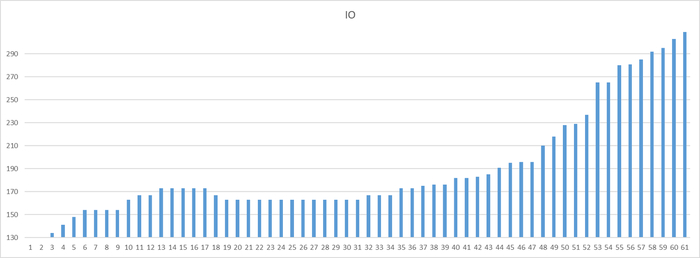
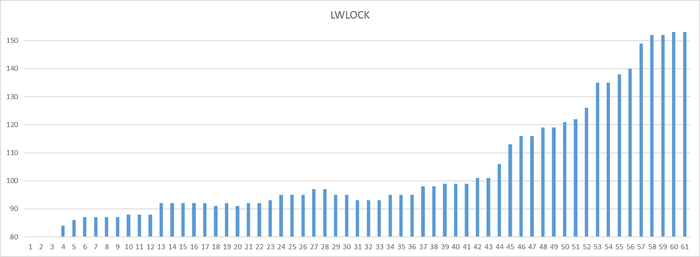
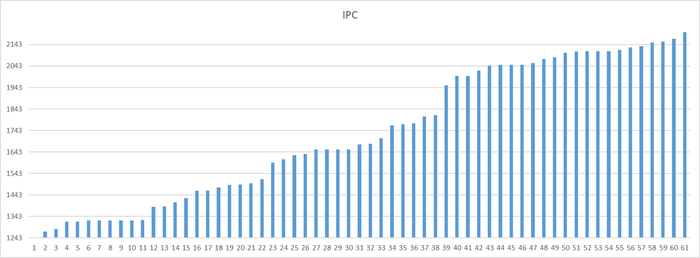
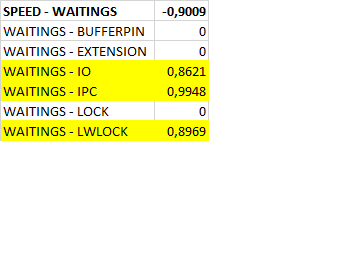
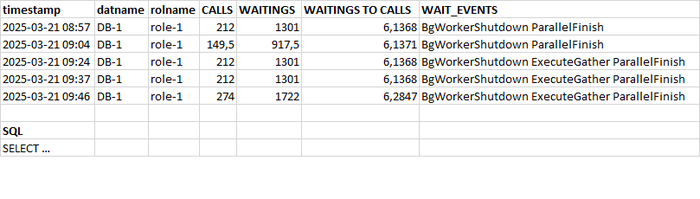
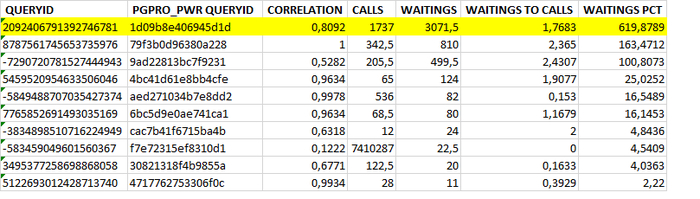
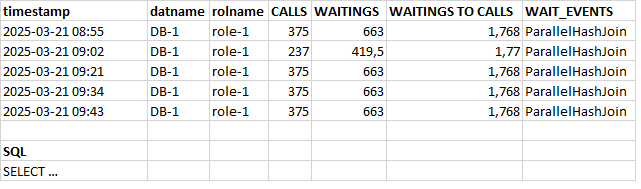
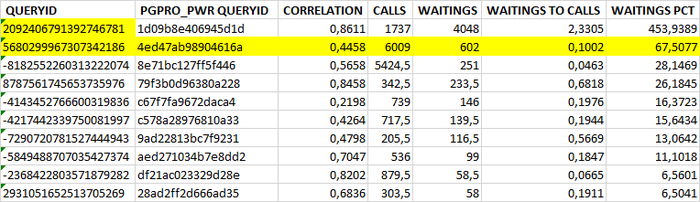
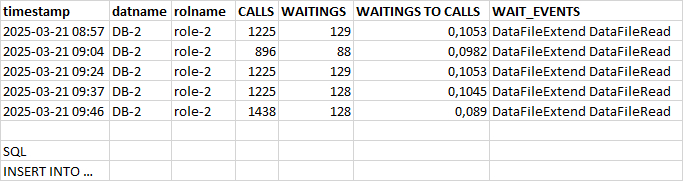
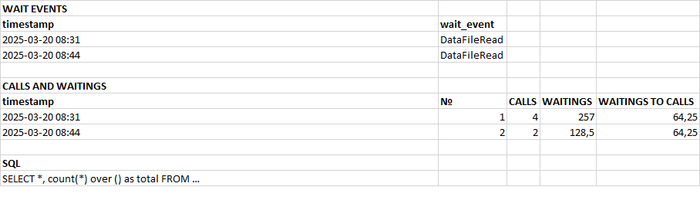
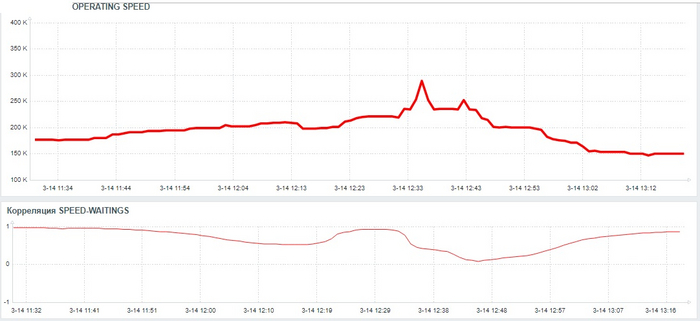
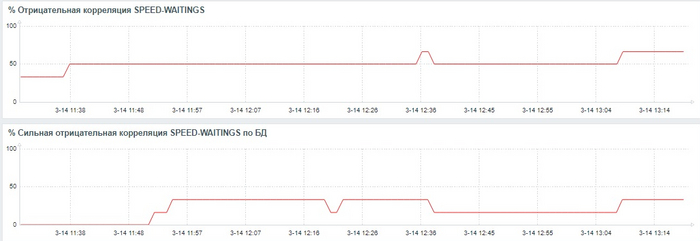
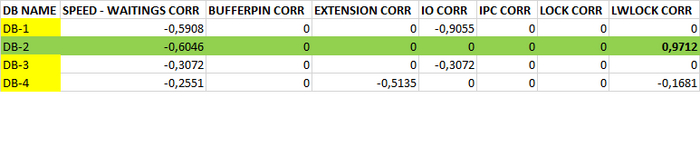
Может содержать ложь (3)
Продолжаем знакомиться с книгой Алекса Эдманса.
Все части выложены в серии.
Даже если когда у нас в руках есть факты, они не всегда дают полную картину. Выборка должна быть представительной, то есть соответствовать генеральной совокупности. Иначе можно надёргать удобных данных для подтверждения своего утверждения. Чем многие и занимаются. В частности, этим грешат некоторые блоггеры, расписывающие прелести инвестирования на примере удачных вложений. Следует иметь в виду, что на каждого успешного спекулянта может найтись гораздо больше неудачников. Но про них часто предпочитают умолчать.
Кто ищет дорогу к надёжному знанию, тот следует научному методу. При нём мы начинаем с постановки гипотезы о влиянии А на Б (входа на выход). Затем эта гипотеза проверяется. В идеале стоило бы перебрать все данные. Но это чаще всего невозможно, поэтому приходится делать выборку. И выборка эта должна быть не какая попало. Она должна охватывать широкий спектр данных. Слоёный пирог режут сверху вниз, чтобы получить полное впечатление о его вкусе. Следующий шаг – найти контрольную выборку, которая не включает в себя вход. После этого рассчитываем выход для всех входных данных и сравниваем. Если для входа он сильнее – вуаля! Но после этого необходимо оценить статистическую значимость связи, то есть исключить роль случая. Чем больше выборка, и чем сильнее корреляция – тем лучше. Если вероятность «случайного» отклонения нашей гипотезы окажется ниже 5%, то мы можем сделать вывод о влиянии входа на выход. Но всё ещё но не сможем доказать нашу гипотезу! Мы просто будем знать, что установленная связь не случайна.
Простой обыватель, да и некоторые авторы, часто действуют совсем по-другому. Биограф Стива Джобса Исаксон не ставил гипотез, а идентифицировал возможные факторы, которые лежали в основе успеха бизнесмена. Например, тот факт, что Джобс был приёмным ребёнком. По науке надо было исследовать истории множества приёмных детей, а также множества успешных бизнесменов, а не одного лишь Стива. То есть набрать репрезентативную выборку. Иначе у нас получится вывод по индукции – из частного случая выводится общая последовательность. А это не есть логично.
Эта простая и очевидная вещь часто забывается, когда мы слышим увлекательный рассказ. Истории успеха эксплуатируют нарративное заблуждение: наше стремление видеть два события и верить в то, что одно вызывает второе. Даже если у них обоих может быть общая причина или вообще никакой связи между ними нет. Видя последовательность фактов, мы склонны выстраивать поясняющую историю с логическими стрелками между ними. У Джобса отец любил мастерить – ага, вот почему Стив стал таким успешным! Звучит красиво, во всяком случае.
Даже обилие фактов может оказаться не репрезентативным. Их всегда при желании можно надёргать. Главное, чтобы было откуда. Поэтому всякий раз, взяв в руки очередную историю успеха, задавайтесь вопросом о том, исследовали ли авторы случаи, которые не ложились в красивую картинку: когда есть вход, но нет выхода, или есть выход без входа.
Карабкаемся дальше по авторской лестнице. Итак, пусть у докладчика есть не только отдельные факты, но данные, то есть представительная выборка. Мы всё ещё не можем верить ему, потому что он мог нарыть её нехитрым методом под называнием data mining. Грубо говоря – он провёл сотни тестов, отбросил все, что не сработали, и оставил то немногое, что подтвердило его гипотезу. Если долго мучиться, что-нибудь получится. Вышеупомянутая вероятность в 5% статистической значимости – довольно большой процент.
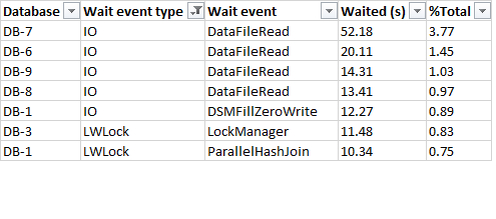
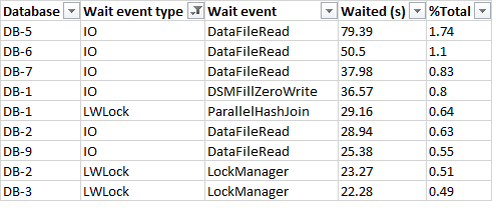
Одним из средств при этом является перебор метрик для искомого фактора. Успешность компании можно измерять разными способами. Есть бесспорные индикаторы, такие как акционерный доход. Но никто не мешает взять что-то другое – скажем, норму прибыли. Пусть она не учитывает десятки других факторов, влияющих на цену акции и её дивиденды, зато с ней можно обосновать своё утверждение о влиянии разнообразия в менеджменте на успех компании. Что некоторые и делают.
Поэтому при виде всякой экзотики в обоснование результатов следует включить режим скептика и задаться вопросом: измеряет ли докладчик вход и выход самым естественным образом? Также следует включить здравый смысл и выяснить, способен ли вообще вход влиять на выход. Если нет логики в обоснование, то результат, скорее всего, намайнили в грудах данных.
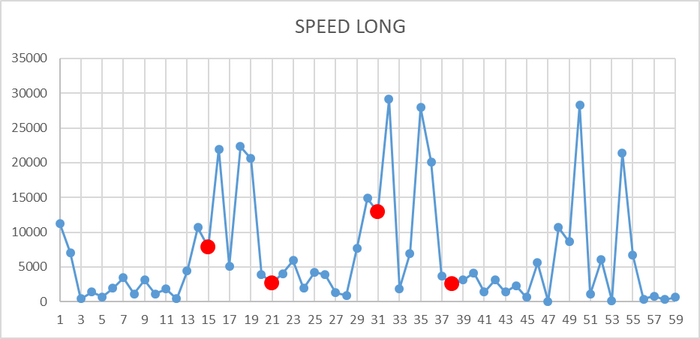
Некоторые поступают совершенно иезуитским образом: запускают кучу тестов, после чего находят значимые связи, чтобы на этом основании нарыть уже саму гипотезу. Как поймать таких деятелей за руку? Чтобы ответить на этот вопрос, Алекс рассказывает нам о своей академической юности, когда он писал диссертацию о влиянии спортивных событий на фондовый рынок. На эту идею его натолкнула практика на Morgan Stanley во время чемпионата Европы по футболу 2004 года. Он лицезрел эскапады трейдеров после проигрыша своей команды и подумал, что в суммарном масштабе это может влиять на курсы акций всей страны. Логично? Логично. Результат важной игры влияет на настроение миллионов, а настроение влияет на инвестиционные решения. Автор обнаружил, что на следующий после проигрыша национальной команды день фондовый рынок проседал чуть ли не на полпроцента. Англия не смогла нормально пробить послематчевые пенальти – получайте просадку в 10 миллиардов. Что интересно: на курс акций ощутимо влияют в основном проигрыши любимой команды. Побед не замечают.
Алексу удалось защитить свою диссертацию, потому что у него была сильная логичная гипотеза. Но при этом ему не удалось избежать обвинений в добыче данных. В погоне за результатом можно ведь попытаться сделать удачную выборку, выбросив всё неудобное. Чтобы ответить на упрёки, необходимо продемонстрировать, что результаты исследования работают и на других выборках: в другое время, в другом месте. Так и Алексу пришлось отвечать на обвинения, используя результаты других чемпионатов, а также другие виды спорта. Оно работало и в 2004, и в 2014, и в 2024 году. И в крикете, и в регби, и в баскетболе. Лишь хоккей выпал из тренда.
Можно прийти к разным выводам даже при использовании одних и тех же данных. Это достигается произвольным их группированием: данные разделяются на разные группы, после чего сравнивается влияние отдельных групп на выход. Самое «вкусное» при этом то, что делить на группы можно, как хочется, так что фрагмент с неудобными данными можно не брать в сравнение. Если мы видим подобное сравнение в обоснование тезиса докладчика, нужно обращать внимание на пропуски. Например, когда сравнивают рентабельность компаний с тремя и более женщинами в руководстве с показателями компаний вообще без женщин на руководящих должностях, стоит спросить о том, куда подевались показатели компаний с одной или двумя женщинами в топ-менеджменте.
Предположим, что с данными у нас всё чисто, и мы имеем надёжную корреляцию. Значит ли это, что у нас есть свидетельство истинности утверждения? Всё ещё нет: корреляция не означает причинной связи. Автор поясняет это исследованием связи между кормлением грудным молоком и интеллектуальным развитием ребёнка. Несмотря на явную корреляцию между этими вещами, говорить о причинности здесь рано. Поскольку они могут зависеть не друг от друга, а от какой-то третьей, общей причины. Например, от интеллектуального развития матери, которая и позже начнёт прикорм, и курить будет реже, и будет развивать своего ребёнка. Не говоря уже о том, что она уже дала ему свои гены.
Данные – не свидетельство, потому что могут быть альтернативные объяснения для сложившегося положения вещей. Выход может включиться по какой-то другой причине, нежели вход. И даже если у нас есть контрольная группа, её может оказаться недостаточно, поскольку она может оказаться связанной с входом. Одним словом, разные входы могут оказаться не случайными, а быть следствием общей причины, будь то волевое решение, корреляция с другими факторами или другой процесс.
С волевым решением мы имеем дело тогда, когда люди принимают его. Мать решается на грудное вскармливание не случайным образом, но по каким-то причинам. Если же изучать не решения, а какие-нибудь признаки, то и они могут коррелировать с другими признаками. Изучаем эмоциональность – не забудем, что она может быть связана с IQ. Влияние других процессов автор иллюстрирует на примере исследования связи между грязным воздухом и летальностью пандемии ковида. Но грязный воздух – это эндогенный фактор. Он является следствием других факторов, которые могут влиять и на летальность от ковида. Первое, что приходит в голову при этом – это плотность населения.
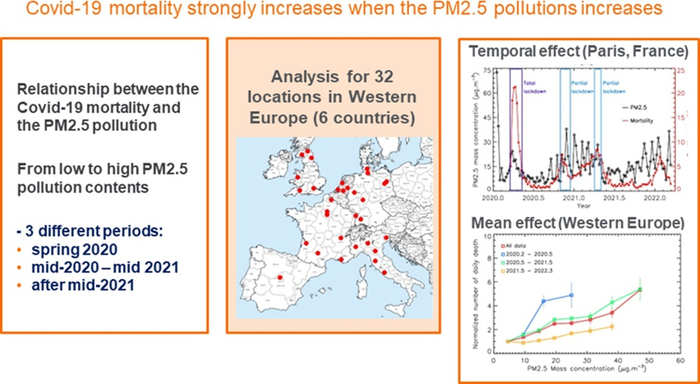
Спутаешь корреляцию с причинностью – будешь неправильно предсказывать и неверно принимать решения. Смелые предсказания вызывают широкий отклик, как случилось с публикацией McKinsey о связи долгосрочного планирования с производительностью компании. Они предсказывали, что если все американские компании раздвинут горизонт планирования, то экономика в целом вырастет на ещё три триллиона за десятилетие. Harvard Business Review посчитали это «доказательством», но после того, как читатели стали жаловаться, исправили «доказательство» в заголовке своей публикации на «свидетельство». Так что стараемся всегда смотреть с недоверием на подобные бомбические заголовки и помним: самая убедительная статистика никогда не бывает слишком хорошей или слишком плохой.
Как же прояснить возможную причинность корреляции? Лучшим инструментом является математическая регрессия. С её помощью можно установить корреляцию не только одного лишь входа с выходом, но протестировать связь и с другими возможными входами. Эти дополнительные входы называют контрольными величинами. После этого можно анализировать изменение выхода при изменении одного лишь из входов, при прочих равных. Тогда корреляция может легко испариться. Но если останется – то в этом действительно что-то есть.
При всей простоте метода многие умудряются сесть в галошу, что случилось с авторами бестселлера The Spirit Level, писавших о пагубном влиянии неравенства на общество. Книга имеет интригующий подзаголовок: «почему равенство лучше для всех». Алекс удивился: неужели и для богатых тоже? Её авторы собрали статистику о физическом и психическом здоровье, а также о других параметрах общества и утверждали, что неравенство ухудшает их всех. Однако они не учли, что в нашем случае может быть целый ворох общих причин, первая из которых, которая приходит на ум – это бедность. Бедные общества, как правило, отличаются высоким неравенством. И здоровье в них тоже не очень. Авторы попытались, однако, продемонстрировать, что бедность тут ни при чём, продемонстрировав слабую корреляцию бедности и здоровья. Но ведь они написали книгу не про бедность. А про неравенство. Правильным методом было бы продемонстрировать корреляцию неравенства и здоровья с бедностью в качестве контрольного параметра. И на самом деле, когда кто-то задался такой задачей, корреляция между неравенством и здоровьем в обществе стала намного слабее.
К сожалению, мы не всегда можем включить в контрольные переменные всё, что хотелось бы. Но нам и не надо брать туда всё подряд. Если переменная коррелирует лишь с выходом, но не со входом, то извлечение её из регрессии не повлияет на результат. Но а если она всё-таки связана со входом, но корреляция отрицательная, то она тем более не может считаться альтернативным объяснением.
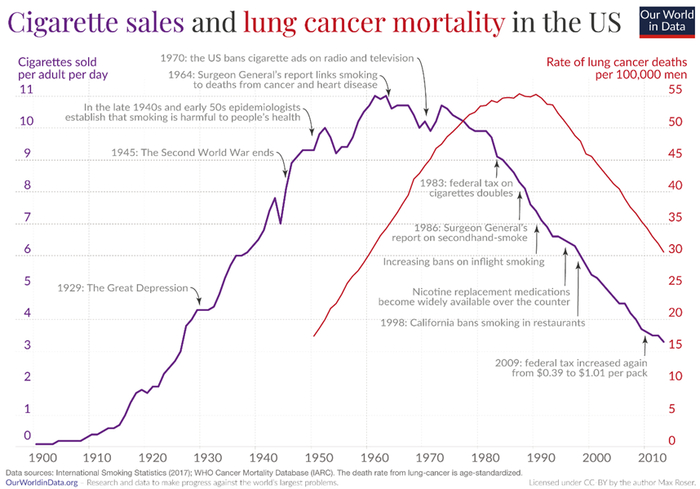
Часто на неправильный вывод из корреляции может натолкнуть временная последовательность. Так, некоторые исследователи обнаружили, что прекращение курения приводит к более высокой вероятности смерти. Как известно, бросить курить можно до смерти, но не после неё, так что можно прийти к выводу, что, бросив курить, приближаешь свою смерть. Проблема здесь в неясности логических связей и общих причин, большинство из которых имеет разнонаправленное действие на смертность и прекращение курения. В данном случае на вход действует выход! Очень многие бросают курить лишь при возникновении большого риска для собственного здоровья. Но, как говорит поговорка, поздно пить Боржоми, когда почки отвалились. Такие «бросатели» проживают меньше, чем те, кому врач не советовал бросить. Вот поэтому те исследователи и не увидели ожидаемой положительной корреляции между курением и смертностью. Она есть, но на неё наложилась гораздо более сильная корреляция между угрозой смерти и прекращением курения.
Здесь мы имели дело с известным заблуждением post hoc ergo propter hoc: после этого, значит по причине этого. Как видим, это не всегда так. Добавлю от себя: в случае с курением у нас в распоряжении есть гораздо более наглядная статистика, чем простая корреляция между прекращением курения и смертностью.
Путают корреляцию с причинностью все, кому не лень. Особенно нерадивые журналюги. Автор советует нам пользоваться множественной регрессией для того, чтобы исключить действие общих причин. Но я хотел бы напомнить, что регрессия – это инструмент для установления корреляции, но не причинной связи. С её помощью мы можем добиться определённой ясности, но до установления причины и следствия останется ещё долгий путь. Порою – бесконечный.