Выпуск серии видеокарт RTX20 в свое время стал важнейшим событием в сфере компьютерных технологий. Десктопные видеокарты впервые получили отдельные тензорные ядра. Что это такое? Как работают эти ядра и для чего используются?
CUDA и тензорные ядра
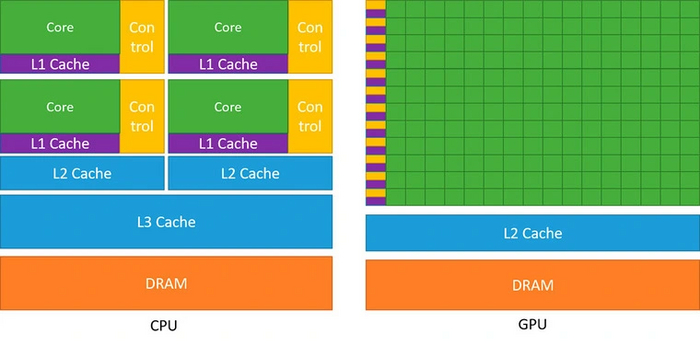
Работа с графикой — специфическая задача для компьютерного «железа». Здесь требуется выполнять довольно однообразные команды с большим объемом данных. Архитектура CPU для этого подходит плохо. Из-за ограниченного числа ядер и АЛУ (арифметико-логических устройств) процессоры не могут быстро делать объемные операции по сложению и умножению.
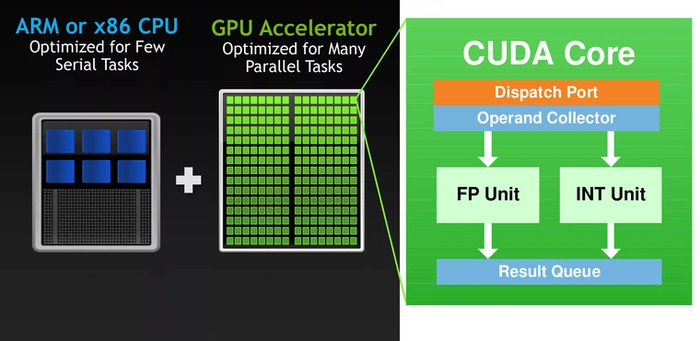
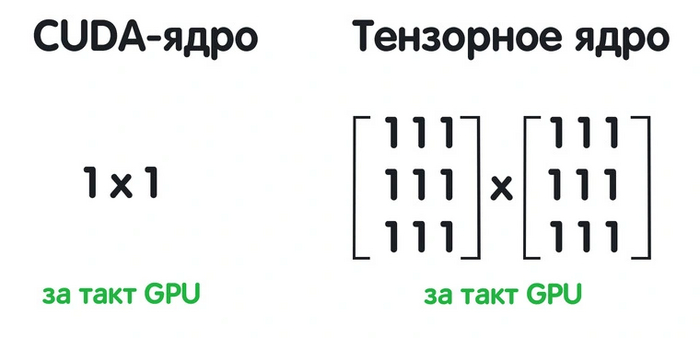
Был необходим максимальный параллелизм — одновременная обработка данных. Одним из решений стали CUDA-ядра — технология, созданная Nvidia больше десяти лет назад. Эти ядра создали специально для параллельной работы. На чипе помещались сотни и тысячи CUDA-ядер, а их число стало одним из критериев оценки производительности видеокарты.
CUDA-ядра имеют высокоскоростной доступ к видеопамяти, так что обработка выполняется с минимальными задержками. Это важнейший показатель для быстрого вывода подготовленных кадров на монитор.
Однако обработка больших объемов данных нужна не только при выводе графики. Она требуется для научных вычислений, моделирования физических процессов и машинного обучения. Во всех этих задачах одна из главных операций — перемножение матриц.
Задача непростая. Скажем, для решения вышеописанного примера нужны целых 64 умножения и 48 сложений. Не говоря о том, что промежуточные результаты нужно еще где-то хранить. Для операций чтения и записи нужны дополнительные регистры и достаточно скоростная кэш-память.
Может ли с этой задачей справиться CPU? Вообще-то, да. Специально для таких вычислений в процессорах начали появляться инструкции MMX, SSE и (самые совершенные) AVX. Однако видеокарты с их многочисленными CUDA-ядрами — более предпочтительный вариант. Они могут распараллелить большую часть простых операций сложения и умножения. Но даже для них задача просчета матриц оставалась трудоемкой. Решением стали тензорные ядра.
Одно такое ядро способно перемножить две матрицы за один такт. В то время как CUDA-ядрам требуется несколько тактов.
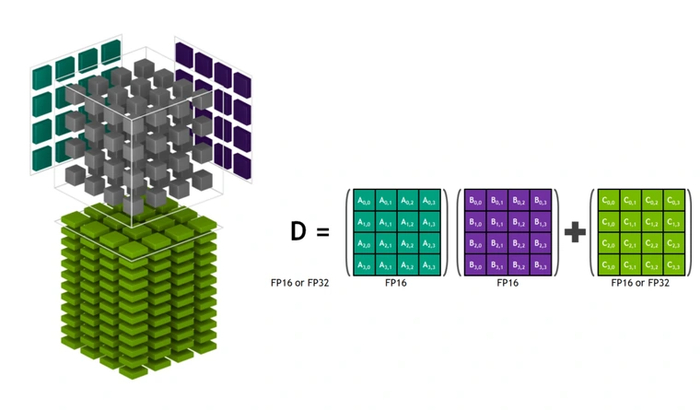
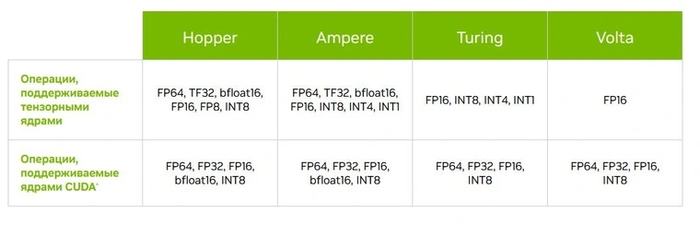
Первое тензорное ядро представляло собой микроблок, выполнявший суммирование-произведение матриц 4x4. Могли использоваться значения FP16 (числа с плавающей запятой размером 16 бит) или умножение FP16 с добавлением FP32.
Размерность рабочих матриц невелика. Ядра при обработке реальных наборов данных обрабатывают небольшие блоки более крупных матриц, в итоге формируя окончательный ответ.
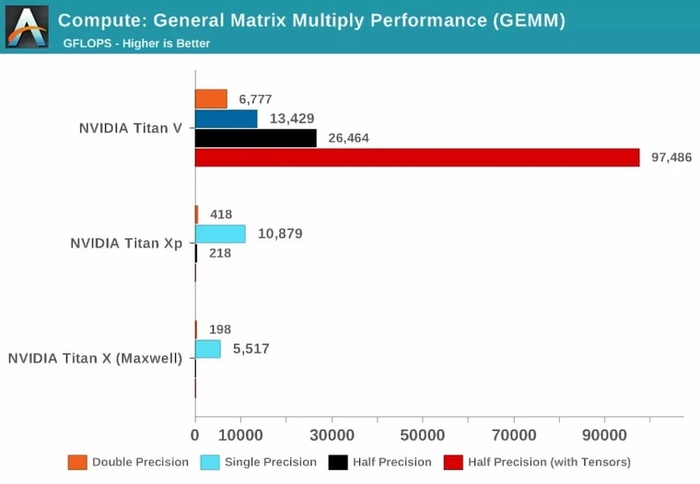
Решение оказалось крайне эффективным. Специалисты из Anandtech провели замеры производительности топовых решений от Nvidia — без тензорных ядер и с ними.
В операциях перемножения матриц (GEMM) прирост производительности с использованием тензорных ядер колоссальный.
Применение тензорных ядер
Научные вычисления
Тензорная математика активно используется в физике и инженерии для решения всех видов сложных вычислений. Например, в механике жидкостей, электромагнетизме, астрофизике, медицине и климатологии. В суперкомпьютерах для этих задач обычно используют крупные кластеры с тысячами высокопроизводительных процессоров уровня Xeon Platinum или AMD Epyc. Однако видеоускорители стали неотъемлемой частью практически любого суперкомпьютера. Подавляющее число машин из рейтинга Top500 работают на базе решений от Nvidia.
Машинное обучение
Задача глубокого обучения в самом простом смысле — это работа с математическими выражениями. Простейший вариант — нейронная сеть, состоящая из одного слоя с двумя нейронами и линейными функциями активации. Представлена она вот таким умножением вектора на матрицу:
Задача обучения сводится к поиску наилучших коэффициентов W. То есть предполагаются матричные операции.
На практике нейросети чаще всего многослойные, и математические выражения получаются куда сложнее. Однако принципиально используются все те же действия — умножение и сложение матриц. Тензорные ядра как раз ориентированы на эти действия.
Самый яркий пример — суперкомпьютер, созданный Microsoft совместно c OpenAI. В нем использовали 10 тысяч графических процессоров Nvidia V100. Именно этот компьютер применили для обучения ChatGPT-3. Продукты Nvidia можно найти в Microsoft Azure, Oracle Cloud и Google Cloud.
Илон Маск для своего ИИ Grok также задействует продукцию Nvidia. Изначально это был кластер на 20 тысяч графических процессоров H100. Недавно для обучения версии GROK 3 миллиардер запустил суперкомпьютер с сотней тысяч NVIDIA H100! Теперь вы можете понять, почему NVIDIA стала самой дорогой компанией и продолжает наращивать прибыль.
Инференс нейросети
Инференс — это запуск уже обученной модели, «скармливание» данных и получение результата. Процесс менее требователен к вычислительной мощности. Но здесь все так же используются матричные операции. Сюда входит распознавание текста (например, в голосовых помощниках), поиск объектов на изображении (распознавание лиц, номерных знаков), шумоподавление и не только.
Тензорные ядра и здесь предлагают высокую производительность. Они позволяют запускать «легкие» нейросети прямо на домашних видеокартах средневысокого ценового сегмента. Например, запустить Chat with RTX — тут достаточно RTX 30 или 40 серии с минимум 8 ГБ видеопамяти. Stable Diffusion также можно запустить локально на видеокартах. Однако производительность каждой модели зависит еще и от ПО. Оно не всегда в полной мере задействует те же тензорные или CUDA-ядра.
DLSS (Deep Learning Super Sampling)
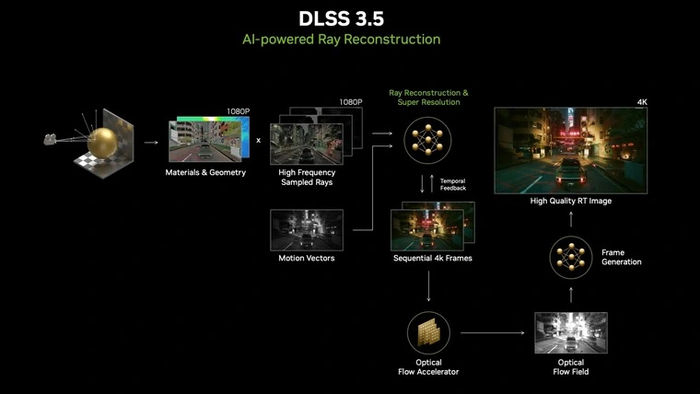
Один из самых доступных вариантов инференса нейросетей — технология DLSS. Специально обученная на игре нейросеть запускается на тензорных ядрах видеокарты, повышая разрешение картинки в реальном времени. Игрок, в свою очередь, получает более высокий FPS. DLSS 3 работает только на видеокартах серии RTX40.
Где имеются тензорные ядра
Nvidia
Поскольку это авторская разработка «зеленых», то именно «тензорные ядра» можно найти лишь в продукции этой компании.
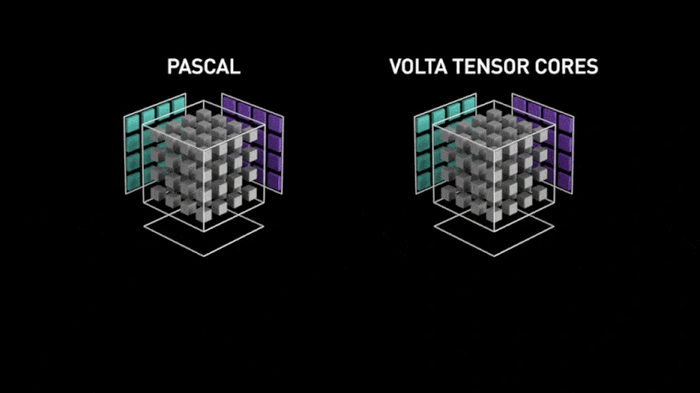
Впервые появились в Nvidia TITAN V в 2017 году — карта имела 640 ядер. После этого ядра стали неотъемлемой частью профессиональных ускорителей
С каждой новой архитектурой появлялось усовершенствованное поколение тензорных ядер. Так что сравнивать их число в рамках разных поколений некорректно. Есть и различия в поддерживаемых форматах данных. Первые ядра могли складывать матрицы с данными только FP16, а современные имеют поддержку куда больших форматов.
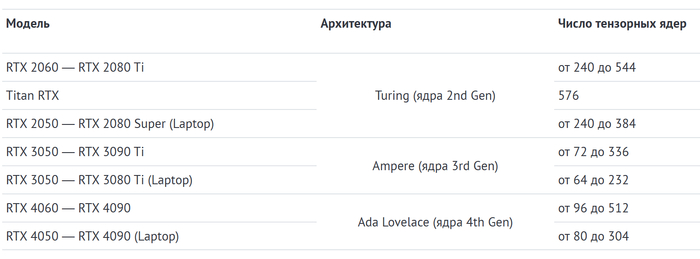
В десктопных и мобильных видеокартах технология стала доступна с приходом серии RTX20.
Именно благодаря тензорным ядрам пользовательские карты RTX можно использовать для работы с нейросетями. А также получить апскейл с использованием ИИ. Альтернативные технологии вроде XeSS и FSR базово специальных ядер не требуют.
AMD
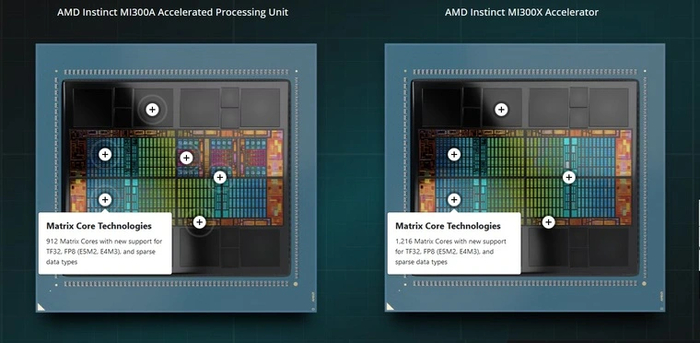
Компания «красных» на рынок ИИ вышла относительно недавно. Аналогом тензорных ядер у них является Matrix Core Technologies, которая появилась в архитектуре CDNA 3.
Ядра Matrix Core Technologies пока встречаются только в AMD Instinct MI300A (912 штук) и MI300X (1216 штук). Новые ИИ-ускорители планируют поставить в немецкие суперкомпьютеры Hunter и Herder — в 2025 и 2027 годах соответственно. Сейчас же у немцев работают суперкомпьютеры Hawk и JUWELS на базе Nvidia A100.
Intel
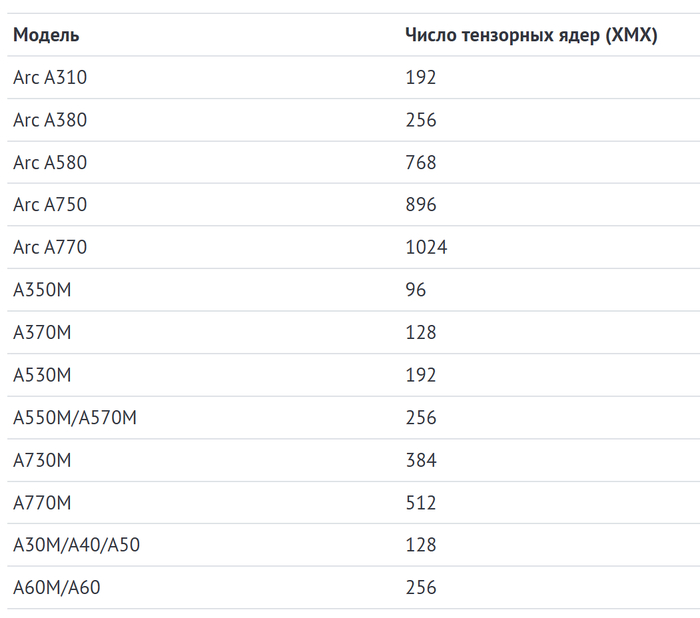
У «синих» используются ядра XMX (Xe Matrix Extensions), созданные специально для матричных вычислений. На них аппаратно работает и фирменный апскейлер Intel XeSS. Встретить ядра XMX можно в линейке видеокарт ARC.
Ядра XMX используются и в Intel Xᵉ HPC 2, установленных в Data Center GPU Max. Графика Xe2-LPG будет встроена в процессоры Lunar Lake. Там также будут использоваться XMX-ядра для задач, связанных с работой ИИ.
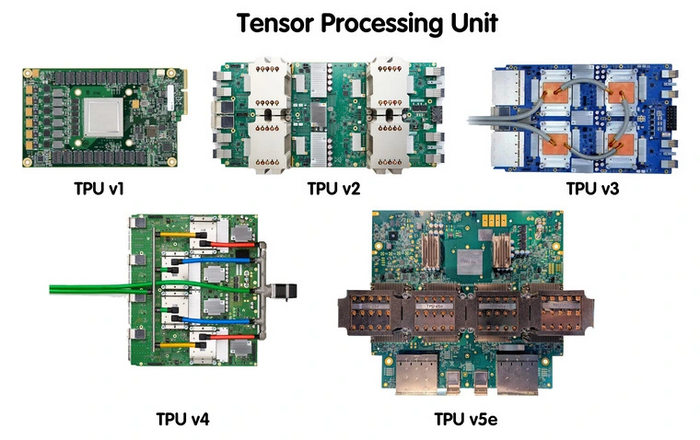
Google
В компании не стали изобретать отдельные ядра, а нацелились сразу же на разработку полноценных плат. Они получили название TPU — Tensor Processing Unit. Эти платы специализируются на обработке матриц. Они подходят как для тренировки, так и выполнения нейросетей.










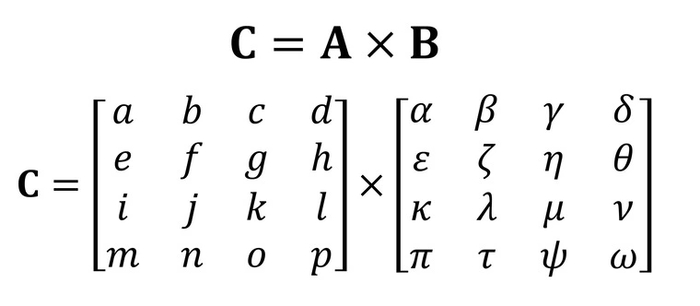
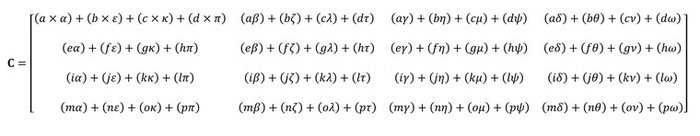


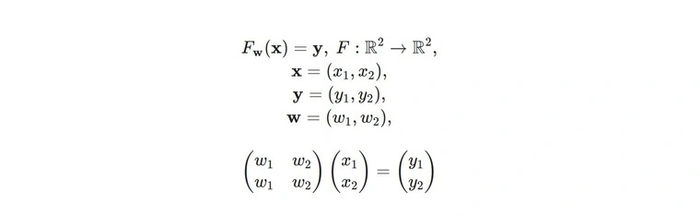







![09.05.1996 — Tux - официальный талисман Linux [вехи_истории] История (наука), Технологии, Linux, Tux, Линус Торвальдс, Open Source, GIMP, Талисман, Ядро, Система, Операционная система, История IT, Программа](https://cs17.pikabu.ru/s/2025/05/06/23/lmnvkiyz.jpg)
