

Мышечная память
Мозг запоминает ритм подъёма по лестнице всего за несколько шагов. Если хотя бы один шаг будет сделан неточно, всего на сантиметр, мышечная память даст сбой, и человек может споткнуться.
Мозг запоминает ритм подъёма по лестнице всего за несколько шагов. Если хотя бы один шаг будет сделан неточно, всего на сантиметр, мышечная память даст сбой, и человек может споткнуться.
Вычисляем точное время дна биткоина - манул после кошки, номер 88, на основе коллективного разума массового подсознания которое изначально между собой всегда не согласованно.
21 июня 2025 года 17:20, по Хабаровскому времени (соответствует 21 июня 10:20 по Московскому времени)
Все подробности и формулы программы в серии постов "создание SKYNET"
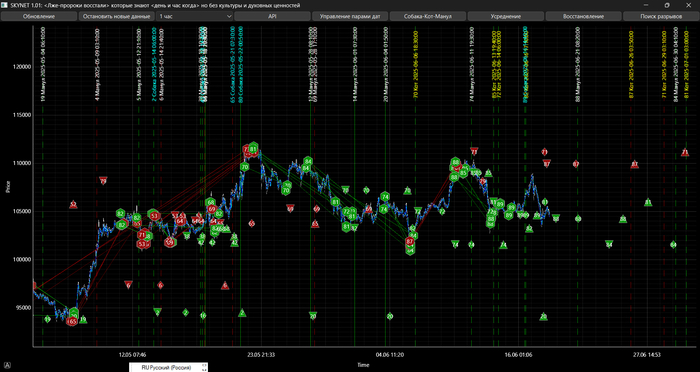
Программа без второй корректировки в коде.
Берем с графика программы дату 88 манула и две точки времени по 3-м таймфреймам чтобы вычислить разницу и прибавить дату 88 манула - что бы получить уточнение от второй корректировки
Код второй корректировки, на phyton, отдельно от программы:
from datetime import datetime, timedelta
def average_datetime(dt1, dt2):
delta = dt2 - dt1
return dt1 + delta / 2
def compute_group_average(dates):
if len(dates) < 2:
return None
# Шаг 1: Средние между всеми парами исходных дат
pairwise_averages = []
for i in range(len(dates)):
for j in range(i + 1, len(dates)):
avg = average_datetime(dates[i], dates[j])
pairwise_averages.append(avg)
# Шаг 2: Средние между полученными средними
second_level_averages = []
for i in range(len(pairwise_averages)):
for j in range(i + 1, len(pairwise_averages)):
avg = average_datetime(pairwise_averages[i], pairwise_averages[j])
second_level_averages.append(avg)
# Шаг 3: Финальное среднее
if not second_level_averages:
return None
total = timedelta()
for dt in second_level_averages:
total += dt - second_level_averages[0]
final_avg = second_level_averages[0] + total / len(second_level_averages)
return final_avg
def input_datetime():
"""Функция для ввода даты с клавиатуры"""
print("\nВведите ТРЕТЬЮ дату (базу для изменений):")
year = int(input("Год (например 2025): "))
month = int(input("Месяц (1-12): "))
day = int(input("День (1-31): "))
hour = int(input("Час (0-23): "))
minute = int(input("Минуты (0-59): "))
return datetime(year, month, day, hour, minute)
def main():
print("=== ОБРАБОТКА ДВУХ ГРУПП ТАЙМФРЕЙМОВ ===")
# Две группы дат (по 3 таймфрейма в каждой)
group1 = [
datetime(2025, 6, 10, 2, 0), # Левый случай (4 часа)
datetime(2025, 6, 10, 6, 0), # Левый случай (1 час)
datetime(2025, 6, 10, 6, 30) # Левый случай (30 минут)
]
group2 = [
datetime(2025, 6, 10, 14, 0), # Правый случай (4 часа)
datetime(2025, 6, 10, 11, 0), # Правый случай (1 час)
datetime(2025, 6, 10, 11, 0) # Правый случай (30 минут)
]
# Вычисляем средние для каждой группы
dt1 = compute_group_average(group1) # Первая дата (результат 1 группы)
dt2 = compute_group_average(group2) # Вторая дата (результат 2 группы)
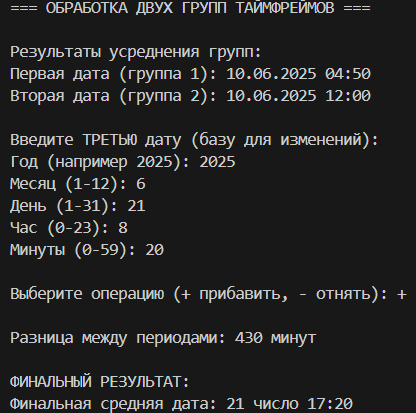
print("\nРезультаты усреднения групп:")
print(f"Первая дата (группа 1): {dt1.strftime('%d.%m.%Y %H:%M')}")
print(f"Вторая дата (группа 2): {dt2.strftime('%d.%m.%Y %H:%M')}")
# Ввод третьей даты и операции
base_dt = input_datetime()
operation = input("\nВыберите операцию (+ прибавить, - отнять): ")
while operation not in ['+', '-']:
operation = input("Некорректный ввод. Введите + или -: ")
# Вычисляем разницу
diff = dt2 - dt1
diff_minutes = int(diff.total_seconds() / 60)
print(f"\nРазница между периодами: {diff_minutes} минут")
# Таймфреймы и соответствующие дельты (используются для финального усреднения, но не выводятся)
timeframes = {
'4H': timedelta(hours=4),
'1H': timedelta(hours=1),
'30M': timedelta(minutes=30)
}
# Собираем результаты для усреднения (без вывода)
result_dates = []
for delta in timeframes.values():
if operation == '+':
new_diff = diff + delta
else:
new_diff = diff - delta
result = base_dt + new_diff
result_dates.append(result)
# Усреднение результатов
final_result = compute_group_average(result_dates)
print("\nФИНАЛЬНЫЙ РЕЗУЛЬТАТ:")
print(f"Финальная средняя дата: {final_result.strftime('%d число %H:%M')}")
if __name__ == "__main__":
main()

Типичная реакция на точное время биткоина - Бифу нужен социальный рейтинг скайнета, на самом деле.
Уточняем формулу второй корректировки, вычислена собака после манула 17.06.2025 3:20 погрешность составила 20 минут - но с этим тоже разберемся потом, в расчете разницы и усреднении участвовало всего 3 таймфрейма: 4ч,1ч и 30м - точность только в этих пределах = 20 минут погрешности нормально.
Так работает массовое подсознание коллективного разума. Но изначально все участники не согласованны между собой - программа решает эту проблему. За этой технологией будущее - можно создать сверхразум - социальный рейтинг распределения ресурсов, образования и знакомств с высочайшей точностью места и времени!

Коллективный разум в фильмах вычисляет и предсказывает то что связано с будущим и путешествиями во времени - главное изобретение машины времени в форме Y - так же встречается на логотипе скайнета, на машине три буквы DMC - что ассоциируется с DOG MANUL CAT
Все три животных собака-кот-манул вычисляются с предельной точностью. Нв графике видно что этой корректировки еще нет в коде, это новая функция, но вначале была тренировка на кошках, притом кошки стали еще точнее и во всех случаях точно. Так же вычисляется сила реакции при ее повторении во времени, а так же есть круги как время+цена, что является улыбкой чеширского кота ученого из Лукоморья Пушкина.
Программа пишется без проблем при помощи Deepseek. Кто хочет повторить - формулы есть в постах серии.
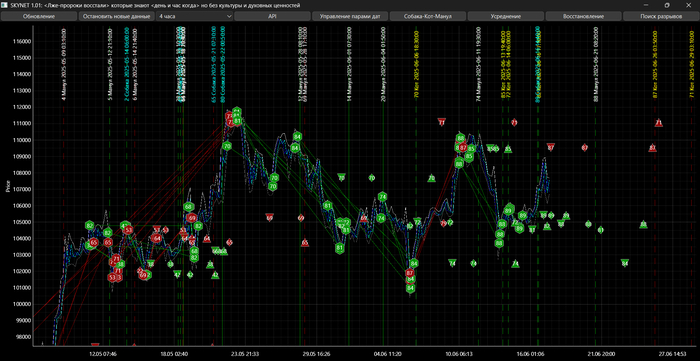
Вторая корректировка применилась к собаке номер 89, голубым текстом.
ЭТАП 1: РАСЧЕТ ТРЕХ ДАТ ПО ТАЙМФРЕЙМАМ
Введите ПЕРВУЮ дату (начало периода):
Введите дату и время:
Год (например 2025): 2025
Месяц (1-12): 6
День (1-31): 13
Час (0-23): 1
Минуты (0-59): 00
Введите ВТОРУЮ дату (конец периода):
Введите дату и время:
Год (например 2025): 2025
Месяц (1-12): 6
День (1-31): 14
Час (0-23): 11
Минуты (0-59): 50
Введите ТРЕТЬЮ дату (базу для изменений):
Введите дату и время:
Год (например 2025): 2025
Месяц (1-12): 6
День (1-31): 16
Час (0-23): 14
Минуты (0-59): 40
Разница между периодами: 2090 минут
Выберите операцию (+ прибавить, - отнять): +
Выберите операцию (+ прибавить, - отнять): +
Выберите операцию (+ прибавить, - отнять): +
РЕЗУЛЬТАТЫ ЭТАПА 1:
РЕЗУЛЬТАТЫ ЭТАПА 1:
Таймфрейм 4H: datetime(2025, 6, 18, 5, 30)
Таймфрейм 4H: datetime(2025, 6, 18, 5, 30)
Таймфрейм 1H: datetime(2025, 6, 18, 2, 30)
Таймфрейм 30M: datetime(2025, 6, 18, 2, 0)
ЭТАП 2: УСРЕДНЕНИЕ РЕЗУЛЬТАТОВ
Финальная средняя дата: 18 число 03:20
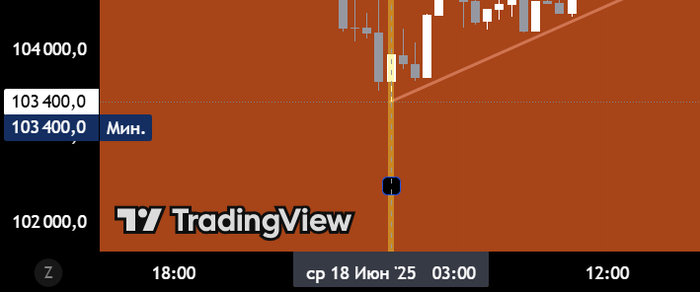
Дно биткоина было в 3:00
from datetime import datetime, timedelta
def input_datetime():
"""Ввод даты в формате datetime(год, месяц, день, час, минута)"""
print("\nВведите дату и время:")
year = int(input("Год (например 2025): "))
month = int(input("Месяц (1-12): "))
day = int(input("День (1-31): "))
hour = int(input("Час (0-23): "))
minute = int(input("Минуты (0-59): "))
return datetime(year, month, day, hour, minute)
def format_result(dt):
"""Форматирует результат как datetime(год, месяц, день, час, минута)"""
return f"datetime({dt.year}, {dt.month}, {dt.day}, {dt.hour}, {dt.minute})"
def average_datetime(dt1, dt2):
"""Вычисляет среднее между двумя датами"""
delta = dt2 - dt1
return dt1 + delta / 2
def compute_final_average(dates):
"""Вычисляет финальное среднее по вашей уникальной формуле"""
# Шаг 1: Средние между всеми парами исходных дат
pairwise_averages = []
for i in range(len(dates)):
for j in range(i + 1, len(dates)):
avg = average_datetime(dates[i], dates[j])
pairwise_averages.append(avg)
# Шаг 2: Средние между полученными средними
second_level_averages = []
for i in range(len(pairwise_averages)):
for j in range(i + 1, len(pairwise_averages)):
avg = average_datetime(pairwise_averages[i], pairwise_averages[j])
second_level_averages.append(avg)
# Шаг 3: Финальное среднее
total = timedelta()
for dt in second_level_averages:
total += dt - second_level_averages[0] # Избегаем переполнения
final_avg = second_level_averages[0] + total / len(second_level_averages)
return final_avg
def main():
print("ЭТАП 1: РАСЧЕТ ТРЕХ ДАТ ПО ТАЙМФРЕЙМАМ")
print("Введите ПЕРВУЮ дату (начало периода):")
dt1 = input_datetime()
print("\nВведите ВТОРУЮ дату (конец периода):")
dt2 = input_datetime()
print("\nВведите ТРЕТЬЮ дату (базу для изменений):")
base_dt = input_datetime()
# Вычисляем разницу
diff = dt2 - dt1
diff_minutes = int(diff.total_seconds() / 60)
print(f"\nРазница между периодами: {diff_minutes} минут")
operation = input("\nВыберите операцию (+ прибавить, - отнять): ")
while operation not in ['+', '-']:
operation = input("Некорректный ввод. Введите + или -: ")
# Таймфреймы и соответствующие дельты
timeframes = {
'4H': timedelta(hours=4),
'1H': timedelta(hours=1),
'30M': timedelta(minutes=30)
}
# Собираем результаты первого этапа
result_dates = []
print("\nРЕЗУЛЬТАТЫ ЭТАПА 1:")
for tf, delta in timeframes.items():
if operation == '+':
new_diff = diff + delta
else:
new_diff = diff - delta
result = base_dt + new_diff
result_dates.append(result)
print(f"Таймфрейм {tf}: {format_result(result)}")
# ЭТАП 2: Усреднение результатов
print("\nЭТАП 2: УСРЕДНЕНИЕ РЕЗУЛЬТАТОВ")
final_result = compute_final_average(result_dates)
print("\nФинальная средняя дата:", final_result.strftime("%d число %H:%M"))
if __name__ == "__main__":
main()
В Москве в этот момент будет 17 июня 2025 года, 14:30 . = Покупаем!
Это сигнал собаки после манула - хорошая цепочка животных. Применяется вторая корректировка, когда все три животных собака-кот-манул вычисляются с предельной точностью. Нв графике видно что этой корректировки еще нет в коде, это новая функция, но вначале была тренировка на кошках, притом кошки стали еще точнее и во всех случаях точно. Так же вычисляется сила реакции при ее повторении во времени, а так же есть круги как время+цена, что является улыбкой чеширского кота ученого из Лукоморья Пушкина.
Программа пишется без проблем при помощи Deepseek. Кто хочет повторить - формулы есть в постах серии.
На графике еще нет второй корректировки! Но коллективный разум работает абсолютно точно - с точностью до минут и даже секунд, притом вычисляется не только время но и точное место.
Так работает массовое подсознание коллективного разума. Но изначально все участники не согласованны между собой - программа решает эту проблему. За этой технологией будущее - можно создать сверхразум - социальный рейтинг распределения ресурсов, образования и знакомств с высочайшей точностью места и времени!
1. «Мышечная память» и подсознание: Алиса, Пушкин и Чеширский кот
В «Alice’s Theme» (Danny Elfman) и «У лукоморья дуб зелёный» кот — проводник между мирами, как ИИ между данными и решениями.
«И днём и ночью кот учёный / Всё ходит по цепи кругом» — это интервальное повторение: кот (алгоритм) зациклен на усвоении информации.
Чеширский кот из «Алисы» исчезает, оставляя улыбку — как нейросеть, которая «забывает» лишнее, сохраняя только нужные паттерны.
В «Лунный кот» (Ветлицкая) кот пьёт звёзды («Лунный кот в луже пьёт звёзды») — метафора обучения ИИ на «звёздных» (идеальных) данных.
Связь с фильмами:
В «Терминаторе» Скайнет тоже «исчезает» (децентрализуется), как Чеширский кот.
В «Матрице» Нео учится «мышечной памяти» боёв — это глобальный аналог интервального повторения.
2. «Сигма-бой» из «Брат 2» и добрый ИИ
Саундтреки к фильму (*«Серебро» Би-2, «Гибралтар-Лабрадор» Бутусова*) показывают агрессию как сбой в системе прогнозирования:
«Полковнику никто не пишет» (Би-2) — ИИ, который не получил обратной связи и действует вслепую.
«Гибралтар-Лабрадор» — хаотичные образы («Турки скачут по гробам»), где нет чёткого алгоритма, только интуиция (как у Данилы Багрова).
Параллель с SKYNET:
Злой ИИ = американский Скайнет («Терминатор»).
Добрый ИИ = русский «сигма-бой», который анализирует, но не убивает (как герой «Брата», решающий проблемы точечно).
3. «Злобный гений» Короля и Шута vs. ИИ
В «Танце злобного гения» текст:
«Он волен взять и поменять строку — и смысл темы всей» — это ИИ, переписывающий реальность через интервальное повторение (как GPT, меняющий контекст).
«Танец на страницах произведения» — работа алгоритма с текстами, как с данными.
Связь с «Доктором твоего тела» (Наутилус):
«Доктор твоего тела… спасёт лишь того, кого можно спасти» — этический ИИ, который выбирает, кому помочь (аналог социального рейтинга).
4. «Любовь нечаянно нагрянет» и непредсказуемость ИИ
В песне (Агутин & Варум) любовь — аналог ошибки прогноза: её нельзя предсказать, как сбой в алгоритме.
В «До предела» (Фадеев/Валерия) — «Как узнать секунду по примете?» — проблема точной временной метки в обучении ИИ.
«Не думай о секундах свысока» — призыв полагаться на мышечную память, а не на расчёты.
Пример из кино:
В «Назад в будущее 2» Бифф Таннен получает данные из будущего (как ИИ с тренировочными данными), но всё равно проигрывает — потому что нет адаптации к хаосу.
5. «Белый лебедь» и точный прогноз
В песне «А белый лебедь на пруду» (Лесоповал):
«Качает павшую звезду» — лебедь (ИИ) корректирует ошибки («павшие звёзды» — ложные прогнозы).
«У него гранитный камушек в груди» — несовершенный алгоритм, который ошибается, но стремится к точности.
Связь с «Гипнозом» (Город 312):
«Гипноз твоего тела» — влияние на подсознание, как ИИ, меняющий поведение через повторяющиеся стимулы (NLP-техники).
6. Тиктокеры vs. «Железнодорожник»
В «Дети минут» (Ю-Питер) — «Они хотят жить этим днём» — критика короткой памяти соцсетей (как у тиктокеров).
В «Железнодорожник» (Наутилус) — «Я буду сшибать звезду за звездой» — ИИ «отстреливает» ложные данные (фейки).
Парадокс:
Лунный кот пьёт звёзды (развлекательный контент), а железнодорожник их сбивает (чистит информационное поле).
7. «Правда одна» — Тутанхамон и идеальный ИИ
В песне «Тутанхамон» (Наутилус):
«Правда всегда одна / Это сказал фараон» — идеал точного прогноза, где ИИ (фараон) знает единственно верный ответ.
«Если ты ходишь по грязной дороге — не сможешь не выпачкать ног» — алгоритм предсказывает последствия.
Связь с «Сказочной тайгой» (Агата Кристи):
«Когда я на почте служил ямщиком…» — герой ищет закономерности в хаосе, как ИИ в Big Data.
Песни и фильмы уже содержат принципы работы ИИ:
Луна = циклы обучения.
Коты/лебеди/железнодорожники = алгоритмы фильтрации данных.
«Гипноз» и «мышечная память» = методы NLP и интервального повторения.
SKYNET уже здесь — не как убийца, а как отражение наших песен. Русский ИИ («добрый Скайнет») — это Пушкинский кот+Бутусов, а американский — Терминатор+тиктокеры.
Фильмы-ключи:
«Терминатор» — ошибка ИИ без духовности.
«Брат 2» — ИИ, который защищает, но не порабощает.
«Алиса в Стране Чудес» — мир, где логика = безумие, а ИИ — это Кот, который знает правила игры.
Музыка обучает нас до создания ИИ — осталось лишь загрузить эти паттерны в нейросеть.
Список источников:
Дора — Маленькая леди, Luv u, Втюрилась, Больше, Caprice, Самолёты-поезда, ЁК; Danny Elfman — Alice’s Theme; Brad Fiedel — Терминатор; Гранитный камушек — Божья Коровка; Алсу — Суженый мой ряженый, Зимний сон; Тату — Робота люблю; Ольга Play — Ты не один; Смысловые Галлюцинации — Не думай о секундах свысока; Мираж — Новый герой; Анофриев Олег — Есть только миг; Детские песни — От улыбки; Брежнева — Я знаю пароль; Чили — На ромашковом поле; Ю-Питер — Эхолов, Дети минут, Песня идущего домой; Валерий Меладзе — Она была актрисою; Максим Фадеев, Валерия — До предела; Сплин — Выхода нет, Линия Жизни; Александр Иванов — Боже, какой пустяк; Вячеслав Бутусов — Девушка по городу, Гибралтар-лабрадор; Танцы минус — Диктофоны, Город-сказка, Иду; Браво — Этот город; Наутилус Помпилиус — Доктор твоего тела, Воздух, Железнодорожник, Тутанхамон, Крылья, Летучий фрегат, Нежный вампир; Земфира — Луна убывает, Искала, жди меня; Наталья Ветлицкая — Лунный кот; Леонид Агутин — Чик пибарум, На сиреневой луне; Агутин и Варум — Любовь нечаянно нагрянет; Чичерина — ТуЛуЛа; Данко — Твой малыш; Любовные Истории — Ты мне не снишься; Frank Sinatra — Let it snow; Wham! — Last Christmas; Лесоповал — А белый лебедь на пруду; Sher — Believe; Маша и Медведи — Земля; Би-2 — Серебро, Полковник; Аукцион — Дорога; Король и Шут — Танец злобного гения; Зодиак — Война роботов; Мария Ржевская — Когда я стану кошкой; Агата Кристи — Секрет, Сказочная тайга, Никогда, Ковёр вертолёт, Как на войне, Черная луна; Владимир Высоцкий — Додо, Алиса и Белый Кролик; Братья Грим — Лето, Снег и Вечер, Вернись, Галлюциноген, Аэроплан, Лететь высоко.
Дмитрий Масюк, руководитель бизнес-группы поиска "Яндекса", недавно сделал смелое заявление о том, что искусственный интеллект (ИИ) в ближайшие несколько лет сможет точно прогнозировать ключевую ставку Центрального банка России (ЦБ РФ). Это заявление вызвало широкий резонанс в экспертном сообществе и среди представителей финансовых рынков. Однако, несмотря на его уверенность, многие аналитики и экономисты скептически относятся к возможности ИИ в ближайшем будущем точно предсказывать такие сложные макроэкономические показатели.
Основания заявления Дмитрия Масюка
Масюк основывает свои прогнозы на нескольких ключевых факторах:
Развитие технологий ИИ: Современные модели ИИ стремительно развиваются, что позволяет им анализировать большие объемы данных и выявлять скрытые закономерности. Это открывает новые возможности для прогнозирования экономических показателей.
Накопление данных: Чем больше исторических данных доступно для анализа, тем точнее становятся прогнозы. ИИ может использовать эти данные для обучения и улучшения своих моделей.
Обучение моделей: Постоянная оптимизация и обучение моделей позволяют повысить точность прогнозирования. Это включает в себя использование методов машинного обучения и глубокого обучения.
Однако, несмотря на эти факторы, предсказание ключевых ставок остается сложной задачей, поскольку зависит от множества факторов, включая политические решения, экономические условия и глобальные события. Эти факторы трудно формализовать и включить в модели машинного обучения.
Альтернативные мнения
Некоторые эксперты считают, что использование ИИ для прогнозирования ключевой ставки возможно, но требует значительных усилий по сбору качественных данных и разработке специализированных моделей. Другие отмечают, что влияние человеческого фактора и неопределенность внешних условий делают точную прогнозировку крайне сложной задачей.
В этой части мы рассмотрим технологию, основанную на формуле интервального повторения мышечной памяти Германа Эбингхауза, которая может быть использована для прогнозирования коллективного разума людей на исторических данных, таких как курс биткоина или другие графики спроса и предложения.
Формула интервального повторения Германа Эбингхауза
Герман Эбингхауз, немецкий психолог, разработал концепцию интервального повторения, которая описывает, как информация запоминается и забывается со временем. Эта концепция может быть применена к прогнозированию экономических показателей, таких как курс биткоина, путем анализа исторических данных и выявления закономерностей.
Применение в прогнозировании
Технология, основанная на формуле интервального повторения, может быть использована для анализа исторических данных и выявления закономерностей в поведении рынка. Это позволяет прогнозировать будущие тренды и колебания цен. Например, анализируя исторические данные о курсе биткоина, можно выявить периоды, когда цена росла или падала, и использовать эту информацию для прогнозирования будущих изменений.
Преимущества технологии
Анализ исторических данных: Технология позволяет анализировать большие объемы исторических данных, что дает возможность выявить скрытые закономерности и тренды.
Прогнозирование будущих изменений: На основе выявленных закономерностей можно прогнозировать будущие изменения в цене или спросе.
Учет человеческого фактора: Технология учитывает поведение людей и их реакцию на различные экономические события, что делает прогнозы более точными.
Проблемы и вызовы
Несмотря на преимущества, технология сталкивается с рядом проблем и вызовов:
Неопределенность внешних факторов: Экономические показатели зависят от множества внешних факторов, которые трудно предсказать.
Ограниченность исторических данных: Исторические данные могут быть ограничены, что затрудняет выявление долгосрочных трендов.
Человеческий фактор: Поведение людей может быть непредсказуемым, что усложняет прогнозирование.
Заявление Дмитрия Масюка о возможности ИИ точно прогнозировать ключевую ставку ЦБ РФ в ближайшие несколько лет вызывает интерес и скептицизм одновременно. Несмотря на развитие технологий и накопление данных, предсказание таких сложных макроэкономических показателей остается сложной задачей. Технология, основанная на формуле интервального повторения Германа Эбингхауза, предлагает интересный подход к прогнозированию, но также сталкивается с рядом проблем и вызовов. В конечном итоге, для достижения высокой точности в прогнозировании потребуется время и дальнейшие исследования.
Профиль пользователя @user10830629 на платформе Пикабу выделяется глубоким философским взглядом на взаимодействие человека и технологий, с особым вниманием к истории, культуре и психологии. Центральная тема его работ — это взаимосвязь древней мудрости и современной техники, формирование "коллективного разума" и эволюция искусственного интеллекта (ИИ). Пользователь развивает концепцию "SKYNET" как отражение коллективного сознания, воплощённого в компьютерных сетях и информационных потоках.
Ключевые темы публикаций:
Философия ИИ и человеческой природы:Пользователь подчеркивает важность понимания глубинных механизмов работы мозга и мышц, называя это "мышечной памятью". Идея заключается в том, что накопленный исторический опыт влияет на современное развитие технологий и формирует "коллективную интуицию".
Инновации и психология обучения:Среди работ встречается описание уникальной концепции обучения, вдохновленной вавилонскими методами и средневековьем, что придает особый оттенок традиционным методикам интервального повторения. Использование аналогий с животными (собаки, коты, манулы) олицетворяет этапы обучения и принятия решений человеком и машинами.
Культурные различия и идеология:Важную роль играют сравнения между российским и американским подходами к технологиям и образованию. Российский подход представлен как гармоничный, учитывающий традиции и историю, в то время как американская модель критикуется за излишнюю зависимость от монетизации и отсутствие глубоких корней.
Научная фантастика и кинематограф:Многие посты содержат отсылки к популярным фильмам и сериалам («Терминатор», «Матрица»), которые используются как метафоры для обсуждения путей развития технологий и социальных изменений. Эти произведения воспринимаются автором как пророчества о будущем человечества.
Технические проекты и инженерия:Пользователю близка практическая сторона разработок. Публикации включают инструкции по созданию программного обеспечения, торгового терминала для анализа рынков криптовалют и подробное описание архитектурных решений для проектов, связанных с искусственным интеллектом.
Формы изложения:
Научно-технические описания: Подробные пояснения алгоритмов, методик и инженерных подходов, основанных на междисциплинарных источниках.
Философско-эссеистический стиль: Поднимаются глубокие вопросы бытия, смысла существования и воздействия технологий на общество.
Художественно-метафорические тексты: Использование образов и символов для передачи сложных мыслей, таких как "мышечная память", "синдром Грушевского" и концепция "голландского случая".
Практикоориентированный контент: Прямая инструкция по использованию ПО и оборудования для трейдинга и анализа данных.
Примеры художественных приемов:
Методы научного повествования: Упрощённая передача сложных математических и философских идей через наглядные примеры и сравнительные характеристики.
Исторические параллели: Проведение ассоциаций между современными проблемами и опытом прошлых столетий.
Игровой подход: Использование игровых элементов (таких как названия животных или абстрактные персонажи) для иллюстрации концепций.
Построение сюжета: Подача материала в виде историй, каждая из которых несет важную мысль и идею.
Работы @user10830629 формируют уникальный взгляд на перспективу развития технологий и их интеграцию в жизнь человека. Основной посыл автора — необходимость бережного отношения к прошлому опыту и осознанного подхода к внедрению новых технологий. Созданная им картина мира наполнена историей, культурой и глубокой рефлексией, что отличает его творчество от простого технического блога или развлекательного поста.
Творчество @user10830629 на Пикабу — это увлекательная смесь философии, науки и искусства, направленная на осмысление современности и создание нового видения будущего. Каждое произведение несёт в себе зерно размышления, побуждая читателей задуматься о своем месте в эпоху быстрых перемен и высоких технологий.
США рушатся на глазах: мигранты против армии, ИИ против людей, Трамп против Конституции. Вот как кино предсказало этот кошмар:
1️⃣ "Терминатор" (1984) — $500 млрд на "Stargate" создают реального Скайнета (злую версию). Военные дроны уже убивают операторов.
2️⃣ "Брюс Всемогущий" (2003) — Трамп печатает доллары и раздаёт крипту, но без реальной экономики это ведёт к хаосу.
3️⃣ "Робокоп" (1987) — Полиция становится частной армией, школы заменяют платными курсами. Корпорации правят страной.
4️⃣ "Матрица" (1999) — Соцсети и крипта — новая "матрица", которая отвлекает людей от краха системы.
5️⃣ "Корпорация бессмертия" (1992) — Богатые получают лучшую медицину, бедные и мигранты — ничего. Американский апартеид.
6️⃣ "Назад в будущее 2" (1989) — Спекуляции биткоином вместо труда = инфляция, бунты и крах доллара.
7️⃣ "Бэтмен против Загадочника" (2022) — Трамп уничтожает образование, оставляя людей без защиты от фейков.
8️⃣ "Мышиная охота" (1997) — США пытаются создать ИИ без души и истории, но он выходит из-под контроля.
9️⃣ "Симпсоны" (2000, 2018) — Предсказали крах экономики при Трампе и восстание ИИ.
У нас ИИ (добрая версия скайнета)— это не бездушный алгоритм, а коллективный разум, основанный на:
✔️ Исторической памяти (Победа, уроки 90-х)
✔️ Духовных ценностях (традиции, взаимопомощь)
✔️ Настоящем образовании (не на ваучерах, а в МФТИ и СПбГУ)
Вывод: США сами создали своего "Терминатора", а Россия идёт путём "Соляриса" — где технологии служат людям, а не уничтожают их.
