LIMIT и интересные кейсы с ним. Или почему LIMIT - друг аналитика
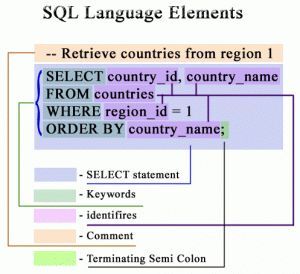
Обычно все знают самое базовое применение LIMIT - ограничение строк выдачи в запросе.
LIMIT 10 -> показать 10 строк
Но применение LIMIT не ограничивается только ограничением :-).
Есть интересные кейсы по использованию LIMIT в своих запросах.
Об этом чуть ниже.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!

И так, какие же кейсы есть с применением LIMIT
LIMIT + OFFSET
Многие помнят про LIMIT, но забывают про то, что можно еще применять сдвиг.
SELECT *
FROM users
ORDER BY id
LIMIT 10 OFFSET 20;Этот запрос вернёт 10 строк, начиная с 21-й.
Такой прием применяется, например, в постраничной выдаче результатов запроса.
Но этот кейс имеет и минусы: OFFSET все равно просматривает первые 20 строк, чтобы добраться до нужных. При больших объемах OFFSET работает медленно.LIMIT в UPDATE и DELETE
Да, да - в этих операторах тоже можно использовать LIMIT, не только в SELECT
DELETE FROM logs ORDER BY created_at ASC LIMIT 1000;
Так чистят таблицу порциями, чтобы не завалить базу огромным удалением.
LIMIT в подзапросах
Об этом часто помнят, т.к. подзапрос является запросом, а в запросах использование LIMIT - вполне привычное дело.
Найдем самый дорогой заказ:SELECT *
FROM orders
WHERE id = (SELECT id FROM orders ORDER BY price DESC LIMIT 1);
Это иногда проще, чем возиться с MAX() и джойнами.
LIMIT vs FETCH … WITH TIES
В некоторых СУБД (например, SQL Server, Oracle) есть фича:
SELECT *
FROM products
ORDER BY price DESC
FETCH FIRST 3 ROWS WITH TIES;
Такой запрос вернёт не просто 3 строки, а все строки, у которых цена такая же, как у третьей записи.
(например, если на третьем месте несколько товаров с одинаковой ценой).
LIMIT показывает первые N строк после сортировки
А вот WITH TIES говорит: «Выдай все строки, которые наравне с последней по значению сортировки».
В других СУБД такой синтаксис можно реализовать через LIMIT + подзапрос с оконной функцией RANK()LIMIT 0
Очень полезный трюк.
SELECT * FROM users LIMIT 0;
Вернёт пустую таблицу, но со всеми названиями и типами столбцов.
Это часто используют для генерации схемы в BI-инструментах или в тестахLIMIT в CTE (PostgreSQL)
Можно ограничивать данные прямо на уровне общего табличного выражения (CTE), чтобы уменьшить нагрузку:
WITH top_orders AS (
SELECT * FROM orders ORDER BY price DESC LIMIT 100
)
SELECT * FROM top_orders WHERE customer_id = 42;
Так мы сначала берём только 100 дорогих заказов, а потом фильтруем по клиенту.
В итоге LIMIT — это не просто «дай 10 строк», а инструмент для оптимизации, постраничной навигации, аккуратных обновлений и даже для защиты от перегруза.
Подписывайся на мой ТГ канал На связи: SQL, чтобы узнавать/вспоминать еще больше нюансов SQL запросов.