

Нужен бокс Usb под 2 Nvme с аппаратныv raid 1
Айтишники подскажите, второй день не могу найти девайс...
Что-то небольшое, надежное. .Спасибо
Айтишники подскажите, второй день не могу найти девайс...
Что-то небольшое, надежное. .Спасибо
Всем спасибо, кто давал вредные и полезные советы.
Для лиги лени: привыкание к новому и бесполезные тесты часть следующая.
В предыдущих сериях :
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 1 - общая
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 2 - виртуализация
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 3 – цифры и предварительные итоги
Тестирование локальных дисков и систем хранения данных: подводные камни. Часть 4 – что там изнутри виртуализации
Итак, прикупил я два туза на мизере новый ноутбук, и пошел переезжать.
Конечно, есть масса готовых утилит для переезда профиля
Конечно, пользоваться ими я не стал. Это в корпоративной среде нужен User State Migration Tool (USMT) или forensit User Profile Wizard
Первым делом обновил Windows, конечно не забыв про
OOBE\BYPASSNRO
Вторым – выполнил скрипт DisableUnnecessaryWindowsServices. Всякие твикеры это тоже хорошо, но начать надо с простых, понятных и воспроизводимых вещей.
Со скриптом есть проблемы.
Без этого не будет звука
"Audiosrv", # Windows Audio
"AudioEndpointBuilder", # Windows Audio Endpoint Builder
Не уверен насчет задач:
"QWAVE", # Quality Windows Audio Video Experience
и без этого этого блютус работает, но не видит мышку.
"bthserv", # Bluetooth Support Service
Device Install Service почему-то устанавливается в manual, и без ручного запуска тоже не давал добавить мышь. Но все остальное вроде ок
Третьим делом выключил гибернацию.
powercfg.exe /hibernate off
Я в свое время с гибарнацией поел с лопаты, когда оперативка просто кончилась, и то, что она ушла на кеширование файла гибернации, было видно только в Sysinternals RAMmap.
И четвертым делом потыкал в Sysinternals Autoruns
И на выходе получил ошибку отсюда:
Automatic Device Encryption Support Reasons for failed automatic device encryption: PCR7 binding is not supported, Un-allowed DMA capable bus/device(s) detected
Это не про user space сервис, это про
"ShellHWDetection", # Shell Hardware Detection
Исправил и это тоже, иначе какое шифрование, какое авто монтирование.
Power plan
Оказывается, по умолчанию мне система поставила Balanced power, ну куда это годится. Пришлось покрутить ручки, но про это позже.
Hyper-V for Windows 11
Я много лет использовал VMware Workstation, но есть нюанс. У Windows есть разные режимы работы с виртуализацией, и VMware Workstation, особенно в части дисковых операций, из-за множества прокладок и трансляций, скажу так – не то чтобы не дает скорости, но становится крайне процессоро-зависима. Любой ПУК в хостовой системе, и дисковые операции в Workstation начинают думать. У ESXi такой проблемы, разумеется, нет – это абсолютно другая архитектура. В любом случае Dekiru Neko wa Kyou mo Yuuutsu
Потестирую хоть как-то.
Для процессора и памяти, конечно, берем
Free Mersenne Prime Search Software - Great Internet Mersenne Prime Search, GIMPS
Для диска берем DiskSPD последней версии, DISKSPD 2.2 – брать тут.
Конечно надо было померять скорость ДО включения Hyper-v, поскольку, если вы не знали, Hyper-V работает как нормальный гипервизор, подгружая Windows уже в виде виртуальной машины, что может быть и влияет на производительность. А может, и нет. То есть, конечно, да, но не совсем.
Что там на NTFS?
Get-CimInstance -ClassName Win32_Volume | Select-Object DriveLetter, FileSystem, BlockSize| Format-Table -AutoSize
ATTO Disk Benchmark (качать тут, статья с примером тут) показывает совсем не то, что хотелось бы. Потому что он работает в один поток, и только глубина очереди как-то регулируется.
На DiskSPD, конечно, словил ошибку:
Попутно словил ошибку -
WARNING: Could not set privileges for setting valid file size; will use a slower method of preparing the file
И решение:
OK, so that's exactly what's happening. There is certainly (always) a longer description to attach to it (see above), but DISKSPD when run w/o privilege to assert SeManageVolumePrivilege cannot invoke SetFileValidData and therefore has to write the entire file through to get it into its standard if-created-by-DISKSPD state: with valid data at the end of the file.
Решение очевидное, от админа надо запускать.
Новый диск на новом ноутбуке выдает: (Файловая система – NTFS с блоком 4k, очередь по умолчанию – 2). Файлы по 200 Гб, не похоже на тестирование кеша.
Тестирование - 60 секунд.
1 тред, 1 файл – 35.000 IOPS блоком 4к на чтение, 15.000 IOPS блоком 8к на чтение
1 тред, 1 файл – 40k IOPS блоком 4к на запись (как так вышло – не знаю), 45k IOPS блоком 8к на запись. Это как?
2 треда, 1 файл – 25.000 на поток, итого 50.000 IOPS блоком 4к на чтение, и 2 по 30.000 на запись блоком 4к
3 треда – 23.000, всего 70 на чтение, и на запись 25, 25, и 35 тысяч, итого 85k. Блоком 8к показатели аналогичны
4 треда – 4 по 22.500, всего 90к на чтение. И 4 по 23 к на запись, итого 92к.
5 тредов – 20.000 на тред, всего 100к на чтение. Аналогично при блоке на 8k, те же 20.000 IOPS на тред на чтение,
На запись – примерно 10.000 IOPS блоком 4к на тред при первом тесте, до того как я покрутил настройки баланса.
Как бы так сказать «я ничего не понял», не говоря, что ничего не понял?
Проблема тестирования дисков наглядно показывает рост времени исполнения.
Что удивительно, но тестирования изнутри виртуальной машины (Windows server 2025, STD, обновления от 07-2025) показывают цифры, схожие с работой из управляющей операционной системы. Как бы так еще понять, в какой Windows 11 добавили новый NVME обработчик – в 11h22, h23 или h24.
Пропущу длинное русское поле экспериментов, итого:
Для физики:
Размер файла имеет значение. Windows пытается максимально закешировать что можно, и в итоге, если у вас 64 Гб оперативки, а тестовые файлы по 20-40 гигабайт, то цифры будут странные.
Надо брать для тестов файлы в 3-5 раз больше размера оперативки, 200 Гб на файл, два файла, на 64 Гб памяти – уже сойдет.
Количество реальных ядер и CCX имеет значение, причем для дисковых операций на хосте «потоки» AMD работают куда лучше «потоков» Intel. И, особенно, на последних мобильных интелах без HT и с энерго сберегающими ядрами.
На этом ноутбуке 6 ядер, 12 потоков – так вот, до 12 потоков включительно нагрузка растет линейно.
Конкретно этот NVME обрабатывает :
На чтение, 8 тредов: 4 треда по 40k, 4 по 20. 10 тредов – 10 по 35k, всего 350. 12 тредов – 12 по 35, всего 400k. 14 тредов – 10 по 30k, 4 по 15. 16 тредов – 8 по 28, 8 по 12. 18 тредов – 6 по 25, 12 по 10. Максимум достигается при числе тредов DISKspd = числу тредов в CPU.
И это около 400k IOPS. На чтение. Блоком 4к. При глубине очереди 2.
На запись картина другая. Есть подозрение на гигагерце зависимость по ядрам, авторазгон я не выключил.
Максимум получен для 8 тредов – 8x32k, около 256k IOPS на запись блоком 4k.
При 10 тредах получается по 19k на запись, всего 190к. Но расхождения по тредам нет. 12 тредов – падение до 12k IOPS на запись на тред, всего 145k, но все еще нет расхождения.
14 тредов – 10 тредов по 12 к и 4 треда по 7к. Всего 155k. 16 тредов – 8 тредов по 10к и 8 тредов по 5.5k - всего 125. 18 тредов – 6 по 10к, 12 по 6.5
То есть максимальное число тредов по записи на физическом хосте в моих условиях не стоит держать выше, чем число физических ядер плюс два. При большой записи, конечно.
Изнутри виртуальной среды картина чуть другая
Тестовая виртуальная машина, 4 ядра, 8 Гб памяти, и, для начала, просто 2 файла по 20, не по 200, Гб.
Чтение, 2 треда: 24k IOPS на тред, всего 48k
Запись, 2 треда: 12k IOPS на тред при 2 тредах, всего 24k
Падение на чтение в 1.5 раза, падение на запись в 3 раза. Но, это тестирования НОУТБУКА, с домашним NVME SSD, и Windows 11. На Windows Server картина может быть абсолютно другой.
Чтение, 4 треда: 3 треда по 15K IOPS, 1 тред на 2k IOPS. Суммарно 47k
Запись, 4 треда – 3 по 8k, 1 на 5k, итого 30 (данные округлены)
Дальше начинается колдовство и магия. Файлы по 200 Гб, 2 файла.
чтение, 4 треда на файл, всего 8 тредов: 6 тредов дают по 16к, 2 треда по 2к. Итого 100k IOPS изнутри виртуалки на 4 процессора.
Чтение, 5 тредов на файл, всего 10 трелов. 7 тредов по 15к, 2 по 1к. Итого 110к
Чтение, 6/12. 9 по 18к, 3 по 2.5. Итого 170к. Идет, к слову так, блоками по 3 группы «больших» IOPS.
Чтение, 7/14. 10 по 14к, 4 по 1к. Итого 150к.
Чтение, 8/16. 12 по 20k IOPS, 4 по 2. Итого 260K IOPS на чтение изнутри VM на 4 ядра.
Чтение, 9/18. 13 по 18..22, 5 по 1.5. Итого 280k.
Чтение, 10/20. 15 по 21, 5 по 2. Итого 330k.
Чтение,11/22. 343k IOPS
Чтение, 12/24. 18 тредов по 22k IOPS, 6 тредов по 2к. Итого почти 400k IOPS на чтение.
То есть, 4 процессорная виртуальная машина на 24 треда выдала почти столько же IOPS, сколько физика при 12 тредах.
Для физики параметры были: -t6 -w0 -b4k -W10 -o2, и два файла по 200 Гб, то есть 12 тредов итого.
Файлы по 200 Гб, 1 файл. Чтение внутри виртуальной машины.
1 тред – 31k IOPS , 2 треда = 2x24 = 48, 3 треда 2x25+ 1x12 = 62(k IOPS), 4 треда – 3 по 16 и 1 тред на 2, итого 50.
5 тредов = 3 по 16 и 2 по 1.5, 6 тредов – 4 по 15 и 2 по 1.5, всего 62. ,7 тредов - 5 по 14.5 и 2 по 1.8. 8 тредов – 6 по 13 и 2 по 2.5, итого 83k
9 тредов – 6 по 12, 3 по 1.2 , итого 75. 10 – 85k IOPS, 11 – 92k IOPS, 12 – 102k IOPS
Логика какая-то странная.
Дописал текст, и увидел внутри виртуальной машины active power scheme: Balanced
Похоже, надо дополнительно смотреть на параметр:
ag Group affinity – affinitize threads in a round-robin manner across Processor Groups, starting at group 0. This is default. Use -n to disable affinity.
Или выделять не по 4 ядра на виртуальную машину, при физических 6, которые может еще надо как-то делить, а по 3. Или по 6.
Я в курсе про CCXs (Core Complex), но как-то странно это все.
Дожил, неужели NUMA имеет значение. Но не в 10 же раз разницы из-за Numa (CCX/CCD). И самое главное, не понятно, как изнутри 4 процессорной VM – дисковые задачи раскладываются на физические ядра и процессорные треды / потоки. Как 24 треда разложились на 18 быстрых и 6 медленных. И как из этой конструкции получить например 12 средних. Как вообще CPU scheduler что-то куда-то кладет в такой конфигурации. И не отпилить ли root.
Еще оказалось очень полезно посмотреть на итоговый размер файлов виртуальных машин. Поскольку тесты шли по 30-60 секунд, то максимально за это время записалось всего по 1.5 – 2 гигабайта. Но я еще посмотрю более детально.
Литература
скрипт DisableUnnecessaryWindowsServices
Windows Server 2025 Storage Performance with Diskspd
Sample command lines
Command line and parameters
Execution time longer than the parameter execution time on WSL Ubuntu #203
В следующих сериях:
Опыты на виртуальной машине на 3 ядра.
CPU affinity
Опыты на Debian внутри Hyper-V, опыты с Proxmox nested. Stay tuned!
Бонус
# 01
$pciStats = (Get-WMIObject Win32_Bus -Filter 'DeviceID like "PCI%"').GetRelated('Win32_PnPEntity') |
foreach {
# request connection properties from wmi
[pscustomobject][ordered]@{
Name = $_.Name
ExpressSpecVersion=$_.GetDeviceProperties('DEVPKEY_PciDevice_ExpressSpecVersion').deviceProperties.data
MaxLinkSpeed =$_.GetDeviceProperties('DEVPKEY_PciDevice_MaxLinkSpeed' ).deviceProperties.data
MaxLinkWidth =$_.GetDeviceProperties('DEVPKEY_PciDevice_MaxLinkWidth' ).deviceProperties.data
CurrentLinkSpeed =$_.GetDeviceProperties('DEVPKEY_PciDevice_CurrentLinkSpeed' ).deviceProperties.data
CurrentLinkWidth =$_.GetDeviceProperties('DEVPKEY_PciDevice_CurrentLinkWidth' ).deviceProperties.data
} |
# only keep devices with PCI connections
Where MaxLinkSpeed
}
$pciStats | Format-Table -AutoSize
Get-CimInstance -ClassName Win32_Volume | Select-Object DriveLetter, FileSystem, BlockSize| Format-Table -AutoSize
$Path001 = 'C:\DiskSpd\amd64\'
$Sp = $Path001 + "diskspd.exe"
cd $Path001
$Version = "007g1"
$Drives = @("C")
$FilesTemp = "Data4del"
$File001 = "deleteme_01.dm"
$File002 = "deleteme_02.dm"
$File003 = "deleteme_03.dm"
$Logs = @()
# $Threads = @("-t1","-t2", "-t3", "-t4","-t5","-t6","-t7")
$Threads = @("-t4","-t5","-t6","-t7","-t8","-t9")
# $Write = ("-w0","-w30", "-w100")
$Write = @("-w0")
#$BlockSize = ("-b4k","-b8k")
$BlockSize = @("-b4k")
# $Outstanding = @("-o2","-o4","-o8","-o16")
$Outstanding = @("-o2")
$Size = "-c200G"
$Time = "-d30"
foreach ($Drv in $Drives){
foreach ($Bl in $BlockSize) {
foreach ($Wr in $Write) {
foreach ($Outs in $Outstanding){
foreach ($T1 in $Threads){
$TimeNow = get-date -UFormat "-%d-%m-%Y-%R" | ForEach-Object {$_ -replace ":","-"}
Write-Host "TT " $TimeNow
$Out001 = $Drv + ':\' + $FilesTemp + '\' + $File001
$Out002 = $Drv + ':\' + $FilesTemp + '\' + $File002
$Out003 = $Drv + ':\' + $FilesTemp + '\' + $File003
$Stat = $Drv + ':\' + $FilesTemp + '\' + $Version + $TimeNow + "_" + $T1 + $Drv + $Outs+$T1+'.log'
$Logs += $Stat
Write-Host "testing mode " $T1 $Wr $Bl $Outs 'time' $Time
&$Sp $T1 $Wr $Bl -W10 $Outs $Time -Suw -D -L $Size $Out001 $Out002 > $Stat
}}}}}
для лл:
отныне самые обычные микрокарточки памяти получают скорость как у настоящего внешнего ссд диска
жадные империалисты таки выпускают нормальные технологии на рыночек
в продолжение моей предыдущей темы
Вот уже 10 лет как в телефон встраивают NVMe-диск. А в вашем фотоаппарате есть NVMe?
Раскройте свой творческий потенциал и окунитесь в новые впечатления с SanDisk microSD Express, картой microSD следующего поколения для тех, кто не хочет останавливаться на достигнутом. Выгружайте отснятый материал в рекордно короткие сроки*, играйте и исследуйте виртуальные миры, которые кажутся более реалистичными, чем когда-либо. Создавайте захватывающий контент нового уровня, не теряя времени. Благодаря добавлению интерфейса PCIe 3.1 NVMe данная карта представляет собой огромный шаг вперед в развитии формата microSD, ведь ее производительность сопоставима с базовыми внешними SSD дисками, такими как SanDisk Portable SSD, – более 4 раз быстрее, чем самые быстрые карты SanDisk microSD UHS-I предыдущего поколения*.
Смотри, индустрия хостинга давно сгнила изнутри. Тут всё построено не на сервисе, а на выжимании: продай домен, дожми на апгрейд, подними цену через год.
Мы решили, что пора это хоронить. Поэтому сделали WebHostMost. Не чтобы “откусить долю рынка”, а чтобы не блевать каждый раз, когда ищешь нормальный веб хостинг.
Наша цена - это не “3$ в первый месяц, 9$ потом, и 17$ с третьего, если ты не заметил”.
У нас цена, которую ты видишь - остаётся навсегда, даже если купил со скидкой.
Фикс. Всегда. Без писем с сюрпризами.
LiteSpeed Enterprise (а не бесплатный OpenLiteSpeed)
Redis, HTTP/3, Brotli, Keep-Alive, APC Cache
NVMe-диски
Процессоры Ryzen EPYC
Инфраструктура, где реально есть защита от DDoS, Imunify360 и мониторинг 24/7
Пока другие строят “скорость” через прокси и заклинания, у нас она встроена в основу.
Да, у нас есть реальный бесплатный тариф.
- Без баннеров.
- Без вымогательства “перейдите на PRO, чтобы не лагало”.
- С LiteSpeed, защитой, A+ заголовками и даже поддержкой.
Бесплатный хостинг - не значит ущербный. Это вход в нормальную экосистему, не маркетинговый мусор.
A+ по Security Headers - проверено через securityheaders.com (На секундочку, НИ ОДИН хостинг во всем мире не предоставляет такую защиту сразу "из коробки". А у нас это просто есть. Для всех, даже на бесплатном тарифе).
Поддержка всех стеков: WordPress, Node.js, Python, PHP, Laravel, Symfony, PostgreSQL, MongoDB, MariaDB и даже Perl
Настоящая админка - DirectAdmin с кастомом. Никакого cPanel с интерфейсом 2007 года
Встроенная почта, Cron, SSH, Web терминал, email-алиасы
Бесплатный SSL, домен, CMS-установщик, мгновенная активация
Прозрачный контроль над DNS, файлы, базы, FTP - всё через 1 панель
Вот где мы реально выбиваемся из шаблона:
forum.webhostmost.com - который пока что просто есть =D
docs.webhostmost.com - не “чекни FAQ”, а пошаговые инструкции, гайды, примеры
blog.webhostmost.com - статьи, сравнения, боль и правда про хостинг
Telegram-чат - где отвечают не “менеджеры по клиентскому счастью”, а девопсы, саппорты, дизайнер и даже директор
Мы не делаем апсейл на функции, которые должны быть базой
Мы не ограничиваем пользователей, как shared-хостинги образца 2014
Мы не прячемся за чат-ботами, а реально сидим в комментах
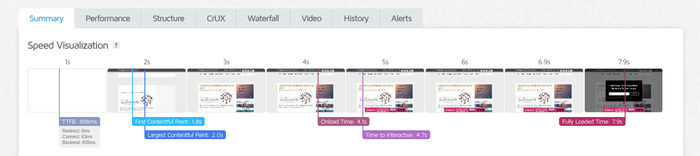
Кстати, вот вам немного сравнений с GTMetrix и SecurityHeaders рандомного UK сайта, который хостится на любом другом хостинге (в этом примере на SiteGround) и на нашем:
SiteGround:
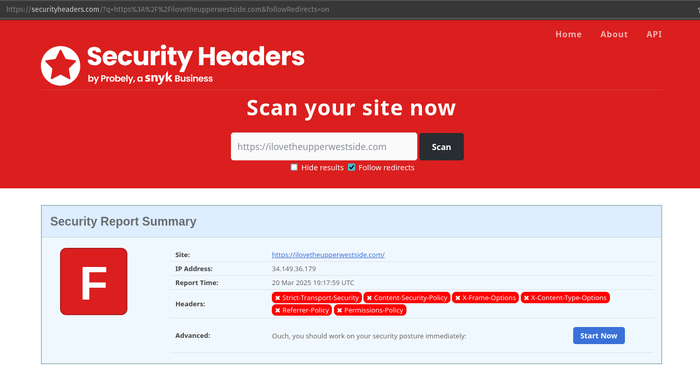
SiteGround SecurityHeaders be like
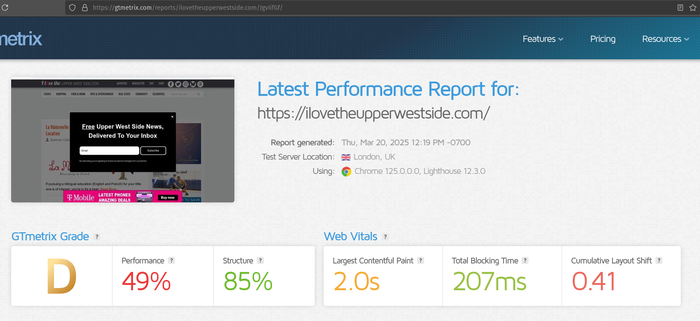
SiteGround GTMetrix be like
WebHostMost:
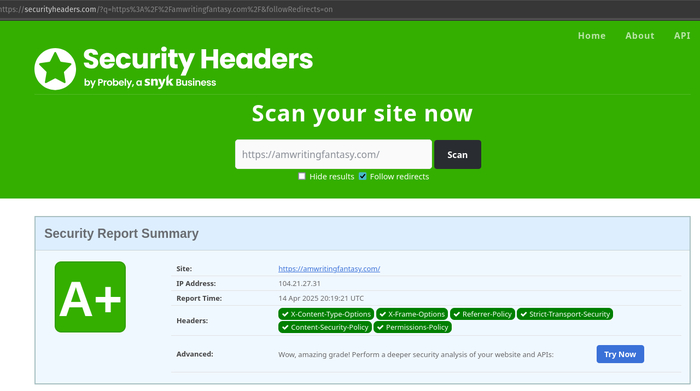
WebHostMost SecurityHeaders be like
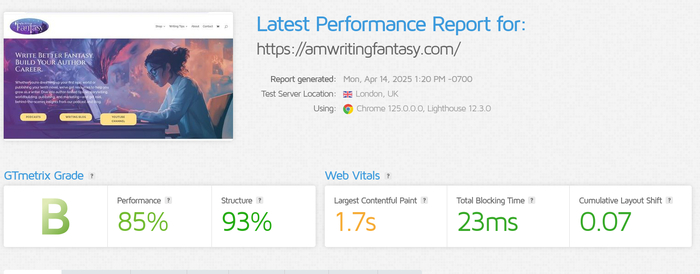
WebHostMost GTMetrix be like
И да, нас можно пнуть, задать неудобный вопрос и даже “о ужас” - поспорить с нами.
Но мы ответим. Мы рядом. Мы - WHM Crew.
Нет сил молчать, мы находимся у порога новых открытий, про нас будут слагать легенды, в храмах, возведённых в нашу честь, будут проводить сеансы восстановления накопителей, и жизнь станет лучше.
Когда-то на работе мы начали менять всем пользователям HDD на SSD. По два-три в месяц, но со временем все компьютеры от-ssd-шились: все стали жить хорошо, не нужно было начинать утро с коллективного чаепития в ожидании, пока компьютер загрузится. Но по прошествии нескольких лет тормоза вернулись, хотя по активности не было нагрузки ни на CPU, ни на диск. Замена комплектующих на более современные ситуацию не исправляла.
Однажды коллега запустил Викторию (hdd.by/victoria) и обнаружил, что на рандомном накопителе сильно упала производительность: график чтения диска был с большими падениями на одних и тех же местах. Следом была попытка сделать полный wipe посредством отправления команды TRIM на все сектора, после чего скорость вернулась к максимально возможной! И так повторилось несколько раз. Для себя мы объяснили этот феномен так: если верить википедии и общепризнанной информации, SSD после записи на ячейку хранит её заряд, и при считывании определяется логическое значение в зависимости от того, в какой диапазон попадает этот заряд. Но со временем заряд начинает "гулять", из-за чего требуется больше времени, чтобы однозначно считать данные. При удалении файла операционная система посылает TRIM на те сектора, которые были заняты информацией, и накопитель сбрасывает их на особое значение, которое не "0" и не "1", а условно "пустой сектор".
Но те сектора, которые были записаны много лет назад, скажем, при установке системы, не обнулялись с момента записи, и с каждым годом они становились всё более и более медленными. В качестве эксперимента мы на нескольких компьютерах замерили графики скорости до и после TRIM-а, и субъективно оценили отзывчивость системы. Пока что каждый раз, без исключения, наш метод помогал, а именно: снять образ диска, провести TRIM всего диска, залить образ обратно.
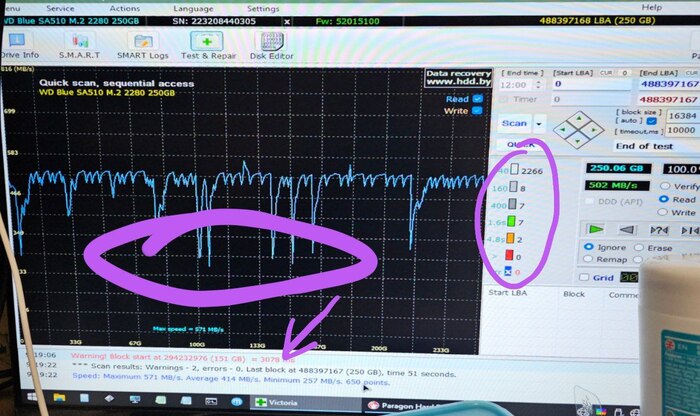
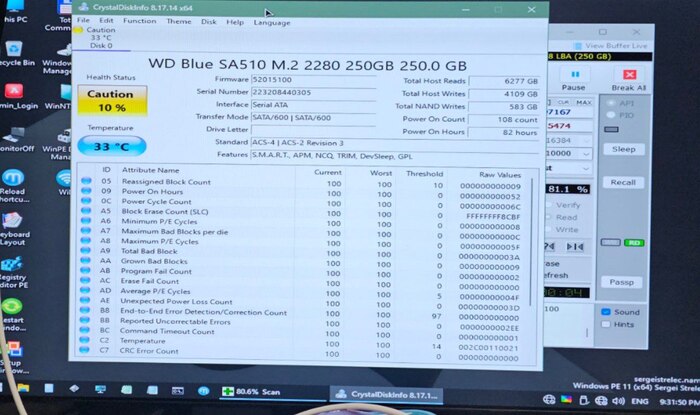
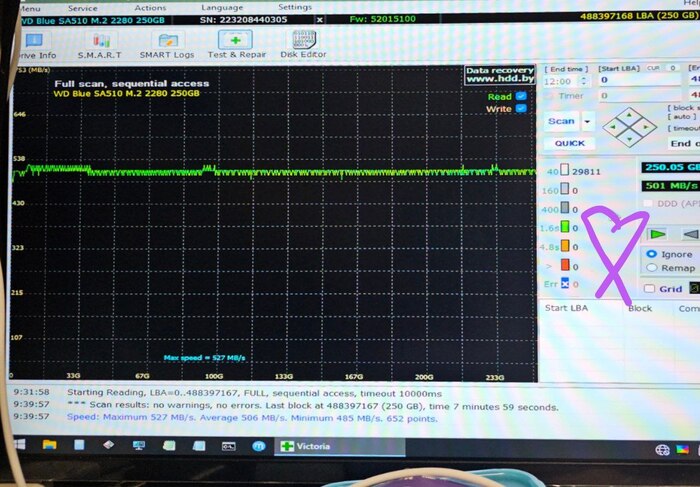
Я не был готов к написанию поста, поэтому не подготовил красивые скриншоты. Но есть фото.
Саташные SSD "тримаются" через Paragon. NVMe-шные же не имеют такой возможности (отсутствует пункт TRIM в методах wipe), поэтому для них используем secure erase из комплекта программ от производителя (к примеру, для Samsung это утилита Magician). CrystalDiskInfo не добавляет в счётчик износа операции TRIM-а.
Это всё лично меня продолжает удивлять: весь мир глобально перешёл на SSD, производители сменили множество контроллеров и (вероятно) избавились от проблем первого дня. Почему же не придумано ни автоматизированных, ни программных методов перезаписи секторов? Может, во всём развитом мире принято выбрасывать старые компьютеры каждые три года, и тормоза там просто не успевают проявиться? Или я что-то не понимаю, и нахожу решение несуществующей проблемы? Так или иначе, корреляция сохраняется: если диск был поделён на два раздела, то падения на графиках будут аккурат совпадать с местами начала этих разделов, и будут отсутствовать в свободной от данных области. И все тормоза точно пропадут после TRIM-а всей области. Не важно, используем ли мы китайские ноунеймы (Apacer), "неймы" (WD Blue), или дорогие понтовые накопители с хорошей репутацией (Samsung 970/980) — все подвержены описанному эффекту. Гуглинг и обращения к дипсику по данной теме не дают никаких результатов, коллеги из сообщества крутят у виска и в шутку рекомендуют проводить дефрагментацию (извилин).
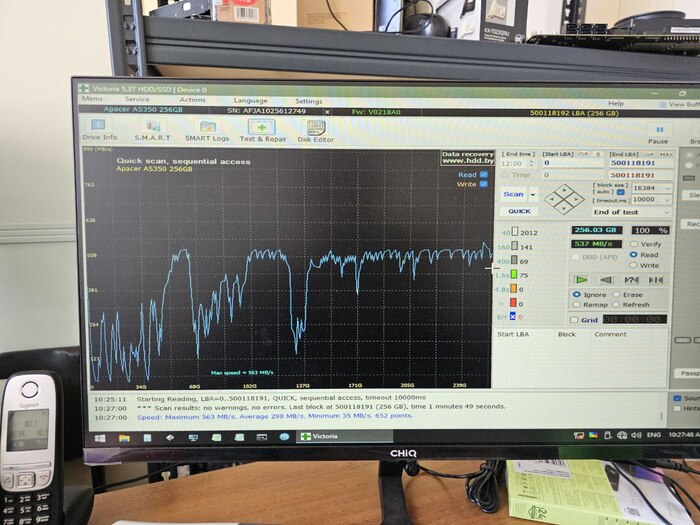
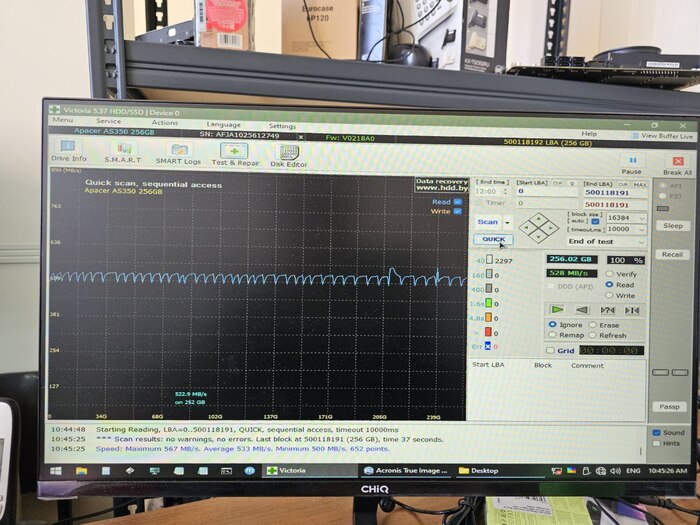
Можете проверить у себя. До и после.
Интересно мнение настоящих пикабушных экспертов. Аргументированное и конструктивное мнение — особенно.
Вобщем из всех дисков что у меня были KingSpec NX-2T на 2тб самое наилютейшее ""Г" даже Reletech и те лучше, а до Fanxiang KingSpec'y вобще как до китая пешком, скорость записи самих ячеек памяти с исчерпание кэша падает до 96мб/сек даже самый дешманский ноутбучный 2,5" HDD пишется быстрее. Reletech пишется на скорости 260мб/сек Fanxiang 1100мб/сек.... все диски на 2Tb.
И да у меня есть с чем сравнивать и 980Pro и PM983 и Corsair mp600 есть обсалютно все на 2tb, mp600 и reletech на одинаковых контроллерах, и визуально деталь в деталь выглядят одинаково, но как оказалось сама Flash память на релетечь имеет низкий ресурс около 600TBW на 2тб диске и низкую скорость.
Ну и последний пост, надеюсь, в эту же серию. ССДшки всё те же, но заказал из Китая теперь вот такую хрень. Написано что она PCI-E 3.0 аж за 160 рублей. Китайским ССД, китайские переходники.
Получил вот такие циферки

И вот это вот 9.49 меня что то сильно напрягает. Как думаете, к чему бы это?
Нужно увеличить ssd nvme на рабочем ноуте без переустановки системы, сейчас диск на 500Гб, будет на 1Тб.

Ранее мы делали перенос с hdd на ssd, также без переустановки ОС; еще измеряли скорость ssd nvme под Win/Linux.
Сейчас, когда всё готово, можно сказать, что все работы укладываются в 30-40 мин. Что было сделано заранее:
куплен новый ssd nvme 1Тб. Диск выбирался по соотношению цена/скорость. на ЯМе нашёлся Apacer SSD AS2280P4U 1TB M.2 PCIe Gen3x4 ниже 6К рублей, скорости 3500/3000, TWB 760Тб, это хорошие показатели (ранее у нас были более медленные диски)
куплен адаптер ssd(nvme)<->usb-c. Адаптер куплен наугад (не реклама!), по отзывам, при цене ниже 1К рублей. Требований было 2 - поддержка nvme и интерфейс USB-C (type C)
Ниже станет понятно, что диск заявленные скорости поддерживает, адаптер также работает верно.
В ноуте Dell 7390 один разъем под nvme. Решено было купить адаптер ssd(nvme)<->usb-c в корпусе с кабелем type C, их много как на Озоне/ЯМе, так и на Али. Выбрали по отзывам, несколько фото:





Сама платка субъективно похожа на 50% того, что продаётся в 2-3 раза дешевле (без корпуса) на Али, со сроком поставки через 1-2 недели.
При подключении ssd с адаптером к компьютеру с usb 2.0 скорость совсем грустная, скорее из-за кабеля:
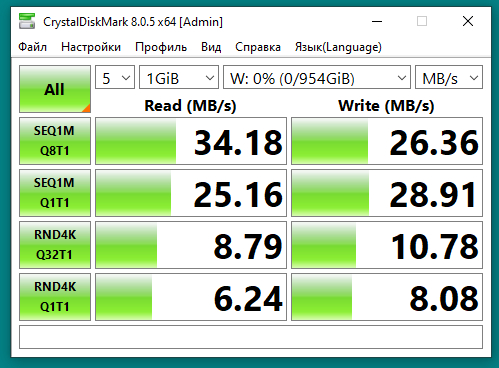
При подключении к ноуту по type C скорость - предел кабеля и/или стандарта (если у кого была выше, пишите в комменты)
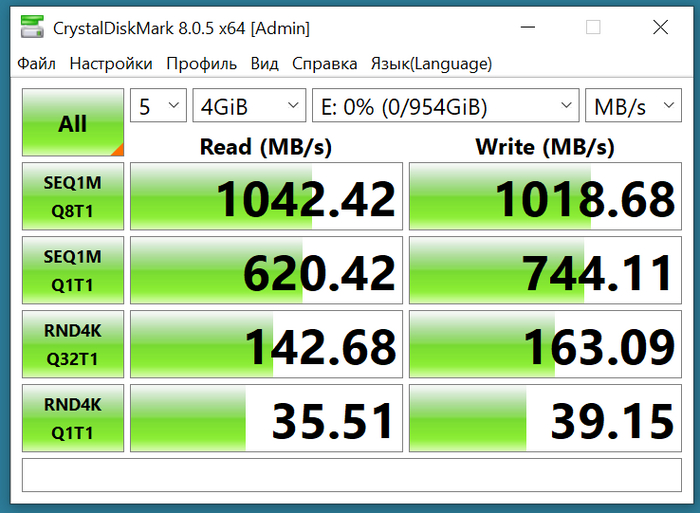
Далее, как в прошлой статье про hdd->ssd:
1) клонируем с помощью Macrium Reflect Free Trials
2) двигаем раздел IM-Magic Partition Resizer Free
1) софт Macrium качается после регистрации на сайте
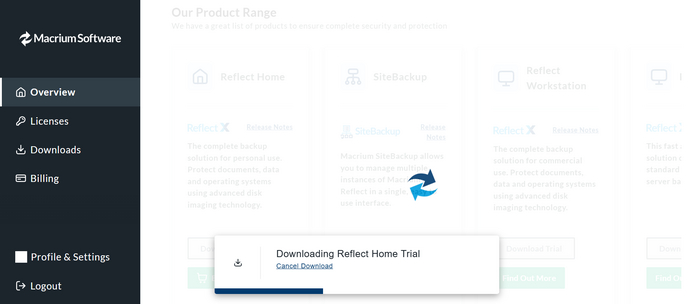
При установке галки можно не ставить, если нужно один раз клонировать диск
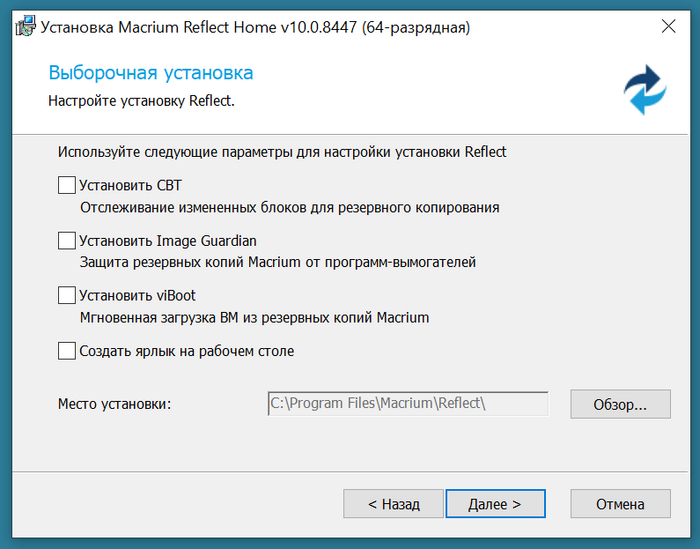
А дальше кликаем на не совсем очевидный пункт интерфейса "Клонировать этот диск"
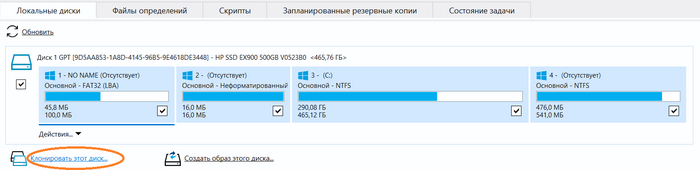
Клонируем один в один
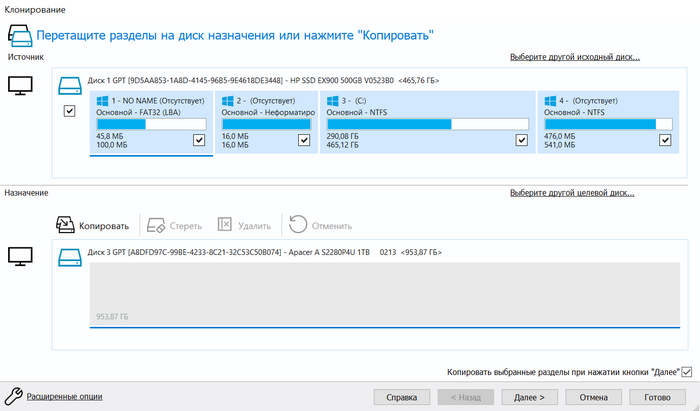
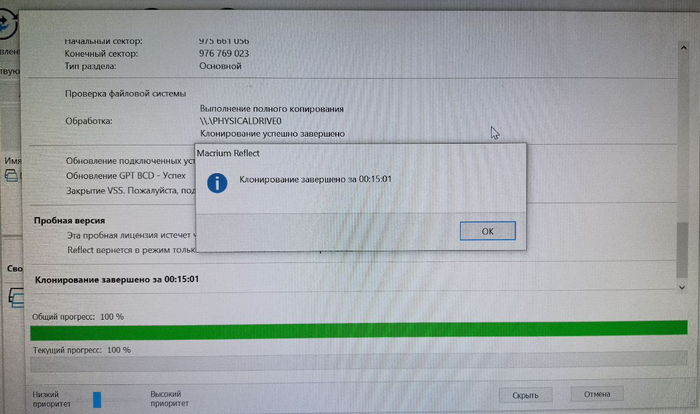
Клонирование 500Гб заняло 15 минут (долго? пишите в комменты)
2) ресайзер у нас установлен 1-2 года назад, используем эту версию

Сначала переносим в конец резервный раздел 500Мб
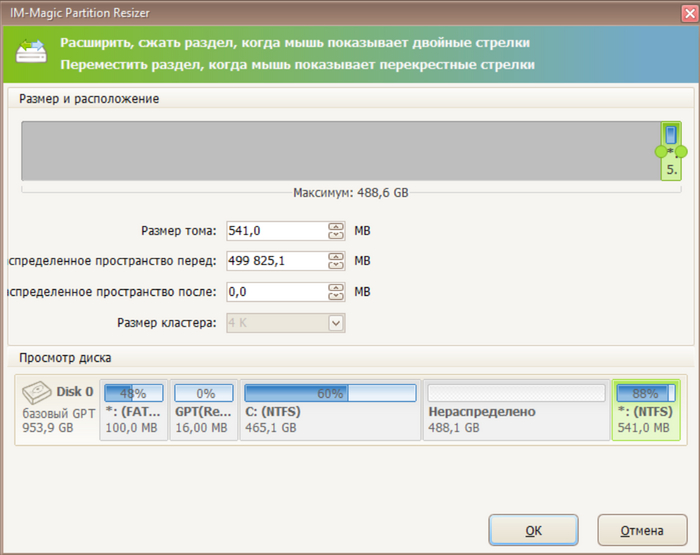
Потом расширяем основной раздел ntfs
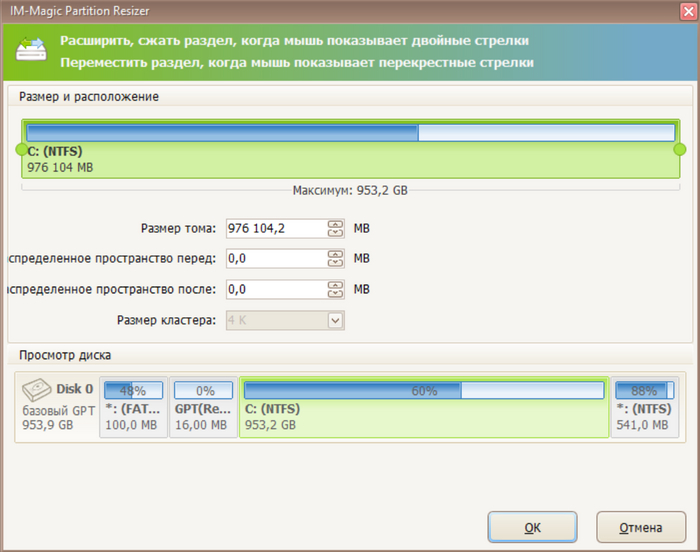
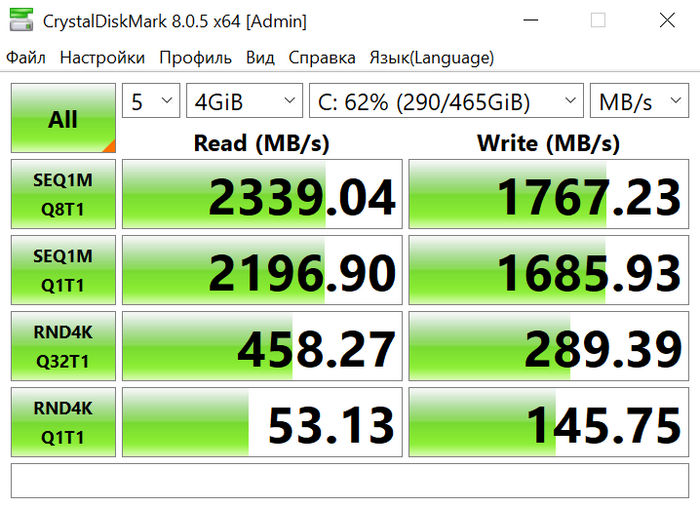
Расширение диска прошло за секунды, рестарт не требовался. Предыдущий диск HP 500GB M.2 2280 EX900 по скоростям вполне устраивал
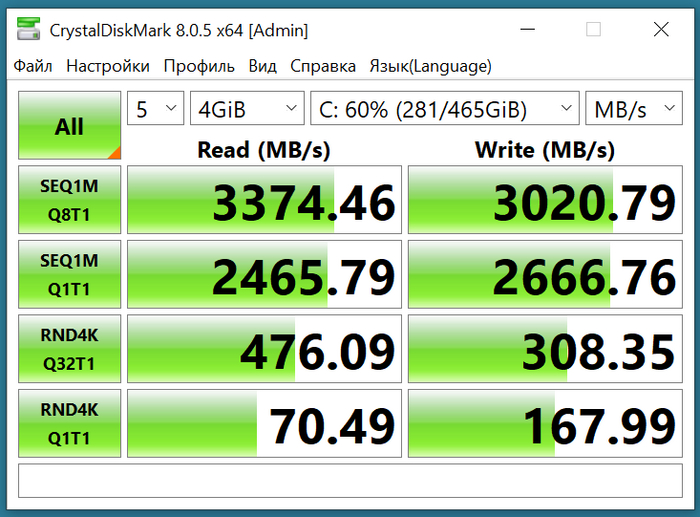
Теперь с Apacer SSD AS2280P4U 1TB имеем хороший прирост скорости
Всем добра!







