Обычно все знают самое базовое применение LIMIT - ограничение строк выдачи в запросе.
LIMIT 10 -> показать 10 строк
Но применение LIMIT не ограничивается только ограничением :-). Есть интересные кейсы по использованию LIMIT в своих запросах. Об этом чуть ниже.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
И так, какие же кейсы есть с применением LIMIT
LIMIT + OFFSET
Многие помнят про LIMIT, но забывают про то, что можно еще применять сдвиг.
SELECT * FROM users ORDER BY id LIMIT 10 OFFSET 20;
Этот запрос вернёт 10 строк, начиная с 21-й.
Такой прием применяется, например, в постраничной выдаче результатов запроса.
Но этот кейс имеет и минусы: OFFSET все равно просматривает первые 20 строк, чтобы добраться до нужных. При больших объемах OFFSET работает медленно.
LIMIT в UPDATE и DELETE
Да, да - в этих операторах тоже можно использовать LIMIT, не только в SELECT
DELETE FROM logs ORDER BY created_at ASC LIMIT 1000;
Так чистят таблицу порциями, чтобы не завалить базу огромным удалением.
LIMIT в подзапросах
Об этом часто помнят, т.к. подзапрос является запросом, а в запросах использование LIMIT - вполне привычное дело.
Найдем самый дорогой заказ:
SELECT *
FROM orders
WHERE id = (SELECT id FROM orders ORDER BY price DESC LIMIT 1);
Это иногда проще, чем возиться с MAX() и джойнами.
LIMIT vs FETCH … WITH TIES
В некоторых СУБД (например, SQL Server, Oracle) есть фича:
SELECT *
FROM products
ORDER BY price DESC
FETCH FIRST 3 ROWS WITH TIES;
Такой запрос вернёт не просто 3 строки, а все строки, у которых цена такая же, как у третьей записи. (например, если на третьем месте несколько товаров с одинаковой ценой).
LIMIT показывает первые N строк после сортировки А вот WITH TIES говорит: «Выдай все строки, которые наравне с последней по значению сортировки».
В других СУБД такой синтаксис можно реализовать через LIMIT + подзапрос с оконной функцией RANK()
LIMIT 0
Очень полезный трюк.
SELECT * FROM users LIMIT 0;
Вернёт пустую таблицу, но со всеми названиями и типами столбцов. Это часто используют для генерации схемы в BI-инструментах или в тестах
LIMIT в CTE (PostgreSQL)
Можно ограничивать данные прямо на уровне общего табличного выражения (CTE), чтобы уменьшить нагрузку:
WITH top_orders AS (
SELECT * FROM orders ORDER BY price DESC LIMIT 100
)
SELECT * FROM top_orders WHERE customer_id = 42;
Так мы сначала берём только 100 дорогих заказов, а потом фильтруем по клиенту.
В итоге LIMIT — это не просто «дай 10 строк», а инструмент для оптимизации, постраничной навигации, аккуратных обновлений и даже для защиты от перегруза.
Подписывайся на мой ТГ канал На связи: SQL, чтобы узнавать/вспоминать еще больше нюансов SQL запросов.
В прошлый раз мы увидели, как с помощью powershell можем взаимодействовать с моделью Gemini через интерфейс командной строки. В этой статье я покажу как извлечь пользу из наших знаний. Сегодня мы соберем интерактивный справочник, который на вход будет принимать параметры компонента (марка, модель, категория, артикул и т. п.), а возвращать интерактивную таблицу с характеристиками, полученную от модели Gemini.
Дисклеймер. В пикабу нет редактора кода - поэтому такое форматирование и картинки. В конце поста я дам ссылку на github. Почитайте, и если вам интересно, смотрите код на гитхабе.
Инженеры, разработчики и другие специалисты сталкиваются с тем, что нужно узнать точные параметры, например материнской платы, автомата в электрощитке или сетевого коммутатора. Наш справочник всегда будет под рукой и по запросу соберет информацию, уточнит параметры в интернете и вернет искомую таблицу. В таблице можно выбрать необходимый параметр/ы и по необходимости продолжить углубленный поиск. В дальнейшем мы научимся передавать результат по конвейеру для дальнейшей обработки: экспорта в таблицу Excel, Google таблицу, хранения в базе данных или передачи в другую программу В случае неудачи модель посоветует, какие параметры надо уточнить. Впрочем, смотрите сами:
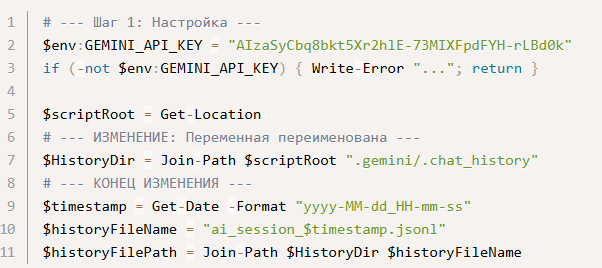
Шаг 1: Настройка
Назначение строк:
$env:GEMINI_API_KEY = "..." — устанавливает API ключ для доступа к Gemini AI
if (-not $env:GEMINI_API_KEY) — проверяет наличие ключа, завершает работу если его нет
$scriptRoot = Get-Location — получает текущую рабочую директорию
$HistoryDir = Join-Path... — формирует путь к папке для хранения истории диалогов (.gemini/.chat_history)
$timestamp = Get-Date... — создает временную метку в формате 2025-08-26_14-30-15
$historyFileName = "ai_session_$timestamp.jsonl" — генерирует уникальное имя файла сессии
$historyFilePath = Join-Path... — создает полный путь к файлу истории текущей сессии
Проверка окружения — что должно быть установлено.
Что проверяется:
Наличие Gemini CLI в системе — без него скрипт не работает
Файл GEMINI.md — содержит системный промпт (инструкции для AI)
Файл ShowHelp.md — справка для пользователя (команда ?)
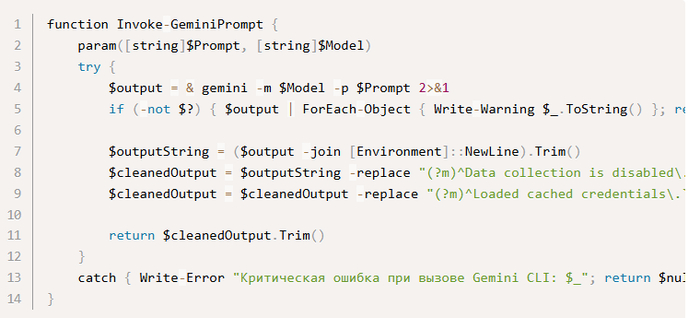
Основная функция взаимодействия с AI.
Задачи функции:
Вызывает Gemini CLI с указанной моделью и промптом
Захватывает все выводы (включая ошибки)
Очищает результат от служебных сообщений CLI
Возвращает чистый ответ AI или $null при ошибке
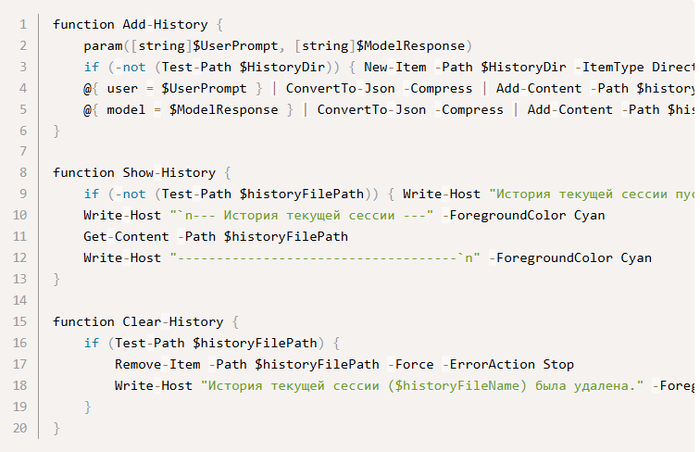
Функции управления историей.
Назначение:
Add-History — сохраняет пары «вопрос-ответ» в JSONL формате
Show-History — показывает содержимое файла истории
Clear-History — удаляет файл истории текущей сессии
Функция отображения выбранных данных
Show-SelectionTable
Задача функции: После выбора элементов в Out-ConsoleGridView показывает их в консоли в виде аккуратной таблицы, чтобы пользователь видел, что именно выбрал.
Основной рабочий цикл.
Основой цикл программы
Ключевые особенности:
Индикатор [Выборка активна] показывает, что есть данные для анализа
Каждый запрос включает всю историю диалога для поддержания контекста
AI получает и историю, и выбранные пользователем данные
Результат пытается отобразиться как интерактивная таблица
При неудаче парсинга JSON показывается обычный текст
Структура рабочей директории.
Проследим весь жизненный цикл нашего скрипта - что происходит с момента запуска и до получения результатов.
Инициализация: подготовка к работе
При запуске скрипт первым делом настраивает рабочее окружение. Он устанавливает API ключ для доступа к Gemini AI, определяет текущую папку как базовую директорию и создает структуру для хранения файлов. Особое внимание уделяется истории диалогов - для каждой сессии создается уникальный файл с временной меткой, например ai_session_2025-08-26_14-30-15.jsonl.
Затем система проверяет, что все необходимые инструменты установлены. Она ищет Gemini CLI в системе, проверяет наличие файлов конфигурации (системный промпт и справка). Если что-то критично важное отсутствует, скрипт предупреждает пользователя или завершает работу.
Запуск интерактивного режима
После успешной инициализации скрипт переходит в интерактивный режим - показывает приветственное сообщение и ждет ввода от пользователя. Приглашение выглядит как 🤖AI :) > и меняется на 🤖AI [Выборка активна] :) > когда у системы есть данные для анализа.
Обработка пользовательского ввода
Каждый ввод пользователя сначала проверяется на служебные команды через функцию Command-Handler. Эта функция распознает команды ? (справка из файла ShowHelp.md), history (показать историю сессии), clear и clear-history (очистить файл истории), gemini help (справка по CLI), exit и quit (выход). Если это служебная команда, она выполняется немедленно без обращения к AI, и цикл продолжается.
Если это обычный запрос, система начинает формировать контекст для отправки в Gemini. Она читает всю историю текущей сессии из JSONL файла (если он существует), добавляет блок с данными из предыдущей выборки (если есть активная выборка), и объединяет все это с новым запросом пользователя в структурированный промпт с разделами "ИСТОРИЯ ДИАЛОГА", "ДАННЫЕ ИЗ ВЫБОРКИ" и "НОВАЯ ЗАДАЧА". После использования данные выборки обнуляются.
Взаимодействие с искусственным интеллектом
Сформированный промпт отправляется в Gemini через командную строку. Система вызывает gemini -m модель -p промпт, захватывает весь вывод и очищает его от служебных сообщений CLI. Если происходит ошибка на этом этапе, пользователь получает предупреждение, но скрипт продолжает работать.
Обработка ответа AI
Полученный от AI ответ система пытается интерпретировать как JSON. Сначала она ищет блок кода в формате json..., извлекает содержимое и пытается его распарсить. Если такого блока нет, парсит весь ответ целиком. При успешном парсинге данные отображаются в интерактивной таблице Out-ConsoleGridView с заголовком "Выберите строки для следующего запроса (OK) или закройте (Cancel)" и множественным выбором. Если JSON не распознается (ошибка парсинга), ответ показывается как обычный текст в голубом цвете.
Работа с выборкой данных
Когда пользователь выбирает строки в таблице и нажимает OK, система выполняет несколько действий. Сначала вызывается функция Show-SelectionTable, которая анализирует структуру выбранных данных: если это объекты с свойствами, она определяет все уникальные поля и показывает данные через Format-Table с автоподбором размера и переносом. Если это простые значения, отображает их как нумерованный список. Затем выводит счетчик выбранных элементов и сообщение "Выборка сохранена. Добавьте ваш следующий запрос (например, 'сравни их')".
Выбранные данные преобразуются в сжатый JSON с глубиной вложенности 10 уровней и сохраняются в переменной $selectionContextJson для использования в следующих запросах к AI.
Ведение истории
Каждая пара "запрос пользователя - ответ AI" сохраняется в файл истории в формате JSONL. Это обеспечивает непрерывность диалога - AI "помнит" весь предыдущий разговор и может ссылаться на ранее обсуждавшиеся темы.
Цикл продолжается
После обработки запроса система возвращается к ожиданию нового ввода. Если у пользователя есть активная выборка, это отражается в приглашении командной строки. Цикл продолжается до тех пор, пока пользователь не введет команду выхода.
Практический пример работы
Представим, что пользователь запускает скрипт и вводит "RTX 4070 Ti Super":
Подготовка контекста: Система берет системный промпт из файла, добавляет историю (пока пустую) и новый запрос
Обращение к AI: Полный промпт отправляется в Gemini с просьбой найти характеристики видеокарт
Получение данных: AI возвращает JSON с массивом объектов, содержащих информацию о различных моделях RTX 4070 Ti Super
Интерактивная таблица: Пользователь видит таблицу с производителями, характеристиками, ценами и выбирает 2-3 интересующие модели
Отображение выборки: В консоли появляется таблица с выбранными моделями, приглашение меняется на [Выборка активна]
Уточняющий запрос: Пользователь пишет "сравни производительность в играх"
Контекстный анализ: AI получает и исходный запрос, и выбранные модели, и новый вопрос - дает детальное сравнение именно этих карт
Завершение работы
При вводе exit или quit скрипт корректно завершается, сохранив всю историю сессии в файл. Пользователь может в любой момент вернуться к этому диалогу, просмотрев содержимое соответствующего файла в папке .chat_history.
Вся эта сложная логика скрыта от пользователя за простым интерфейсом командной строки. Человек просто задает вопросы и получает структурированные ответы, а система берет на себя всю работу по поддержанию контекста, парсингу данных и управлению состоянием диалога.
Когда мы работаем с базой данных, почти всегда хотим не просто что-то выбрать, а применить несколько условий сразу. Например: выбрать всех клиентов старше 18 лет и с активной подпиской.
И здесь на помощь приходят два основных логических оператора: AND и OR.
Что делают AND и OR
AND — «и». Все условия должны быть выполнены одновременно. Пример: выбрать из холодильника молоко и яйца, чтобы приготовить омлет:
SELECT *
FROM fridge
WHERE product = 'milk' AND product = 'eggs';
(Да, в реальности одной строки с молоком и яйцом не будет, но идея ясна: оба условия должны выполняться вместе.)
OR — «или». Достаточно, чтобы выполнено было хотя бы одно условие. Пример: выбрать продукты, которые нужно купить или молоко, или яйца:
SELECT *
FROM shopping_list
WHERE product = 'milk' OR product = 'eggs';
Где могут использоваться
Эти операторы обычно используют в блоке WHERE, чтобы фильтровать данные. Также можно применять их в:
HAVING — фильтрация агрегатов после GROUP BY
JOIN ON — комбинирование условий соединения таблиц
Пример с HAVING:
SELECT category, COUNT(*)
FROM fridge
GROUP BY category
HAVING COUNT(*) > 5 AND AVG(expiry_date) < '2025-08-01';
Особенности и нюансы:
Порядок выполнения важен
AND имеет более высокий приоритет, чем OR.
Если смешиваете их, всегда используйте скобки для точного порядка:
SELECT *
FROM fridge
WHERE (product = 'milk' OR product = 'eggs') AND expiry_date < '2025-08-01';
AND «сжимает» результат, OR «расширяет» результат
AND оставляет меньше строк, OR — больше
Частые ошибки
Забыли скобки и получили слишком большой или слишком маленький результат
Использовали AND там, где нужен OR (или наоборот)
Смешали NULL значения: NULL AND TRUE и NULL OR TRUE могут вести себя неожиданно
Представим, что мама проверяет холодильник:
У неё есть список продуктов, которые могут испортиться: молоко, яйца, йогурт
Она хочет приготовить что-то, если и молоко, и яйца в наличии → AND
Она хочет перекусить, если есть молоко или йогурт → OR
В SQL это выглядит так:
-- Для приготовления омлета
SELECT *
FROM fridge
WHERE product = 'milk' AND product = 'eggs';
-- Для перекуса
SELECT *
FROM fridge
WHERE product = 'milk' OR product = 'yogurt';
AND и OR — это простые, но мощные инструменты фильтрации. Правильное использование скобок и понимание приоритета операторов помогает избежать ошибок и выбирать точно те данные, которые нужны.
А в своем канале На связи: SQL я публикую информацию с особенностями и нюансами в языке SQL, разбираю аналитические запросы и подходы работы с данными. Канал создала недавно с нулем подписчиков, но там уже есть интересная информация для работы аналитиков. Подписывайся!
Допустим, мы посмотрели меню и нам нужно правильно сформулировать заказ. В ресторане есть правило: общаться вежливо и говорить подробно. Это и есть протокол передачи данных — HTTP/HTTPS. Соблюдая протокол, нужно сказать так: «Принесите, пожалуйста, говяжий стейк средней прожарки». Так официант нас точно поймет: мы вежливы и знаем, чего хотим. Если бы мы сказали просто «Мне стейк», то в лучшем случае получили бы стейк, но не говяжий. В худшем случае официант ничего не принесет. HTTPS — это тот же HTTP, но с шифрованием, чтобы никто не подслушал наш заказ. По HTTP же данные передаются открыто, и сейчас почти все ресурсы используют HTTPS.
На этом можно было бы и закончить: ведь что такое HTTP я уже написала) Далее опишу, как смотреть коды ошибок и зачем они нужны - что для проджекта может быть важно.
Когда мы вводим адрес сайта в браузере, происходит примерно вот что: HTTP-запрос отправляется на сервер, сервер его понимает, выполняет нужные действия и возвращает HTTP-ответ. Важно: запрос можно отправлять не только через браузер, есть множество других способов (инструменты разработчика, через командную строку — curl-запрос, и т.д).
Как выглядит HTTP-запрос? Запрос всегда включает в себя: Метод — что мы хотим сделать. Те самые GET, POST, PUT, PATCH, DELETE из предыдущего поста - часть HTTP запроса. URL — куда отправляем запрос. Например /menu/steaks— посмотреть стйнки в меню. Версию протокола — указываем, какую версию протокола использовать. Например, HTTP/1.1 или HTTP/2. Заголовки (Request headers) — дополнительные данные. Например: с какого браузера мы передаем запрос? User-Agent: Mozilla/5.0. Тело запроса (Body) — содержимое запроса. В GET-запросах тело отсутствует (хотя технически его передать можно), а в POST и PUT оно требуется для передачи данных.
Если кажется что сайт не работает, форма обратной связи не отправляется, если кажется что проблема не на вашей стороне: стоит проверить, возможно вам не кажется. Для этого можно посмотреть, что ответил нам сервер по HTTP-протоколу. Самый простой способ посмотреть ответ - открыть DevTools: в браузре нажать F12 → перейти во вкладку Network → там прописаны все данные, из которых состоит запрос и ответ. Что мы там увидим? Нас интересует вкладка Response - ответ сервера.
Сервер отвечает тоже по правилам: Статус (код ответа) — получилось или нет. Например, 200 OK — всё хорошо, заказ точно такой, как и просили. Коды делятся на группы: 1xx — «Ожидайте». Например, запрос принят, но заказ еще готовят. 2xx — «Всё хорошо». 200 OK: Вот ваш стейк. 3xx — «Редирект». К примеру 301: ресурс переехал. Куда? Нужно смотреть в заголовке, в поле Location. 4xx — «Ошибка клиента» (Мы ошиблись!). 400 Bad Request: тот случай, когда мы сказали «Мне стейк» и официант не понял, что мы хотим. 5xx — «Ошибка сервера» (Не мы ошиблись!). 500 Internal Server Error: отключили свет, и заказ приготовить сейчас не могут, но всё обязательно починят. Заголовки (Response headers) — дополнительные данные, например: Content-Type: text/html говорит о том, что в теле ответа мы получили HTML-разметку. Тело ответа — сами данные. В ресторане бы нам просто отдали сам стейк.
Но! Если сайт не работает, не всегда можно увидеть ответ. Сайт может просто не достучаться до сервера и на это могут быть разные причины - плохая настройка сервера, недоступность сети и другие, но не об этом сейчас)
Получилось очень объемно, и многое осталось без внимания, но своими постами я хочу не научить, а объяснить — всё-таки это разные вещи 🙂
Я начала вести тг канал, где рассказываю просто о сложном в IT. Если вы дочитали этот пост, то скорее всего вас интересует тема, поэтому буду рада, если поддержите подпиской: https://t.me/jer_it
Кто есть кто в мире аналитики: 5 ролей, которые вечно путают между собой
Когда я представляю себя как Аналитика, то у многих сразу возникает такое мемное облако комментариев с вопросительными знаками.
По большей части, я позиционирую себя как аналитик данных. Мне это больше нравится :-)
У всех на слуху это слово, эта профессия. Но каждый может воспринимать Аналитика по-разному. да, и в принципе, аналитики бывают разные.
Очень часто Аналитика воспринимают, как что-то "неопределенное": - то ли ты нейросетью командуешь, - то ли дашборды лепишь, - то ли базу данных "селектишь" - то ли Excel открываешь с утра и закрываешь на закате.
Поговорим, какие бывают аналитики и чем они реально занимаются. На самом деле, аналитиков - много видов. И все их градации для многих могут восприниматься как "тройняшки" - одинаково звучат, похожи, но если копнуть — совершенно разные люди.
🧠 Product Analyst (продуктовый аналитик)
Вот вам и продукты для аналитики :-)
Основная задача продуктового аналитика: следить за тем, чтобы продукт развивался и приносил деньги. А просто работать продукт должен по умолчанию.
Считает метрики вроде Retention, Conversion, DAU и объясняет команде, почему кнопку “Купить” никто не нажимает.
Сравнение: как врач, который измеряет давление у пациентов и говорит: «Ага, у нас тут проблема с притоком пользователей!»
📊 BI-аналитик (Business Intelligence)
Это мастер дашбордов и визуализаций. Подключается ко всем базам в мире и делает такие красивые отчёты, что их даже открывают. Не про гипотезы, а про «дай цифру, красиво покажи и свяжи с базой». Иногда визуализация помогает делать выводы, которые сложно сделать, имея перед глазами только табличку.
Сравнение: бариста, который не варит кофе, а собирает витрину, где всё понятно: сколько чашек продали, кто пил больше всех, и где упала выручка.
🕵️♀️ Data Scientist (дата-сайентист)
Вот тот самый, с нейросетями, моделями, предсказаниями. Уже ближе к разработке: он не просто видит, что клиенты уходят, а строит модель, которая предсказывает, кто уйдёт завтра. Работает с машинным обучением, статистикой и ноутбуками Jupyter. Уровень математики: "убираем логарифмическую линейку!"
Сравнение: как синоптик, который предсказывает, какая будет погода на следующей неделе.
🛠 Системный аналитик
Он не про данные. Он про системы. Пишет ТЗ, общается с бизнесом, командой, разбирается, как вообще всё должно работать, и описывает это человеческим (и машинным) языком. Если где-то не работает кнопка — это, возможно, не баг, а просто никто не подумал о логике. А системный аналитик должен подумать.
Сравнение: как архитектор, который сначала рисует, как будет выглядеть дом, а только потом его строят.
Лезет в сырые данные, ищет закономерности, тестирует гипотезы. У него может не быть задачи «нарисуй отчёт». У него задача: «А почему у нас что-то идёт не так?» Работает как Шерлок — задаёт неудобные вопросы и копает глубже.
Сравнение: как учёный в лаборатории. Только вместо пробирок — SQL и Python. В общем, если говорят "поисследуй", то это может вылиться в целый НИОКР (научно-исследовательские и опытно-конструкторские работы)
🎭 Бонус: аналитик на проекте без нормального описания ролей
— это человек-оркестр. Он вроде как "BI-аналитик", но на деле и SQL пишет, и ТЗ собирает, и гипотезы проверяет, и отчёты делает, и баги чинит в дашборде. А потом приходит кто-то сверху и говорит: «Ну ты же BI, всё логично» 😅
🎁 И да, всё это может совмещаться в одном человеке. Особенно, если это маленький проект. Особенно, если ты «просто аналитик» и должен всё уметь.
🧵 Поэтому, когда снова услышите «аналитик», лучше спросите: «А чем ты именно занимаешься?» Иначе можно перепутать с программистом на Python, который просто делает красивые таблички.