Имеется AD два КД основной и резервный, NS и NS1 соответственно. Оба КД крутятся на virtualbox, гипервизоры физически на разных машинах. Всё это тихо-мирно работало 3 года пока в один прекрасный момент, после суточного блэкаута система выдала мне "время на КД не синхронизировано". С хостом виртуалки не синхронизируется, VB по моему не очень это умеет. Прописал в GPO конкретно для PDC, ситуация не изменилась. Снес к херам все ветки реестра касающиеся службы времени, прописал параметры вручную, ситуация не изменилась. Через какой-то отрезок времени PDC сообщает: "Служба времени обнаружила разницу во времени, превышающую 5000 мсек. в течение 900 сек..." и соответственно отключается из процесса.
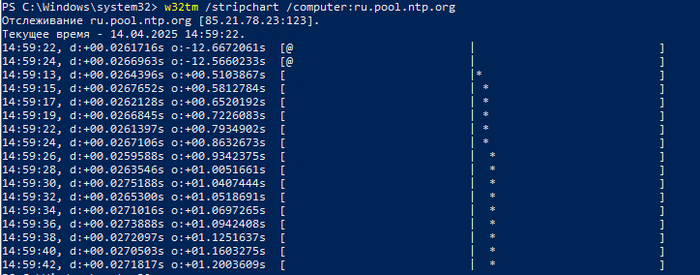
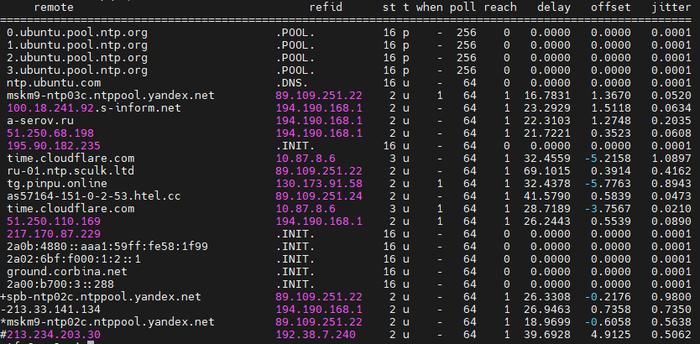
проверяем время на PDC
отстают
w32tm /resync && w32tm /stripchart /computer:ru.pool.ntp.org и наблюдаем следующую картину
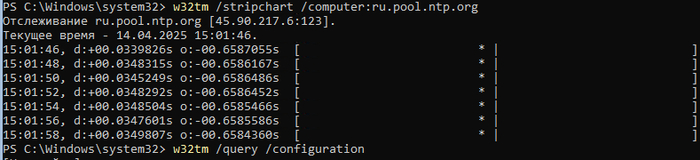
на резервном КД время идет точно
ну почти
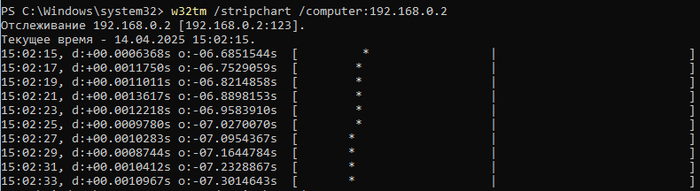
а вот вид с резервного КД на PDC
Проблема именно в том что время на PDC плавает, с чем это связано не понимаю хоть убей.
Что с этим делать а? Переводить PDC на другую машину или можно починить.
з.ы. админ не настоящий клавиатуру на стройке нашел.
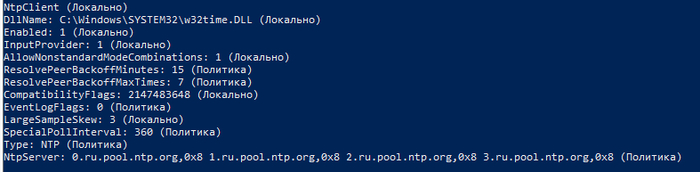
UPD: специально для не умеющих читать для советчиков замены батарейки и синхронизации с хостом.
В области оптимизации производительности Linux важнейшим фактором является производительность дискового ввода-вывода (I/O), которая существенно влияет на общую эффективность системы. Одним из ключевых параметров, влияющих на производительность дискового ввода-вывода, является максимальный размер I/O-запроса, определяемый параметром max_sectors_kb. Понимание и настройка этого параметра могут привести к значительному улучшению производительности системы. В этой статье мы рассмотрим понятие максимального размера I/O, его важность в системах Linux, а также его влияние на производительность в целом.
Параметр max_sectors_kb определяет максимальный размер отдельного I/O-запроса в килобайтах. Он устанавливает объём данных, который может быть передан в рамках одного I/O-запроса. Значение параметра max_sectors_kb ограничено логическим размером блока файловой системы и аппаратными возможностями устройства хранения данных. Оно не может быть меньше логического размера блока, делённого на 1024, и не должно превышать значение параметра max_hw_sectors_kb, который является параметром только для чтения и показывает максимально поддерживаемый аппаратурой размер запроса.
Минимальное значение = max(1, logical_block_size/1024)
Максимальное значение = max_hw_sectors_kb
Примечание: Максимальный размер I/O в Linux преимущественно применим к ядрам версии 4.x и выше. Рекомендуется проверить это в конкретном ядре вашей системы. Хотя впрочем очевидно - если у вас не какой-нибудь embedded, то ядро скорее всего будет выше 5.x
Важность в системах Linux
В Linux параметр максимального размера I/O существенно влияет на эффективность чтения и записи данных с устройств хранения. Он оказывает влияние на следующие аспекты производительности:
1. Баланс между пропускной способностью и задержками:
Пропускная способность (Throughput): Крупные размеры I/O-запросов увеличивают общую пропускную способность ввода-вывода за счёт обработки больших блоков данных за одну операцию. Это снижает накладные расходы на обработку множества мелких запросов, особенно эффективно при работе с последовательными потоками данных (видеостриминг, резервные копии баз данных).
Задержки (Latency): В то время как большие размеры I/O-запросов могут повысить пропускную способность для больших наборов наборов, они также могут увеличить задержку отдельных операций. Это происходит потому, что более крупные запросы требуют больше времени для завершения. Поэтому необходим баланс между улучшением производительности и допустимым уровнем задержек, особенно в чувствительных к задержкам интерактивных или real-time приложениях. В таких случаях предпочтительнее меньшие размеры запросов.
2. Использование CPU:
Увеличение размера запросов уменьшает нагрузку на CPU, поскольку снижается число переключений контекста и прерываний, связанных с обработкой отдельных запросов ввода-вывода.
3. Использование памяти:
Максимальный размер I/O влияет на объём выделяемой памяти под буферы ввода-вывода, что также отражается на общем использовании памяти системой.
Факторы, влияющие на максимальный размер I/O
Есть несколько факторов, которые влияют на максимальный размер запросов в Linux:
Аппаратные ограничения: Значение max_sectors_kb не должно превышать аппаратные возможности накопителя (значение параметра max_hw_sectors_kb). Превышение аппаратного лимита может привести к ошибкам или снижению производительности.
Драйверы устройств: Драйверы контроллеров хранения и накопителей могут задавать свои лимиты на размер запросов.
Ограничения файловых систем: У разных файловых систем разные лимиты на размер запроса ввода-вывода.
Параметры ядра Linux: Настройки блочных устройств ядра влияют на размер запроса.
Бенчмаркинг и мониторинг
Для определения оптимального размера I/O-запросов необходимо проводить тестирование (бенчмарки) и мониторить показатели производительности (например, с помощью утилиты iostat).
Рекомендуется учитывать:
Red Hat советует, чтобы значение max_sectors_kb было кратно оптимальному размеру I/O и внутреннему размеру блока стирания устройства. Если таких данных нет, рекомендуется выставить значение, совпадающее с логическим размером блока устройства.
Характеристики рабочей нагрузки: разные приложения выигрывают от разных размеров I/O.
Особенности накопителя: HDD и SSD имеют разные оптимальные диапазоны размеров I/O.
Ресурсы системы: доступная память и мощность CPU влияют на выбор оптимального размера I/O.
Практические аспекты настройки
Для настройки max_sectors_kb используется команда:
/sys/block/{device}/queue/max_sectors_kb
Например:
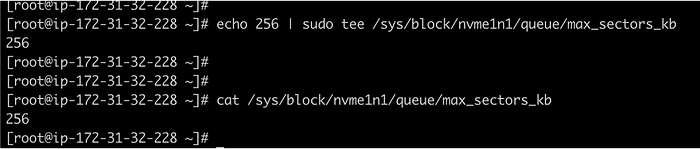
echo 256 | sudo tee /sys/block/sda/queue/max_sectors_kb
Данная команда устанавливает максимальный размер запроса в 256 КБ для диска /dev/sda. Перед изменениями желательно протестировать настройки на тестовой системе во избежание негативного влияния на производительность или стабильность системы.
Изменения параметра действуют только до перезагрузки системы. Чтобы изменения сохранялись, добавьте команду в rc.local или настройте сервис для применения параметров при загрузке.
Практическое исследование
Рассмотрим практический сценарий. Создадим лабораторную среду на Linux-сервере и проверим производительность диска. Нагрузку (IOPS) будем генерировать с помощью инструмента fio, а мониторинг производительности проводить с помощью утилиты iostat. Наша задача — оценить влияние параметра max_sectors_kb на производительность системы.
Среда для тестирования:
Тип EC2-инстанса: c5.12xlarge
EBS-том:
тип: GP3
размер: 20 GiB
IOPS: 3000
пропускная способность: 750 MB/s
Операционная система: Amazon Linux 2
Проверка дисков и установка fio
Для начала проверим доступные диски:
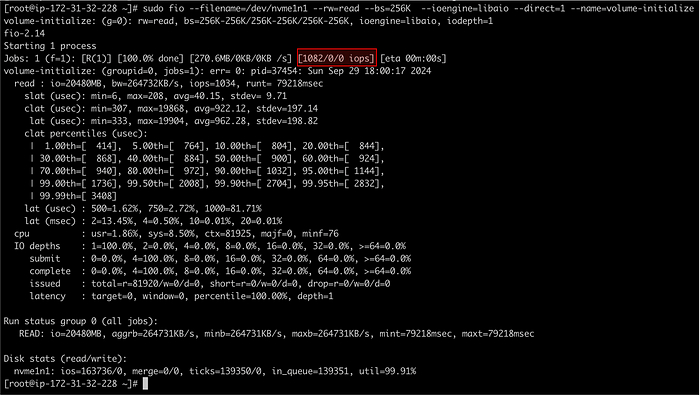
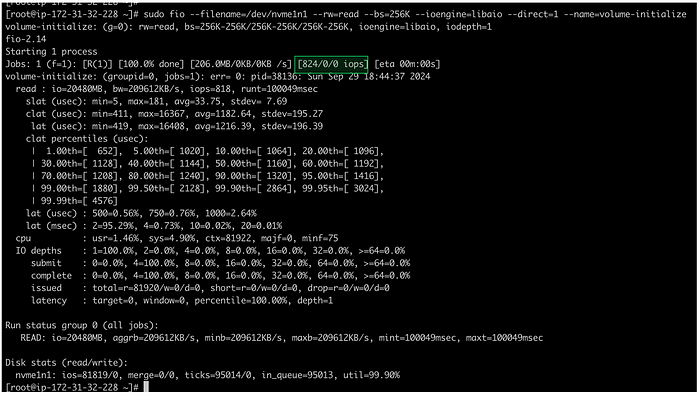
Мы будем создавать нагрузку на диск nvme1n1 при помощи утилиты fio и параллельно мониторить производительность диска, в частности показатель IOPS. Если fio не установлен, используйте команды ниже:
Обратите внимание, что в команде fio мы задали размер запроса 256 KiB.
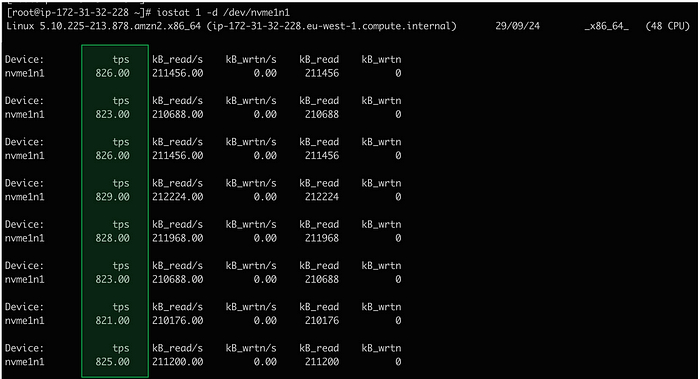
Наблюдения
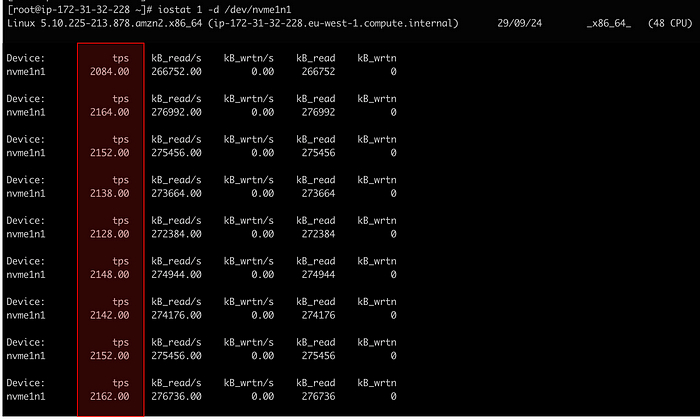
На первом скриншоте видно, что утилита fio генерирует 1082 IOPS, однако утилита iostat показывает примерно 2164 IOPS (то есть в два раза больше).
Причина различий
Чтобы выяснить причину этого несоответствия, проверим значение параметра max_sectors_kb:
cat /sys/block/nvme1n1/queue/max_sectors_kb
Объяснение:
Инструмент fio создавал IOPS с размером 256 KiB, а max_sectors_kb был установлен на значение 128 KiB. В результате ядро Linux разбивало каждый запрос на два меньших запроса по 128 KiB каждый (256 KiB = 128 KiB × 2). Именно поэтому количество операций, регистрируемых iostat, было в два раза больше, чем указывал fio (1082 × 2 = 2164).
Важно: Увеличение числа запросов из-за неправильно настроенного max_sectors_kb может негативно повлиять на производительность сервера и привести к троттлингу производительности диска (например, EBS-тома), если число операций превышает базовый уровень IOPS.
Результат: После изменения параметра max_sectors_kb количество операций IOPS, отображаемое fio и iostat, совпало.
Заключение:
Максимальный размер I/O-запроса (max_sectors_kb) является мощным инструментом для тонкой настройки производительности дисковой подсистемы в Linux. Правильно подобранное значение позволяет оптимизировать производительность ввода-вывода и снизить нагрузку на CPU, однако следует учитывать возможное увеличение задержек и аппаратные ограничения. Любые изменения параметров производительности следует предварительно тестировать и внимательно анализировать перед внедрением в продуктивную среду. Это гарантирует стабильность работы системы и её оптимальную производительность в различных сценариях.
Для лиги лени: про бывшую VMware, теперь VMware by Broadcom. Чего было и чего ждать
Часть 1. Чего и почему ждать.
Часть 2. Fast start. Литература и сайты для тех, кто вляпается в это легаси.
Часть 3. Прочее.
1.1 Пока переписывалась статья, вышло обновление- 8.0 Update 3e 24674464 , с обещаниями снова выдавать ESXi free, еще более урезанную. Спасибо конечно, и на том.
1. 2 Не дописанное из первой части
Продукты фирмы VMware не были как-то особо популярны в РФ. Так, по мелочи. Пара мелких банков, какие-то сотовые и небольшие телеком операторы, разорившаяся авиакомпания, пара фирм по розничным продажа бытовой химии, облачные провайдеры, итд. Короче, все те, кто не мог себе позволить купить нормальный Azure Stack (Azure Stack HCI, сейчас Azure Local), или сидел на таком дремучем легаси, что виртуализация у них была уже, конечно, не механическая, и не ламповая, но серверы приходилось или ставить краном, или возить на специальном лифте. Оборот и прибыль VMware в РФ (от мировой) была в районе статистической погрешности, от 0.1 до 1%, поэтому ее уход из РФ заметили только те, кто работал (скорее, не работал) в облаке МТС в 2024 году. Такие, во всех отношениях отсталые продукты, как: VMware NSX Omnissa Horizon (ранее Horizon View, VMware VDI, VMware View) VMware Cloud Director VMware Cloud Foundation
Могут быть легко и почти безболезненно заменены. Наверняка, те немногие их, зачем-то, использовавшие, облачные и сотовые операторы, уже давно провели замену. А то, что они про это молчат, так исключительно из скромности.
Ит отдел готовится к безболезненному уходу от VMware, и внедрению в критическую
Если же они этого не сделали, то возникает интересный тройной юридический казус. Во первых, по лицензионному соглашению, заказчик имеет право на обновления только в период действия подписки на поддержку. Срок подписки обычно был три года, вся подписка из 2021 закончилась в 2024, а местами и в 2022, поэтому вопрос законности покажет любой аудит. Во вторых, и это гораздо интереснее, очень много сотовых операторов , банков и так далее «в целом» отнесены к КИИ. Соответственно, в их системах должны быть установлены обновления безопасности, скачанные с официального сайта, и проверенные соответствующими органами. В частности: Обновление VMware Tools, Идентификатор обновления: TO1965, Вендор: VMware Inc., ПО: VMware Tools . С вендором ошибка, до ФСТЕК за 2 года не дошло, что это теперь Broadcom, фирмы VMware Inc больше нет. Там, на сайте, и с обновлениями самого ESXi проблема, последнее протестированное обновление 8.0b-21203435 для 8.0 из 2023. Но уязвимости описаны, BDU:2024-01809 или BDU:2025-02354, вместе с советами «выкручивайтесь сами», то есть, конечно, не так, цитата:
Установка обновлений из доверенных источников. В связи со сложившейся обстановкой и введенными санкциями против Российской Федерации рекомендуется устанавливать обновления программного обеспечения только после оценки всех сопутствующих рисков.
Интересно, что когда зарубежная проприетарщина много лет поставляет в РФ проверенные и годные продукты это одно, а захват ядра, базы из баз , практически всего опенсорса кликой сумасшедшего финна из агрессивного блока НАТО, это другое. Ну да ладно, а то так окажется, что исходники Windows 20 лет назад отдали, кому положено, и что Windows с 1996 до 2004 года неплохо работал в системе управления вооружением USS Yorktown (DDG-48/CG-48, программа Navy's Smart Ship program - на 2*27 Pentium Pro)
И в третьих, это рекомендации «переходить на российское шифрование и не использовать то, о чем говорить нельзя, из трех букв». Как использовать российское этцамое для обновления по https, если с той стороны не в курсе про ГОСТ, и как не использовать этцамое, если с той стороны и обновление, и документация, закрыты для РФ?
Вы находитесь здесь
Но, к теме.
Fast start. Литература и сайты для тех, кто вляпается в это легаси.
Сразу скажу: если вы унаследовали «это», то можете забыть про какую-то литературу на русском.
По теме выходило ровно 3(три) книги на русском, от 1 (одного) автора.
Михаил Михеев: Администрирование VMware vSphere из 2010 года. Михаил Михеев: Администрирование VMware vSphere 4.1 из 2011 года. Михаил Михеев: Администрирование VMware vSphere 5 из 2012 года.
В обязательном порядке должна быть прочитана книга по сетям. Не какой-то там курс от «аналоговнетных русских курсов и русских авторов», а только родная Cisco. И только такая: Cisco CCENT/CCNA ICND1 100-101 Official Cert Guide Academic Edition - by WENDELL ODOM, CCIE NO. Если в каком-то сообществе, группе, все равно где, вам предлагают читать Олиферов вместо Cisco Press - БЕГИТЕ ГЛУПЦЫ. После того, как вы прочитаете все вышеперечисленное, можно идти сюда за второй порцией литературы и статей.
Добавляются сети. Придется биться насмерть с сетевиками, и с любителями русской сетевой литературы, где LAG считается третьим лучшим изобретением человечества, сразу после описанного в Бытие 38:9 и Левит (18:22). Читать заметку: John Nicholson - As I lay in bed I can’t help but think…. LAG/LACP/MLAG/Bonding links to hosts is a bad idea for anything you care about that much. (A thread) – тут могла быть ссылка на вроде еще запрещенных в РФ любителей 140 знаков, и вот эту статью - LACP and vSphere (ESXi) hosts: not a very good marriage.
Подводя итог. Как легко прочитать в интернете, ESXi и прочие продукты VMware вокруг него – это жалкое проприетарное подобие Linux \ KVM \ XEN \ CEPH \ OVN, и еще сотни «замещающих» продуктов, по непонятным причинам совокупно (с учетом стоимости людей и требований к оборудованию) стоящее дешевле в пересчете на 3 года. Исключение - если у вас люди бесплатные, помещение бесплатное, и никаких требований к SLA нет. Давно списанное оборудование на балконе, например, которое может упасть только вместе с балконом, а зимой греет весь подъезд всеми 8 ядрами на сокет (единственный). Учиться работать с этим, конечно, не стоит. Рынок труда для этих продуктов уже ограничен «золотой тысячей кровавого энтерпрайза», то есть, суммарный платежеспособный спрос будет падать и падать. Всегда останутся организации, в поисках высококвалифицированных низкооплачиваемых кадров, почему-то не могущие найти кадры на открытом рынке. Да и учиться там особо нечему – как большая часть проприетарных продуктов, он еще недавно был сделан так, чтобы, в основном, работать. Если не работает, что бывало, то дать возможность собрать огромный дамп логов для техподдержки. Конечно, и тут все нехорошо. Последние лет 5 и в эту разработку прокрались криворукие, вместе с идеей «давайте тестировать новый код на пользователях». Хуже всего в VMware в РФ – это отсутствие комьюнити. Два русских сообщества, входящие в Virtual maining user group, причем на треть состава сидящие в третьем сообществе, по нелицензионным версиям VMware. Одно мертвое сообщество по NSX, такое же мертвое по Amazon Elastic VMware Service. Одно более-менее живое сообщество по vSAN, и просто ужас под названием «Сообщество по Азии». Помогут, в лучшем случае, в группе по vSAN. Вместо остальных достаточно бота с случайными сообщениями «гуглить пробовали», «это все есть в документации», или "что в логах".
Как же хорошо, что есть Reddit, LLM и форумы самого Broadcom.
PS. Как мне напомнили рецензенты, есть один крохотнейший плюс - то, что vGate умер на линейке 7. Это снизило глобальное потепление в России на 0.1 градуса, и уровень смога в Москве на 0.2%.
Для лиги лени: про бывшую VMware, теперь VMware by Broadcom. Чего было и чего ждать
План, наверное, такой. Часть 1. Чего и почему ждать. Часть 2. Fast start. Литература и сайты для тех, кто вляпается в это легаси. Часть 3. Прочее.
Часть 1. Чего и почему ждать.
2 октября 2025 года закончится эпоха VMware, как ее помнят олды, заставшие выход ESX (без i), переход на ESXi (с i), и ее покупку Broadcom 22 ноября 2023. 2 октября 2025 заканчивается продление поддержки VMware vSphere 7.x и VMware vSAN 7.x, но проблемы с этой «поддержкой» начались уже сейчас. В чем проблемы? Да во всем. Базу поддерживаемого оборудования сломали, и для ESXi и для vSAN. Они разные, если вы не знали. Базу статей переломали и убирают за paywall. Последние патчи тоже убрали за paywall. Возможно, следующие патчи будут с уникальной подписью – то есть, встающие только на эти процессоры, при наличии именно этих серийных номеров процессора и материнской платы. Цены поднимают, как и минимальный набор закупки. Это все просто про деньги. Кто с FC от Broadcom работает, тот знает, что их FC коммутаторы где-то на рубеже перехода от FOS 6 на FOS 7 (могу путать, давно было) при обновлениях и при окончании поддержки, стали превращаться в бесполезный кирпич. Но все равно, одним движением перейти, пусть от даже крайне тормозной Broadcom (Brocade G710 460 ns port-to-port latency at 64G speed) к нормальной 200/400G Cisco и Arista (на Xilinx В 7130 с его примерно 50 ns и ниже), не выйдет. Дорого, проще рядом строить инфраструктуру поверх 200/400G и гиперскейлеров. И уже есть 800 G (Arista 7060X5, Hyawei CloudEngine 16800-X).
Разумеется, у разных министерств РФ есть шанс занять оплатить захват освобождающихся ниш на рынке – как раз тут отдельные энтузиасты говорят, что они завтра готовы вернутся к играм на Pentium 2, так можно рядом и производство хабов возродить. На 350 нм можно даже, наверно, мегабитный свитч сделать, или модем ISDN-128, а рядом и мегабитный роутер на Zebra, или даже Quagga. Жаль, что энтузиасты не готовы рассказать, почему судьба как-бы-полу-готовой линии 350 нм будет лучше, чем у купленной и доставленной в РФ готовой линии 130 нм, но я все понимаю.
Так что, пока все идет так, как и предсказывали чрезвычайно уважаемые люди – как в Computer Associates и в UCC-7 - CA-7. Будет дорого и плохо.
Почему так будет – понятно. Broadcom вложил в покупку 69 миллиардов долларов, надо как-то отбивать, а при текущем состоянии доходов – расходы окупятся хорошо если лет через 10, хотя операционная прибыль уже выросла.
Почему так будет в глобальном смысле – тоже понятно. На рынок выходят решения на arm, число ядер на Intel и AMD растет, значит в те же 2U «обычного» сервера можно набить 2*6 терабайт памяти и запускать виртуализацию даже на KVM. Вдобавок, облака и контейнеры отбивают долю рынка у он-прем виртуализации, поэтому проще сосредоточиться на тех, кто будет плакать, но заплатит, чем на тех, у кого денег нет. Капитализм. Может, кто-то из сервис провайдеров еще купит, за все заплатит конечный покупатель.
Бежать особо некуда. Microsoft S2D проще в настройке, но лицензирование стоит, с учетом дозакупок лицензий на ядра, таких как Microsoft Windows Server 2025 16-core Datacenter Additional License WW SW SKU # P77107-B21, по 5500$ – 5800 $, очень дорого. Получается где-то по 350$ за ядро, и тогда 150$ за ядро на VCF в год – не так и дорого. Тем более, что VMware standard стоит всего 50$ (за ядро в год).
(Уточнение. Согласно калькулятору Windows лицензия обойдется в 36960 за 2*48 ядер, $385 за ядро)
Плюс новые люди, плюс смена архитектуры, поэтому в целом, с новыми серверами, где ядер на сокет побольше, можно и потерпеть.
Нет проблем с убежать на KVM в масштабе 1-2 серверов. Проблемы убежать на KVM, если у вас реальных задач на 10 современных серверов (48 – 64 физических ядер на сокет, 6 тб памяти на сокет, 24 PCIe Gen5 NVME диска на 2U сервер) – нет никаких. На таком железе вы хоть на Ceph можете строить архитектуру, с выделенными нодами хранения. Ну да, будет дорого, хотя как посчитать. Будет нужно много дорогого железа, будут нужны люди, умеющие что-то большее, чем apt install, но сейчас не 2010 -2015 год, и проблему скорости на опенсорс решениях можно решить даже железом. Людей, разве что, дешевых, нет. Все подались в девопсы и SRE, инфраструктурщики и прочие Linux админы на рыне труда РФ не нужны (то есть нужны, но за цену эникея). Раньше, очень давно, лет 10 назад, еще можно было намайнить себе премию на корпоративном проде, до сих пор в телеграмме есть «Российская группа по майнингу на виртуалках» - Virtual mining user group, но, при текущем хешрейте, производительности не хватит даже на пиво в месяц.
Проблемы будут, если у вас огромная старая архитектура 10-15 летней давности, где 4-6-8, или даже 10, ядер на сокет, и общий подход «оно же работает, а ключи сгенерите, там точнее не сложнее, чем в ArtMoney». Возможно, не сгенерите. Возможно, сгенерите, и получите кирпич. Можно ли не обновлять, и так и остаться работать на линейке 7? Можно. Но, рано или поздно, там повторится ситуация или с лицензиями, или с тем, что патчей просто не будет. Как уже нет для 5.5., 6.0, 6.5 и 6.7. Будут только индивидуальные патчи, только на версию 9, и больше никаких. И людей не будет, готовых этих нормально заниматься. Да их и было не так много.
Подводя итог. Кто хотел убегать – давно побежал. Кто не очень хотел, как Siemens – не побежал. Для конечного работника важно другое – продукты VMware by Broadcom уходят с мирового публичного рынка, и спрос на таких сотрудников, с такими знаниями, будет падать. Может быть, но это не точно, будет как с IBM + Cobol – когда продукт очень нужен, очень дорогой, но весь рынок, это десяток очень больших покупателей.