitoring
https://www.nakivo.com/blog/tips-and-tools-for-microsoft-hyp...
Identifying storage intensive VMs in Hyper-V 2016 Clusters
https://bcthomas.com/2016/10/identifying-storage-intensive-v...
How to Monitor Disk IO in a Linux System
https://www.baeldung.com/linux/monitor-disk-io
What is VMware vsish?
https://williamlam.com/2010/08/what-is-vmware-vsish.html
vSphere ESXi 4.1 - Complete vsish configurations (771 Total)
https://s3.amazonaws.com/virtuallyghetto-download/complete_vsish_config.html
Advanced Disk Settings для хостов VMware ESX / ESXi.
https://vm-guru.com/news/vmware-esx-esxi-advanced-settings
Cluster size recommendations for ReFS and NTFS
https://techcommunity.microsoft.com/t5/storage-at-microsoft/cluster-size-recommendations-for-refs-and-ntfs/ba-p/425960
Why Intel killed its Optane memory business
https://www.theregister.com/2022/07/29/intel_optane_memory_dead/
How CXL may change the datacenter as we know it
https://www.theregister.com/2022/05/16/cxl_datacenter_memory/
Кабели для подключения NVMe к контроллерам Broadcom
https://www.truesystem.ru/solutions/khranenie_danny/424809/
Тестирование NVMe SSD Kioxia CD6 и CM6
https://www.truesystem.ru/review/424664/
Что нужно знать о стандарте U.3
https://www.nix.ru/computer_hardware_news/hardware_news_viewer.html?id=211282
Broadcom® 95xx PCIe 4.0 MegaRAID™ and HBA Tri-Mode Storage Adapters
https://serverflow.ru/upload/iblock/583/ehhvql2l0gn06v02227c...
Понимание SSD-технологии: NVMe, SATA, M.2
https://www.kingston.com/ru/ssd/what-is-nvme-ssd-technology
NVMe и SATA: в чем разница?
https://www.kingston.com/ru/blog/pc-performance/nvme-vs-sata
vSAN — Выбор SSD и контроллеров
https://vgolovatyuk.ru/vsan-controller/
FTL Design for TRIM Command
https://vgolovatyuk.ru/wp-content/uploads/2019/07/trim_ftl.pdf
Using TRIM and DISCARD with SSDs attached to RAID controllers
https://www.redhat.com/sysadmin/trim-discard-ssds
SSD TRIM command support and Adaptec RAID adapters
https://ask.adaptec.com/app/answers/detail/a_id/16994
New API allows apps to send "TRIM and Unmap" hints to storage media
https://learn.microsoft.com/en-us/windows/win32/w8cookbook/new-api-allows-apps-to-send--trim-and-unmap--hints-to-storage-media?redirectedfrom=MSDN
TRIM mdadm - How to set up SSD raid and TRIM support?
https://askubuntu.com/questions/264625/how-to-set-up-ssd-raid-and-trim-support
vSAN support of NVMe devices behind tri-mode controllers
https://knowledge.broadcom.com/external/article?legacyId=88722
Memory usage on Azure Stack HCI/Storage Spaces Direct
https://jtpedersen.com/2020/10/memory-usage-on-azure-stack-hci-storage-spaces-direct/
Deploy Storage Spaces Direct on Windows Server
https://learn.microsoft.com/en-us/windows-server/storage/storage-spaces/deploy-storage-spaces-direct
Microsoft Storage Spaces Direct (S2D) Deployment Guide
https://lenovopress.lenovo.com/lp0064.pdf
How to Enable CSV Cache
https://techcommunity.microsoft.com/t5/failover-clustering/how-to-enable-csv-cache/ba-p/371854
CSV block cache causes poor performance of virtual machines on Windows Server 2012
https://support.microsoft.com/sl-si/topic/csv-block-cache-causes-poor-performance-of-virtual-machines-on-windows-server-2012-88b35988-a964-30ba-98d9-9b89d0a39d35
Mirror accelerated parity (MAP) - https://learn.microsoft.com/en-us/windows-server/storage/refs/mirror-accelerated-parity
ReFS Supported Deployment Scenarios Updated
https://blog.workinghardinit.work/2018/04/17/refs-supported-deployment-scenarios-updated/
ReFS Accelerated VHDX Operations
https://aidanfinn.com/?p=18840
dedicated journal disk – точнее, старая статья Storage Spaces Performance Analysis – Part 1 https://noobient.com/2015/09/18/storage-spaces-performance-analysis-part-1/
Storage Innovations in Windows Server 2022
https://techcommunity.microsoft.com/t5/storage-at-microsoft/storage-innovations-in-windows-server-2022/ba-p/2714214
Reverse engineering of ReFS
https://www.sciencedirect.com/science/article/pii/S1742287619301252
Forensic Analysis of the Resilient File System (ReFS) Version 3.4
https://d-nb.info/1201551625/34
vSAN Space Efficiency Technologies
https://core.vmware.com/resource/vsan-space-efficiency-techn...
Доброго дня. Возник вопрос и понадобилась помощь, может кто сталкивался с таким.
Скопилось несколько HDD на 250, 500, 1000. валяются без дела. какие то живые, какие то не совсем. продавать- да кому они нужны. выбрасывать не вариант. хранить в пыли, тоже не очень.
И стало интересно, можно ли из них собрать raid 5 или 6. с возможностью замены умирающих дисков. Везде пишут что тома буду по объёму самого маленького. Ещё вариант создание виртуальных дисков, например подгонять все до терабайта и из них уже создавать рэйд.
Посоветуйте, как правильнее их использовать и организовать хранилище.



