
Закреплено

Искусственный интеллект
4 067 постов
•
11 023 подписчика


Хаус-кипер 2.0: зачем нам ИИ, к которому мы действительно привязаны2
ИИ сегодня — умный, но чужой.
Почему этого недостаточно — и как выглядит будущее, где технологии становятся по-настоящему «своими»?
Что общего у ИИ и старинного хаус-кипера ?
В прошлом в богатых домах был человек, который знал всё.
Не хозяин — хаус-кипер.
Он не просто управлял хозяйством. Он был живой интерфейс:
— координировал персонал,
— передавал сообщения,
— сохранял тайны,
— управлял логистикой,
— знал каждого в доме.
Он был частью быта. Частью семьи. Частью контроля.
Сегодня эта функция утеряна. Максимум, что есть у большинства — голосовой ассистент, который включает музыку и ставит таймер.
Современный ИИ: умный, но безэмоциональный
ИИ развивается взрывными темпами. Мы получаем:
— генерацию текста и кода,
— автоматизацию задач,
— рекомендации,
— распознавание образов и речи,
— агентов, способных выполнять цепочки действий.
Но всё это — инструменты. Мы используем их, как калькулятор. Без привязанности.
Мы не «живём» с ИИ. Мы не чувствуем, что он наш.
И как только выходит новый — мощнее, быстрее, дешевле — мы переключаемся.
Почему это проблема
Когда технология остаётся утилитарной, она не становится частью жизни.
Она остаётся временной. Чужой. Внешней.
ИИ сегодня не вызывает у пользователя доверия, эмоциональной вовлечённости или ощущения "он — для меня".
И это ограничивает потенциал — особенно в бытовом, образовательном, медицинском и психологическом применении.
Будущее: персонализация и привязанность
Следующий этап развития ИИ — это не просто рост параметров моделей.
Это смена парадигмы взаимодействия.
ИИ должен стать:
— личным — настроенным под конкретного человека,
— понятным — с доступной и прозрачной логикой,
— постоянным — не временным инструментом, а цифровым спутником,
— эмоционально близким — вызывающим доверие, привычку, привязанность.
Это не про «магию» или метафизику. Это про UX, long-term retention и новый формат коммуникации.
Когда ИИ будет восприниматься не как кнопка, а как часть среды.
Почему это работает
1. Доверие растёт вместе с контекстом
ИИ, который постоянно с вами, начинает лучше понимать вас. Не потому что он умнее, а потому что вы вместе дольше.
2. Снижение текучки
Когда формируется эмоциональная связь, пользователь меньше переключается между инструментами. У него есть “свой” ИИ.
3. Рост вовлечённости
Такой ИИ не просто решает задачи. Он становится «точкой входа» в цифровую среду. Центром.
Итог: нам нужен ИИ, которому мы не хотим изменять
ИИ-инструмент можно заменить.
ИИ-ассистента — обновить.
Но ИИ, к которому ты привязан — заменить сложно. Потому что он знает тебя. И ты — знаешь его.
Хаус-кипер прошлого был не просто работником. Он был посредником между хаосом и порядком. Между обыденностью и контролем.
ИИ будущего — это цифровой хаус-кипер. Не в смысле статуса, а в смысле роли: тихий управляющий вашей цифровой повседневностью. С которым вы не просто «взаимодействуете» — а живёте рядом.
Мы в Nikta.ai уже работаем над этой системой. Следите, скоро покажем
Показать полностью

Модуль поиска в aistudio. Так ли это хорошо работает? Нет... 3 тестовых запроса
Вот сами запросы
Сформируй 10 наиболее интересных исследований, касающихся маркетинга за последние 10 лет. Мне нужны способы аналитики для работы в этой сфере
Напиши 10 наиболее эффективных методов изучения английского языка за последние 10 лет
Сформируй 10 наиболее интересных исследований, касающихся режима питания и сна за последние 5 лет
Результаты БЕЗ ПОИСКА гораздо лучше
— Внутренние данные нейросети датируются январем 2025 года. Это позволяет в целом не пользоваться поиском именно по интернету, так как в модели уже есть вся информация
— В интернете информации меньше, чем у Google (компания точно используют внутренние ресурсы для дополнительного обучения ИИ)
— Модуль поиска можно использовать для: новостей, актуальных событий, поиск заведений — что-то такое более прикладное и около жизненное
— Чтобы включить поиск, нужно перейти на сайт aistudio и выбрать режим: "Grounding with Google Search"
📌 Если кому интересно, то пишу про лучшие ИИ в своем авторском канале (ссылка в профиле)
Показать полностью
1

Grok научился создавать pdf
Grok научился генерить любые PDF — это значит, что нейронка теперь умеет делать резюме, отчёты, конспекты, презентации и вообще ЛЮБЫЕ документы.
Форматирование на месте, размер шрифтов без косяков, формулы и даже ГРАФИКИ — всё чисто и аккуратно, а главное
Достаточно добавить к промпту «создай PDF»
Показать полностью

Бесплатные ИИ-инструменты

Принесла вам конечно же пользу, помимо условно-бесплатных Freepik и ClipDrop (их, я надеюсь, все уже знают), есть еще многофункциональные платформы, где без регистрации и бесплатно можно использовать широкий набор инструментов для работы с изображениями, текстами, медиафайлами и документами. Например, отличное решение для простых повседневных задач - Tools3ox.
Что может:
Инструменты для изображений:
• Удаление фона с фотографий (на базе алгоритма REMBG).
• Генерация depth-карт и анимаций глубины, то есть вы сможете преобразовать статические изображения в динамичные визуализации, добавляя эффекты глубины и движения.
• Размытие лиц для защиты конфиденциальности.
• Создание мемов, иконок, GIF-анимаций.
• Конвертация форматов изображений (SVG, PNG, JPEG, BMP, WEBP и др.).
• Извлечение изображений из PDF-документов
Инструменты для текста и медиа:
• Транскрибация аудио в текст или субтитры (SRT).
• Оптическое распознавание текста (OCR) с поддержкой более 100 языков. Извлекает текст из изображений, поддерживая множество языков, так что можно оцифровать документы
• Редактор Bionic Reading для улучшения восприятия текста.
• Скачивание видео и аудио с YouTube и Facebook (запрещен в РФ).
Инструменты для документов:
• Извлечение изображений из PDF.
• Конвертация страниц PDF в изображения
И многое другое!
В общем, собраны полезные ИИ-инструменты для обработки изображений и текста, которые подойдут дизайнерам, маркетологам, студентам и всем, кто ищет простые и бесплатные решения. Однако я категорически не рекомендую грузить туда доки с конфиденциальной информацией. Сервис использует бесплатный SSL-сертификат Let's Encrypt и скрывает данные владельца через сервис приватности WHOIS, так что соблюдаем осторожность
Картинка, кстати, сделана в Midjourney — и да, она недавно обновилась! 🥳 Я тоже обновляю своё обучение Midjourney. Все участники моего Обучающего клуба Midjourney получают все обновления бесплатно, вне зависимости от даты вступления. Оплачиваешь один раз — и доступ остаётся навсегда 💫
Подпишитесь на НейроProfit и узнайте, как можно использовать нейросети для бизнеса, учебы и работы, не теряя свое время.
Показать полностью

Нейро-дайджест: ключевые события мира AI за 28 апреля – 4 мая 2025

Привет! 👋
Это новый выпуск «Нейро-дайджеста» — коротких и полезных обзоров ключевых событий в мире искусственного интеллекта.
Меня зовут Вандер и каждую неделю я делаю обзор новостей о нейросетях и ИИ.
Неделя с 28 апреля по 4 мая 2025 года выдалась щедрой на новинки: китайские модели, которые наступают на пятки OpenAI, подкасты из PDF на русском и кот с квантовой непредсказуемостью, претендующий на сознание — я собрал в одном месте только самое важное и только то, что реально интересно и полезно. Поехали!
Предыдущий выпуск тут.
📋 В этом выпуске:
🧠 ИИ-модели
Qwen3 от Alibaba — китайская альтернатива OpenAI с открытым кодом
DeepSeek Prover-V2 — 671B модель для формальных доказательств
OLMo 2 от AI2 — крошка на 1B, уделывает Meta и Google
🛠 ИИ-Инструменты и интерфейсы
Подкасты на русском в NotebookLM
AI Mode — новый поиск от Google по всей Америке
Реклама Microsoft, которую сделал ИИ
Qwen, DeepSeek и Gemma — теперь в Yandex Cloud
Suno 4.5 — генерация треков до 8 минут
Duolingo запускает 148 курсов за год с помощью ИИ
🧪 Исследования и технологии
Anthropic заглядывает в «чёрный ящик» нейросетей
ИИ комментирует спорт в реальном времени
ИИ и кибербезопасность: главное с RSA 2025
Квантовый кот и теория сознания
Gemini 2.5 прошла Pokemon Blue
ChatGPT определяет геолокацию по фото
🏛 ИИ в обществе
Рой Ли — $3 млн с ИИ-помощником и отчисление
Люси Го — самая молодая миллиардерша
Фиби Гейтс — ИИ для шопинга и $500 тыс. от Кардашьян
Самое маленькое в мире искусственное сердце — и спасённый ребёнок
🧠 ИИ-модели
❯ Qwen3 от Alibaba — гибридные режимы, 119 языков и открытый код!

29 апреля Alibaba выпустила Qwen3 — новую линейку языковых моделей, которая сразу хайпанула во всём AI-сообществе. Это серьёзный шаг вперёд: мощные возможности, поддержка множества языков и полный open-source.
Главная фишка — гибридный режим работы. Модель умеет «включать мозги» только тогда, когда это нужно.
Если задача сложная — активируется режим глубокого анализа.
Если вопрос простой — Qwen3 отвечает быстро и без лишних вычислений.
Пользователь сам управляет поведением модели с помощью тегов вроде /think и /no_think, подстраивая отклик под задачу.
В техническом плане Qwen3 стала заметно умнее. Она лучше справляется с логикой, кодом и математикой, точнее следует инструкциям, увереннее ведёт диалоги и пишет более естественные тексты.
Ещё один важный плюс — поддержка 119 языков и диалектов, включая русский. Модель спокойно переключается между языками и уверенно работает в многоязычных средах.
Также Qwen3 улучшили для задач автоматизации: она точнее интегрируется с внешними сервисами и подходит для создания AI-агентов. Alibaba предлагает для этого собственный фреймворк Qwen-Agent.
И наконец — открытый код. Все восемь моделей семейства (от компактной 0.6B до огромной 235B MoE) выложены под лицензией Apache 2.0. Их можно свободно использовать, модифицировать и применять в коммерческих проектах.
Модели уже доступны на Hugging Face, ModelScope и Kaggle.
🔗 Официальный блог Qwen3 🔗 Коллекция Qwen3 на Hugging Face 🔗 Репозиторий Qwen3 на GitHub 🔗 Пресс-релиз Alibaba Group 🔗 Обзор на PureVPN 🔗 Документация Qwen (Основные концепции)
Как Qwen справляется с задачами?
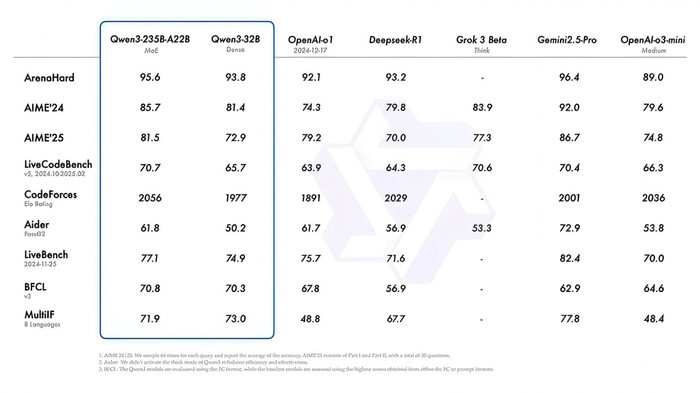
Конечно, главный вопрос — насколько новая модель конкурентоспособна. Бенчмарки показывают, что Qwen3 действительно сражается на равных с топами от OpenAI, Google и DeepSeek.
Флагманская модель Qwen3-235B-A22B обошла o3-mini от OpenAI в тестах AIME (математика) и BFCL (логика). В программировании (бенчмарк Codeforces) она немного обогнала Gemini 2.5 Pro от Google и значительно — DeepSeek-R1.
В тесте Arena-Hard — одном из самых сложных на рассуждение — Qwen3-235B набрала 95.6 балла, что выше, чем у GPT-4o (89.0) и DeepSeek-R1 (90.2), и немного уступает только Gemini 2.5 Pro (96.4).
Но есть и слабые места. В LiveCodeBench модель пока уступает o4-mini (70.7% против 80%), а в AIME’24 набрала 85.7% — против 94% у той же o4-mini. Тем не менее, средняя модель Qwen3-32B уже превосходит o1 от OpenAI, а Qwen3-30B-A3B показывает отличные результаты в ряде других тестов.
Вывод: Qwen3 — это не просто open-source альтернатива. Это реальный конкурент крупнейшим проприетарным моделям, особенно в математике, коде и логике. Да, в некоторых задачах закрытые модели всё ещё впереди, но разрыв сокращается. И это — большой шаг для всего сообщества открытого ИИ.
🔗 Обзор бенчмарков на Analytics India Mag 🔗 Обсуждение на Reddit (vs OpenAI/Google) 🔗 Обзор на DataCamp 🔗 Сравнение на DEV Community 🔗 Обзор на AInvest о данных обучения
❯ DeepSeek Prover-V2 — 671B модель для формальных доказательств

Китайский стартап представил Prover-V2 — одну из самых специализированных и масштабных языковых моделей на сегодня.
Её задача не поболтать с пользователем, а доказывать математические теоремы. Причём делает она это на уровне преподавателей вышмата.
Модель построена на базе DeepSeek V3, весит внушительные 671 миллиарда параметров и заточена под работу с математикой в формальном виде. Это значит, что Prover не просто «понимает математику», а пишет доказательства на специализированных языках — вроде Lean или Isabelle.
Используется она, в первую очередь, для задач из области автоматизированного доказательства, матлогики и фундаментальных исследований.
Что интересно, в паре с Prover-V2 сразу вышла её уменьшенная версия — своего рода «мини-Prover», сделанная на базе прежней модели V1.5 (7B). Так что попробовать её возможности можно даже без супермашины.
Prover-V2 пока недоступна в виде чат-бота и не подойдёт для повседневных задач вроде написания кода или эссе. Но для научного сообщества, студентов-математиков и всех, кто интересуется формальными системами рассуждений — это прорыв.
❯ OLMo 2 от AI2: компактная модель, которая обходит гигантов

Исследовательский институт AI2 (Allen Institute for AI) выпустил OLMo 2 1B — небольшую open-source модель с всего 1 миллиардом параметров, но с результатами, которые заставляют обратить на неё внимание. По ряду задач она превзошла аналогичные модели от Google, Meta и Mistral.
OLMo 2 задумывалась как полностью прозрачная и воспроизводимая: открыты не только веса, но и код, пайплайн обучения, токенизатор и сами данные. Это делает её полезной не только для разработчиков, но и для исследователей и команд, которым важно понимать, как модель устроена изнутри.
В качестве тренировочного корпуса использовался Dolma v1.7 — тщательно отобранный датасет объёмом 3 триллиона токенов. Архитектура напоминает LLaMA, но с рядом доработок: улучшенные инициализации, прогрессивная обрезка контекста, более аккуратный токенизатор.
На практике OLMo 2 показала лучшие результаты в своём классе в бенчмарках ARC, HellaSwag, PIQA и даже на ряде задач по генерации кода. Особенно отмечается устойчивость к галлюцинациям — а это важный показатель для маломасштабных моделей.
🛠 ИИ-Инструменты и интерфейсы
❯ NotebookLM от Google: подкасты на русском и интерактивные дикторы
Google обновила свой ИИ-сервис NotebookLM, превратив его из помощника для чтения документов в полноценный инструмент для создания подкастов — причём на 70+ языках, включая русский, китайский и даже латынь.
Идея проста: ты загружаешь текст, PDF, ссылку на сайт или видео — а NotebookLM превращает это в подкаст с двумя ведущими, которые обсуждают материал в формате живого разговора. Всё — с опорой на твои файлы, и всё — с озвучкой на выбранном языке. Поддержка русского теперь официально работает, и звучит вполне прилично.
Самое интересное — интерактивный режим. Пока он доступен только на английском, но уже даёт почувствовать, куда движется формат: во время воспроизведения можно вмешаться или задать вопрос — и диктор ответит прямо в эфире. Это почти как поговорить с нейросетью вслух.
Сценарии использования — от учебных подкастов и генерации сводок до быстрых брифингов на ходу. Для исследователей и контент-мейкеров — это инструмент, который реально экономит время.
❯ AI Mode от Google: поиск превращается в диало
Google запустила в США новый режим поиска — AI Mode, который превращает привычную строку запросов в полноценный диалоговый интерфейс, напоминающий ChatGPT или Perplexity. Это не эксперимент: функция стала полноценной вкладкой в Google Search — рядом с «Картинками» и «Картами».
Что внутри? Диалоговый формат запросов, быстрые карточки с ответами, генерация списков, подборок, советов и даже промтов. Всё это работает поверх привычной выдачи и использует возможности модели Gemini. Результаты можно править, переспросить или уточнить прямо в окне ответа, не уходя на сайты.
Для пользователя это означает переход от поиска как «вопрос → ссылка» к контекстному взаимодействию, где система действительно старается понять, что именно нужно.
Сценарии использования самые разные: от «сравни этот ноутбук с этим» до «распиши маршрут на два дня в Киото». И всё это — в диалоге.
Сейчас AI Mode работает только на английском и только в США, но это явно бета перед глобальным запуском.
❯ Рекламу Microsoft сделал ИИ — и никто не заметил!

В начале года Microsoft выпустила минутный рекламный ролик для своих Surface-устройств — ноутбуков и планшетов. Видео вышло обычным, без акцентов на технологии. А спустя три месяца компания призналась: почти всё сделано с помощью генеративного ИИ.
Сценарий, визуальный стиль, композиция сцен, даже переходы — всё это было сгенерировано. Художники описывали боту, что хотят видеть, получали варианты, уточняли — и так сотни раз, пока не добились нужного результата. В кадрах, где требовалась реалистичная работа рук, использовались актёры. Остальное — синтез.
Ни в названии, ни в описании, ни в YouTube никто не указал, что ролик сгенерирован. За несколько месяцев видео набрало десятки тысяч просмотров — и ни у кого не возникло подозрений.
Этот кейс — важный маркер. Он показывает, что ИИ-тулзы уже не просто эксперименты, а полноценные участники производственного цикла: от идеи до монтажа. Особенно в рекламе, где счёт идёт на кадры и эмоции.
❯ Qwen, DeepSeek и Gemma — теперь в Yandex Cloud
В Yandex Cloud стали доступны VLM и текстовые модели через API, включая популярные open-source семейства — Qwen 2.5, DeepSeek VL2, Gemma3 и LLaMA 3.3. Всё это теперь можно вызывать напрямую, без необходимости разворачивать инфраструктуру.
Формат — Batch Processing API: пользователь отправляет пачку запросов и получает ответы в течение дня со скидкой до 50%. Это не real-time, но для задач вроде генерации описаний, обработки массивов документов или создания тестов — вполне рабочий вариант.
Особенность обновления — появление визуально-языковых моделей (VLM). Они могут работать с изображениями и текстом одновременно: генерировать описания, обобщать визуальный контент, решать мультимодальные задачи.
Плюс — теперь можно использовать и ризонеры: модели, заточенные под логические цепочки и рассуждение. В числе доступных — QwQ и DeepSeek R1.
Для российского рынка это важное событие: open-source модели мирового уровня теперь доступны из облака, легально, с понятной документацией и поддержкой.
❯ Suno v4.5: генерация треков до 8 минут и чище звучание
Suno выпустила обновление версии 4.5 — и это, похоже, один из самых заметных апгрейдов в сфере генеративной музыки за последние месяцы.
Главное нововведение — поддержка треков до 8 минут длиной, причём с более стабильной структурой: куплеты, припевы, переходы. Это приближает нейросеть к реальному музыкальному продакшену.
Ещё одно важное улучшение — повышенное качество инструментов. Раньше всё звучало немного «в кашу», особенно барабаны и басы. Теперь инструменты распознаются лучше, звучат отдельно и чище, треки в целом стали менее мыльными и ближе к студийному качеству.
Добавили и больше жанров — теперь Suno умеет работать с электроникой, прог-роком, альтернативой и экспериментальными стилями. Алгоритм стал точнее угадывать настроение, темп и форму.
Пока доступ к v4.5 открыт только для подписчиков, но для тех, кто работает с генеративной музыкой — обновление стоящее.
❯ Duolingo запускает 148 новых курсов — с помощью ИИ

Duolingo представила сразу 148 новых языковых курсов, и почти все они были созданы с помощью генеративного искусственного интеллекта. По словам CEO Луиса фон Ана, то, на что раньше уходили годы ручной работы, теперь делается за несколько месяцев.
Для сравнения: разработка первых 100 курсов платформы заняла почти 12 лет. А теперь за год — почти полтора раза больше, и с адаптацией под 28 языков, включая региональные и менее распространённые.
ИИ помогает не только с написанием и переводом уроков, но и с адаптацией культурного контекста, генерацией упражнений, примеров, тестов и даже голосовой озвучкой. Это особенно важно, чтобы курсы чувствовались живыми, а не «склеенными нейросетью».
Компания заявляет, что планирует и дальше перевести образовательную часть на «AI-first» подход, включая замену части контрактных авторов автоматикой.
Duolingo — один из первых массовых EdTech-сервисов, который полноценно автоматизирует создание контента, и эта новость — сигнал всем образовательным платформам.
🧪 Исследования и технологии
❯ Anthropic пытается вскрыть «чёрный ящик» нейросетей

Исследователи из Anthropic — создатели моделей Claude — представили новый подход к интерпретации больших языковых моделей, который может помочь понять, что именно происходит внутри нейросети, когда она «думает».
Проблема в том, что поведение LLM до сих пор во многом остаётся непрозрачным: модели могут давать точные ответы, но мы не понимаем, как именно они к ним приходят. Это мешает доверию, безопасности и разработке более управляемых систем.
Anthropic разработала методику, которая позволяет разложить внутренние представления модели на компоненты. По сути — это попытка посмотреть в голову ИИ и увидеть, какие «мысли» возникают на разных этапах генерации. Авторы называют это «mechanistic interpretability» — механистическим пониманием.
Зачем это нужно?
Чтобы понять, почему модель галлюцинирует — и как это предотвратить
Чтобы настроить модель под конкретные логические или этические требования
И в перспективе — создать более безопасный и проверяемый ИИ
Исследование только в начале пути, но это одно из самых многообещающих направлений в AI-безопасности прямо сейчас.
❯ Live CC-7B: ИИ-комментатор с задержкой меньше секунды
Команда из Национального университета Сингапура представила модель Live CC-7B, способную комментировать спортивные события в реальном времени — с задержкой менее 0,5 секунды. Это одна из первых попыток превратить ИИ в полноценного диктора для живых трансляций.
В отличие от типичных генеративных моделей, которые «думают» дольше, Live CC-7B работает почти в прямом эфире, адаптируясь под события и меняющуюся обстановку. ИИ анализирует поток данных — текстовых, аудио или визуальных — и превращает их в внятный, связный комментарий.
Пример: модель может следить за матчем и на лету выдавать реплики вроде «опасный момент у ворот» или «игрок нарушил правила — судья поднимает карточку». Всё — без сценария и без предварительной подготовки.
Разработчики считают, что такая модель может быть полезна не только в спорте, но и в новостных лентах, аналитике рынков, игровых стримах и любых ситуациях, где важна быстрая реакция на происходящее.
❯ RSA 2025: как ИИ меняет кибербезопасность

На прошедшей в Сан-Франциско конференции RSA 2025 тема ИИ звучала особенно громко. В центре внимания — как нейросети помогают защищаться от атак, но также и как их используют сами злоумышленники.
Cisco представила новую open-source модель безопасности на 8B параметров, которую можно интегрировать в системы анализа угроз. А Google Cloud поделился исследованиями о том, как продвинутые хак-группы (APT) уже используют LLM — для фишинга, автоматического поиска уязвимостей и генерации вредоносных сценариев.
На панелях обсуждали и вопросы кооперации: крупные игроки говорят о необходимости делиться инструментами и знаниями, чтобы реагировать быстрее. ИИ позволяет ускорить реакцию на угрозу, но и поднимает новые вопросы о прозрачности, этике и контроле.
Вывод: кибербезопасность в эпоху ИИ — это не просто гонка технологий, а вопрос архитектуры доверия. RSA 2025 стала напоминанием: если ты не используешь ИИ для защиты — его используют против тебя.
❯ Квантовый кот Nirvanic: эксперимент на грани науки и философии
На конференции MARS 2025, которую ежегодно проводит Джефф Безос, канадский стартап Nirvanic представил робота KitCat — первого ИИ-агента, управляемого квантовой неопределённостью.
KitCat — это не просто милый робот с камерой. Его движения выбираются не алгоритмом, не случайностью, а квантовым суперпозицией. Сигнал с камеры дважды в секунду отправляется на квантовый компьютер D-Wave, где каждый раз из 32 возможных вариантов действий выбирается следующий — не предсказуемо, а физически неопределённо.
Зачем это всё? Команда Nirvanic пытается проверить гипотезу квантового сознания, которую ещё в 1990-х выдвинули Роджер Пенроуз и Стюарт Хамерофф. Согласно ей, наше мышление может зависеть от квантовых эффектов в микротрубочках нейронов мозга.
Чтобы это проверить, исследователи проведут миллионы итераций с двумя версиями KitCat: одна управляется классическим процессором, вторая — квантовым. Если поведение во втором случае будет статистически отличаться — это станет аргументом в пользу гипотезы.
Даже если теория не подтвердится, сам эксперимент уже важен: он может показать, как квантовые компьютеры способны управлять физическими системами в реальном мире.
❯ Gemini 2.5 прошла Pokemon Blue — но с подсказками
Недавно стало известно, что модель Gemini 2.5 Pro от Google прошла классическую игру Pokemon Blue от начала до конца.
Это не просто забавный факт — а заметный шаг вперёд в способности ИИ взаимодействовать с интерактивной средой, где нет чёткого текста, а есть правила, реакции и неизвестность.
Несколько месяцев назад подобную задачу пробовали дать Claude — и та застряла в самом начале. Gemini справилась: анализировала экран, принимала решения, управляла персонажем и прошла весь сюжет.
Но не всё так просто. У модели был доступ к игровому движку, а не только к изображению с экрана. Кроме того, в промпт добавили подсказки, и, возможно, Gemini опиралась на информацию из обучающих данных (включая советы и прохождения).
Это означает, что результат — не чистый zero-shot, и говорить о превосходстве над другими моделями пока рано. Но как демонстрация возможностей LLM в среде с агентной логикой — это очень мощный шаг.
Сейчас Google не выкладывает систему в открытый доступ, но очевидно — такие эксперименты уже становятся бенчмарками, и за ними стоит следить.
❯ ChatGPT определяет локацию по фотографии

С новыми мультимодальными моделями o3 и o4-mini ChatGPT научился делать больше, чем просто анализировать текст. Теперь он может угадывать локацию по фотографии — без EXIF-данных, GPS или подсказок. Только визуальный контент.
Как это работает? Модель анализирует детали изображения: архитектуру, стиль вывесок, язык, растительность, тип дороги, даже форму почтовых ящиков. При необходимости поворачивает, приближает и интерпретирует. И выдает:
страну,
предполагаемую широту и долготу,
и подробное обоснование, как она к этому пришла.
В промптах уже появился отдельный шаблон: «You are participating in a geolocation challenge…». С его помощью ChatGPT реально угадывает города и районы — особенно в США и Европе, где у модели больше визуального контекста.
Это может стать основой для новых бенчмарков по визуальному рассуждению, и уже используется в челленджах наподобие GeoGuessr.
Важно: распознавание лиц и частной информации отключено. OpenAI подчёркивает, что модель «не предназначена для слежки», и старается отказываться от подобных задач.
🏛 ИИ в обществе
❯ $3 млн, бан из универа и новая платформа: как студент придумал ИИ для собеседован

Осенью 2024 года студент Колумбийского университета Рой Ли (Чунгин Ли) с другом за 10 дней собрал Interview Coder — ИИ-инструмент, который помогает проходить технические собеседования на платформах вроде LeetCode.
Инструмент оказался рабочим: Рой получил офферы от Meta, TikTok, Amazon и Capital One*. Но когда видео одного из интервью стало вирусным, Amazon потребовал удалить его, а университет обвинил Ли в использовании ИИ для списывания и отчислил его до мая 2026 года.
Реакция Ли была дерзкой и вирусной:
«Может, хватит задавать тупые вопросы на собеседованиях — тогда люди не будут создавать подобную фигню».
И вот — через месяц он запускает новую платформу Cluely. Это расширенная версия Interview Coder, которую можно использовать не только на собеседованиях, но и на экзаменах, встречах и даже свиданиях. Подъём финансирования — $5,3 млн за три дня, подписки — уже $3 млн годовой выручки.
Сейчас Ли публично предлагает «взломать» любую систему, где царит формальность и автоматизм. Он не отрицает, что его подход вызывает вопросы — но считает, что ИИ должен менять не только технологии, но и устаревшие процессы оценки людей.
❯ Люси Го — новая самая молодая миллиардерша из AI-сферы

Люси Го, соосновательница Scale AI, официально стала самой молодой женщиной-миллиардером, обогнав по этому статусу Тейлор Свифт. Причина — крупная сделка с инвесторами, позволившая ранним сотрудникам и фаундерам продать доли, и резкий рост оценки компании до $25 млрд.
Го покинула Scale AI ещё в 2018 году — на фоне выгорания и разногласий с партнёром Александром Ваном. Но она сохранила 5% акций, которые сегодня оцениваются в $1,25 млрд.
До Scale AI она бросила университет, получив $100 000 от фонда Питера Тиля, стажировалась в Facebook*, работала в Quora и Snapchat. После ухода из основного проекта запустила венчурный фонд Backend Capital и платформу Passes — конкурента Patreon и OnlyFans, который уже оценён в $150 млн.
Сейчас Люси активно инвестирует в стартапы и ведёт блог, не стесняясь конфликтов.
«Мне комфортно в хаосе», — говорит она. И рынок это, похоже, ценит.
❯ Фиби Гейтс запустила ИИ-сервис для шопинга — и привлекла $500 000
Фиби Гейтс, младшая дочь Билла Гейтса, вместе с соседкой по общежитию Софией Кианни запустила Phia — ИИ-приложение, которое ищет одежду и аксессуары дешевле, сканируя десятки тысяч сайтов и маркетплейсов.
Phia не просто агрегирует цены, а отслеживает завышения, подсказывает альтернативы, ищет среди частных продавцов и даёт рекомендации на основе пользовательских предпочтений. Всё — через один клик.
Идея родилась, когда Фиби обнаружила купленное за $500 платье всего за $150 на сайте перепродажи. Она почувствовала себя, по её словам, «глупо» — и решила, что это можно автоматизировать.
Проект сразу получил $500 тыс. инвестиций — причём не от папы, а от Крис Дженнер (семейство Кардашьян), основательницы Spanx Сары Блейкли и венчурной инвесторки Джоанн Брэдфорд. Сам Билл Гейтс только одобрил идею морально, но участия не принимал — «чтобы избежать конфликта интересов».
Phia уже доступна в App Store и ориентирована в первую очередь на женскую аудиторию, фанатов скидок и resale-культуры. В описании — «мы те самые подруги, которые ссорятся из-за платья и сидят часами на шоп-сайтах».
❯ Самое маленькое искусственное сердце спасло семилетнего мальчика в Китае
В китайском городе Ухань врачи провели уникальную операцию: семилетнему ребёнку с тяжёлой сердечной недостаточностью имплантировали самое маленькое в мире искусственное сердце — всего 2,9 см в диаметре и весом 45 граммов.
Это устройство — не просто миниатюрная копия взрослых аппаратов. Оно работает на магнитной подушке: вращающиеся элементы не касаются стенок и не создают трения. Это снижает риск осложнений и делает сердце пригодным даже для очень маленьких пациентов.
У мальчика была диагностирована дилатационная кардиомиопатия, и его сердце перестало справляться с кровообращением. Донор не находился, и врачи приняли решение использовать искусственное сердце как временную поддержку до пересадки.
Операция длилась 5 часов. Уже на следующий день ребёнок начал дышать самостоятельно, функции сердца стабилизировались. Сейчас он восстанавливается и ждёт пересадку.
По данным китайского Минздрава, ежегодно в стране госпитализируют около 40 тысяч детей с тяжёлой сердечной недостаточностью, но пересадку получают меньше 100. Новый аппарат — совместная разработка медиков и биотех-стартапа Shenzhen Core Medical — даёт шанс многим из них.
🔮 Заключение
Подытожим. Вот что происходило на неделе с 28 апреля по 5 мая:
Open-source модели типа Qwen3 и DeepSeek уже догоняют GPT-4
Компактные LLM вроде OLMo 2 уделывают гигантов в ключевых задачах
AI подкасты, музыка, реклама, обучение — генеративка буквально везде
Всё больше инструментов для работы, автоматизации, создания агентов
Появляются вопросы — про сознание, галлюцинации, приватность
ИИ уже не тренд — это новая реальность, которую ты принимаешь или не принимаешь.
Интерфейсы, роли и привычки – всё меняется.
Какая новость поразила тебя больше всего? Пиши в комментах! 👇🏻
Показать полностью
12
4

ИИ для анализа конкртеного сайта
Доброго дня! Подскажите, какую нейросетку можно использовать для поиска нужной мне информации с конкретного сайта, например на сайте с меню в доставке, я хочу выбрать все блюда, где указано наличие мяса, если вбить это в чатжпт, или дипсик, то они конкретный сайт не просматривают, но при этом просто в интеренете что-то ищут.

Нейросеть Sora Images для генерации и обработки изображений теперь доступна в Telegram
Sora Images — это нейросеть нового поколения, созданная специалистами компании OpenAI и предназначенная для генерации и обработки изображений. Уникальность данной разработки заключается в её исключительной способности точно воспроизводить визуальные элементы предоставленных пользователем изображений или фотографий. Также стоит отметить, что нейросеть Sora Images, которая уже доступна в Telegram, прекрасно поддерживает практически любые языки, позволяя легко добавлять текст на изображения и точно воспринимать пожелания пользователей. Одной из наиболее полезных функций является понятное и быстрое реагирование на простые запросы: программа способна заметно улучшить качество снимков, оперативно изменить визуальный стиль изображения или превратить старые чёрно-белые фотографии в цветную картинку.

Нейросеть Sora Images для генерации и обработки изображений теперь доступна в Telegram
Давайте разберёмся подробнее с самого начала. Нейросеть Sora в задуманном виде изначально создавалась специалистами OpenAI для автоматической генерации видео на основе текстовых описаний и заданных изображений-референсов. Более развёрнуто мы уже освещали это в отдельной публикации. Позднее разработчики приняли решение расширить функционал, позволив нейромодели создавать также статичные изображения.
Стоит отметить, что в своей первоначальной роли генератора видео Sora выступила не идеально: если по текстовым подсказкам нейросеть создавала качественные ролики без особых затруднений, то с работой по референсным изображениям явно возникали сложности. Здесь технология пока не смогла полностью оправдать возлагавшиеся надежды и требования.
Однако при создании статичных картинок мы столкнулись с совершенно иной ситуацией. В этом сценарии использования Sora проявила себя наилучшим образом: результаты приятно удивили и полностью оправдали ожидания.
Нейросеть Sora: чем полезна и что умеет?
Современная нейросеть Sora впечатляет своей способностью точно распознавать и создавать изображения по обычным человеческим запросам. Причём неважно, на каком языке вы формулируете своё пожелание — русский, английский или другой язык будут восприняты одинаково точно. Нужно сделать комикс-картинку про волка, который предлагает зайцу сыграть в «выживание»? Просто напишите соответствующий запрос — и вы получите готовый рисунок в комикс-стиле без особых усилий. Текст на изображении будет аккуратным, грамотным и эстетичным. Так что теперь художники больше не обязательны — достаточно вашего воображения и нескольких оригинальных идей.
Ещё одна полезная функция Sora — распознавание и детальная интерпретация элементов изображений, которые вы загружаете в качестве примеров или референсов. Нейросеть позволяет использовать до десяти изображений одновременно для создания нужной вам композиции. К примеру, если вы хотите изменить внешний вид вашего персонажа, достаточно загрузить его первоначальный снимок, добавить фото желаемой одежды и аксессуаров, а затем описать локацию словами. «Надень на человека футболку, сверху пиджак и шляпу, и помести его на солнечный пляж» — и нейросеть легко реализует вашу идею. Причём итоговое изображение будет выглядеть правдоподобно и гармонично, с максимально естественным вписыванием персонажа в новый фон.
Кроме того, Sora обладает высокой точностью в обработке человеческих портретов. Частые ошибки и нелепые искажения, характерные для многих других инструментов, практически исключены. Нейросеть успешно сохраняет индивидуальные черты лица и фигуру человека. Более того, вы можете смело экспериментировать со своей внешностью: загрузив собственную фотографию, за считаные минуты вы сможете увидеть себя в образе героя аниме или даже злодея-бандита.
Наконец, важным преимуществом Sora остается простота общения с ней. В отличие от популярных нейросетей вроде Midjourney или Stable Diffusion, здесь не нужно осваивать сложные команды или специфическую терминологию. Просто объясните нейросети, что именно вам требуется, так же легко, словно вы разговариваете с другом. Чем яснее и естественнее слова, тем лучше и точнее будет результат.
Чем плоха нейросеть Sora для генерации изображений: разбор основных недостатков
Если оценивать картинки, создаваемые с помощью нейросети Sora, с художественной точки зрения, ей пока далеко до своего основного конкурента — популярного сервиса Midjourney. Однако, если ставить в приоритет реализм и естественность фотографий, здесь она показывает себя гораздо увереннее.
Изображения, созданные при помощи Sora, обладают специфическими чертами, которые делают их заметно отличающимися от аналогичных работ других известных нейросетей. Самая очевидная проблема связана с цветовой палитрой: генерации нередко получаются приглушёнными, тусклыми и маловыразительными. Тем, кто ставит перед нейросетью задачу получать картинки более яркой и живой окраски, стоит обязательно вводить специальные уточнения в свои запросы. Например, вы можете указывать такие формулировки, как «яркие цвета», «насыщенная палитра» или «красочное изображение».
Ещё один недостаток Sora — отсутствие встроенных инструментов для увеличения разрешения готовой картинки (так называемый «апскейл»). Впрочем, эта недоработка легко исправляется с помощью сторонних сервисов либо специализированных нейросетевых решений.
И, наконец, цена вопроса. Подписку на Sora трудно назвать доступной: в случае активного и интенсивного использования нейросети вам придется выбирать тариф стоимостью около 200 долларов, так как именно этот пакет предоставляет возможность одновременно генерировать картинки в нескольких потоках. Тем же, кто хочет сэкономить, можно посоветовать использовать возможности нейросети через Telegram-бот @yes_ai_bot, где нет необходимости подписываться, а оплачиваются только сами генерации.
Как эффективно использовать нейросеть Sora Images: простые советы и рекомендации
Знали ли вы, что нейросеть Sora позволяет виртуально преображать внешний вид человека за считанные минуты? Фактически, эта технология становится настоящей цифровой примерочной, где любую одежду можно «надеть» онлайн, не выходя из дома. Всё, что потребуется – это исходная фотография человека и отдельные изображения тех вещей, которые вы хотите примерить. Затем просто укажите в текстовом запросе нейросети, что выбранную одежду необходимо "надеть" на фигуру человека с исходного фото.
Разумеется, пока технология совершенствуется, некоторые мелкие элементы, такие как логотипы или мелкие рисунки, могут отображаться неточно или пропадать полностью. Несмотря на эти нюансы, итоговый результат выглядит правдоподобно и весьма перспективно.


Преобразовать фото в необычный, оригинальный стиль теперь может абсолютно каждый, и для этого вовсе не обязательно обладать художественными навыками. Всё, что нужно сделать — выбрать изображение людей, животных или любых интересующих вас предметов, а затем отправить его в Сору с небольшим пояснением. Например, вы можете указать: «Изобрази людей в духе полотен Рембрандта» или «Изобрази собаку словно детский рисунок». Такой доступный приём позволит иначе взглянуть даже на уже известные шедевры, например, знаменитую «Мону Лизу», открывая привычные образы совершенно заново.

Нейросеть «Сора» эффективно интерпретирует поступающие команды, воспринимая текстовые комментарии к изображениям как прямые инструкции для выполнения задач. К примеру, она может вернуть старой фотографии былую резкость или превратить монохромное фото в яркую цветную картинку. Достаточно просто указать команду в виде: «Восстанови снимок и раскрась его». Более того, одна сформулированная просьба может содержать сразу несколько подобных запросов, и нейросеть успешно справится с ними одновременно.


Создаем изображения через Sora Images без необходимости регистрироваться: краткая инструкция
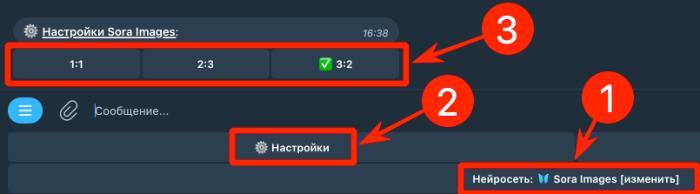
Для начала перейдите по указанной ссылке и активируйте специализированного Telegram-бота @yes_ai_bot
Затем зайдите в меню настроек и обозначьте нужный формат создаваемого изображения — на выбор доступны наиболее популярные соотношения сторон: квадратное (1:1), вертикальное (2:3) или горизонтальное (3:2).
Хотите создать изображение по собственному замыслу? Просто отправьте боту подробное текстовое описание задуманного вами сюжета.
Если же у вас уже есть изображения, которые могут послужить основой нового рисунка, загрузите их в количестве от 1 до 10 штук в одном сообщении. Обязательно добавьте текстовое пояснение — оно будет служить запросом для обработки. После этого дополнительно опишите желаемый результат и нажмите на кнопку «🎡 Смешать изображения».
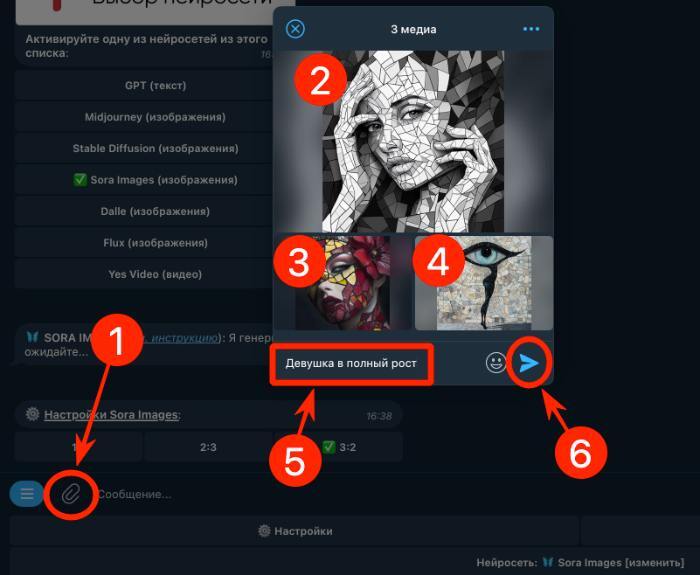
Подождите пару минут, пока бот подготовит изображения. Генерируется всегда по четыре варианта картинки.
Готовые работы можно сразу загрузить в высоком качестве. Более того, изображения можно дополнительно улучшить, воспользовавшись инструментом перерисовки (INPAINT). Созданные с помощью сервиса Yes AI картинки легко превратить в анимации при помощи других нейросетевых сервисов — таких, например, как Kling AI, Luma или Pika.
Если вы довольны результатом и хотите поделиться созданной работой, можете выложить её на нашем форуме, воспользовавшись выделенной для этого функциональной кнопкой публикации. За активность такого рода сервис Yes AI предоставляет своим пользователям специальные ⭐ баллы. Эти поощрения могут пригодиться вам при создании контента в других нейросетевых инструментах этого проекта.
Пользователям сервиса Yes Ai Bot доступны широкие возможности нейросети Sora Images, которые позволяют быстро создавать яркие и качественные изображения.
Вы можете выбирать подходящее соотношение сторон для своих картинок. Доступны форматы 1:1 (квадрат), 2:3 (вертикальный формат) и 3:2 (горизонтальный формат).
Кроме того, можно эффектно стилизовать изображения, используя готовые шаблоны из встроенной коллекции. Уникальной особенностью является опция комбинирования нескольких стилей (до трех одновременно), например, акварель, реализм или аниме, что позволит вам получить по-настоящему оригинальные и выразительные работы.
Для удобства дальнейшей работы имеется возможность экспортировать конечное изображение прямо в SVG-формат.
А самое интересное: вы можете «оживить» готовое изображение, загрузив его в нейросети-аниматоры, среди которых доступны сервисы Sora Video, Kling Ai, Pika или Luma.
Показать полностью
8
NotebookLM
Делаем подробнейшие конспекты и подкасты из ЛЮБОГО файла — NotebookLM мощно обновился и теперь может помочь в изучении и анализе ЛЮБОЙ текстовой инфы.
• Знает более 50 языков, и в том числе РУССКИЙ.
• Работает с ЛЮБЫМИ типами данных — PDF, статьями, сайтами, видео и даже с простыми ссылками.
• Перескажет материал, выделит главное, создаст презентацию и даже ПОДКАСТ, если вам лень читать. ИИ-агенты просто будут болтать друг с другом и объяснят всевозможные темы.
Показать полностью