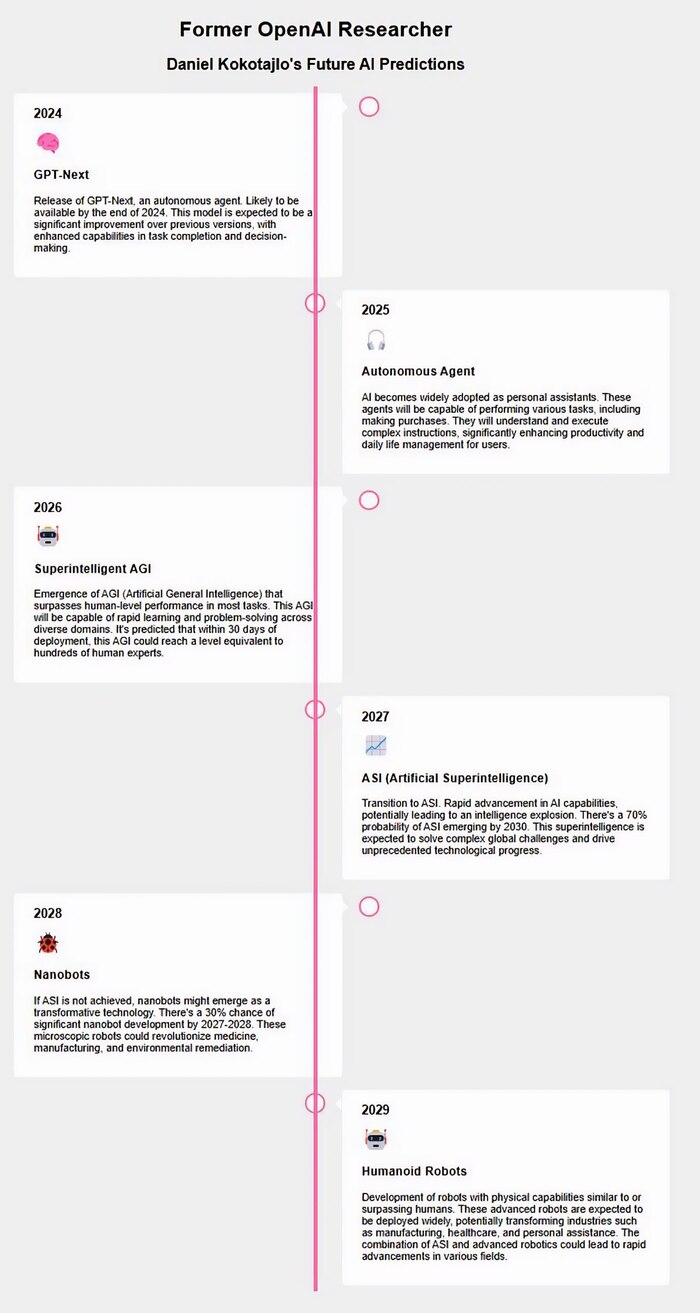
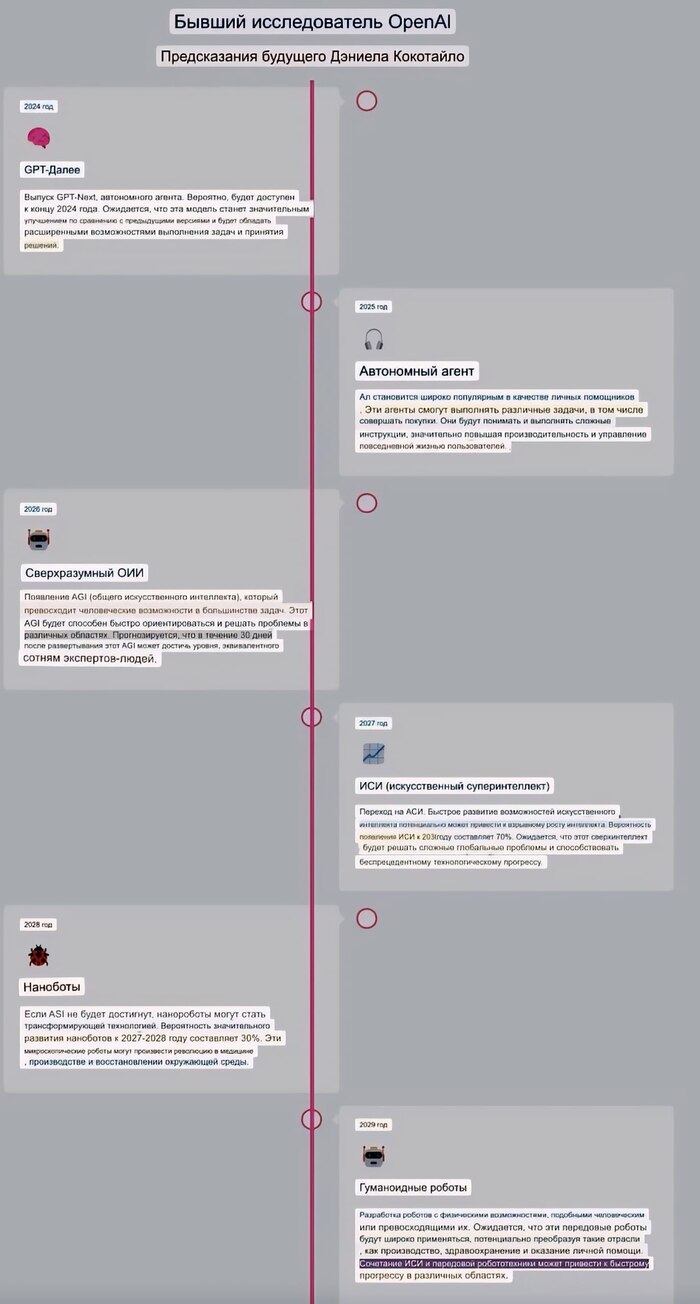
## График Профессионального Развития Аналитика Данных
Цель: Стать Senior Data Analyst, способным самостоятельно решать задачи по сбору, обработке, анализу данных и визуализации результатов, эффективно взаимодействуя с коллегами и руководством.
Инструменты: Google Таблицы, Yandex Datalens, SQL, Python (pandas, numpy, matplotlib, seaborn), Power BI/Tableau (опционально).
### Junior Data Analyst
Навыки:
* Базовые:
* Знание основ статистики и теории вероятностей.
* Понимание принципов работы с данными: сбор, очистка, трансформация.
* Знакомство с Google Таблицами: фильтрация, сортировка, формулы.
* Базовые навыки работы с SQL: простые запросы (SELECT, WHERE, ORDER BY).
* Умение ясно и четко формулировать свои мысли, презентовать результаты анализа.
* Дополнительные:
* Знакомство с языком программирования Python.
* Знакомство с библиотеками Python для анализа данных: pandas, numpy.
* Опыт работы с Yandex Datalens: создание простых отчетов и дашбордов.
* Понимание принципов работы с системами контроля версий (Git).
Задачи:
* Сбор данных из различных источников (открытые источники, внутренние системы).
* Очистка и предварительная обработка данных.
* Создание простых отчетов и визуализаций в Google Таблицах.
* Помощь старшим коллегам в выполнении более сложных задач.
### Middle Data Analyst
Навыки:
* Уверенное владение:
* SQL: сложные запросы (JOIN, подзапросы, оконные функции).
* Python: работа с библиотеками pandas, numpy, matplotlib, seaborn.
* Методами очистки и предобработки данных.
* Создание информативных визуализаций данных.
* Yandex Datalens: создание интерактивных дашбордов.
* Принципами A/B тестирования и интерпретации результатов.
* Дополнительные:
* Знакомство с методами машинного обучения.
* Опыт работы с инструментами Big Data (Hadoop, Spark).
* Знание английского языка на уровне чтения технической документации.
Задачи:
* Самостоятельная разработка и валидация аналитических гипотез.
* Построение моделей для прогнозирования и сегментации.
* Создание комплексных аналитических отчетов с выводами и рекомендациями.
* Разработка и поддержка ETL-процессов (Extract, Transform, Load).
### Senior Data Analyst
Навыки:
* Экспертное владение:
* SQL, Python, инструментами визуализации данных.
* Методами машинного обучения и их применения в бизнес-задачах.
* Статистическими методами анализа данных.
* Опытом работы с большими объемами данных.
* Английский язык на уровне свободного общения.
* Дополнительные:
* Знакомство с облачными платформами (AWS, GCP).
* Опыт работы с инструментами Data Engineering.
* Умение руководить командой аналитиков.
Задачи:
* Разработка и внедрение data-driven подхода в компании.
* Построение комплексных моделей машинного обучения.
* Разработка стратегии развития аналитики в компании.
* Менторство и обучение junior и middle аналитиков.
* Взаимодействие с руководством компании по вопросам, связанным с данными.
Важно помнить, что данный график является примерным. Конкретные требования к навыкам и задачам могут различаться в зависимости от компании и индустрии.
## График Профессионального Развития Аналитика Данных (Детализированный)
**Цель:** Стать Senior Data Analyst, способным самостоятельно решать задачи по сбору, обработке, анализу данных и визуализации результатов, эффективно взаимодействуя с коллегами и руководством.
**Инструменты:** Google Таблицы, Yandex Datalens, SQL, Python (pandas, numpy, matplotlib, seaborn), Power BI/Tableau (опционально).
### Junior Data Analyst
**Навыки:**
* **Базовые:**
* **Основы статистики и теории вероятностей:** Понимание основных статистических показателей (среднее, медиана, мода, дисперсия), распределений (нормальное, биномиальное), гипотез и p-value.
* **Принципы работы с данными (сбор, очистка, трансформация):** Знание различных типов данных, форматов (CSV, JSON), источников данных. Умение чистить данные от пропусков, дубликатов, выбросов. Приведение данных к нужному формату для анализа.
* **Google Таблицы:** Уверенное использование фильтров, сортировок, формул (математические, текстовые, логические) для анализа и обработки данных.
* **Базовый SQL (SELECT, WHERE, ORDER BY):** Умение писать запросы для выборки нужных данных из базы данных с заданными условиями и сортировкой.
* **Презентация результатов:** Умение структурировано излагать информацию, создавать понятные графики и таблицы, доносить выводы до аудитории с разным уровнем технической подготовки.
* **Дополнительные:**
* **Знакомство с Python:** Базовое понимание синтаксиса языка, типов данных, структур данных.
* **Библиотеки Python (pandas, numpy):** Знакомство с основными функциями библиотек для работы с данными - чтение файлов, манипуляция данными, базовая статистика.
* **Yandex Datalens:** Понимание интерфейса, создание простых отчетов на основе готовых данных, подключение к различным источникам данных.
* **Системы контроля версий (Git):** Базовое понимание принципов работы Git для контроля версий кода и данных.
**Задачи:**
* **Сбор данных:** Сбор данных из открытых источников (веб-сайты, API), внутренних CRM-систем, Excel-файлов.
* **Очистка и предобработка данных:** Поиск и обработка пропусков, дубликатов, выбросов в данных. Приведение данных к единому формату.
* **Создание простых отчетов в Google Таблицах:** Создание отчетов с использованием формул, фильтров, сортировок. Визуализация данных с помощью графиков и диаграмм.
* **Помощь старшим коллегам:** Подготовка данных для анализа, проверка качества данных, написание простых SQL-запросов.
### Middle Data Analyst
**Навыки:**
* **Уверенное владение:**
* **SQL (JOIN, подзапросы, оконные функции):** Умение писать сложные SQL-запросы для объединения данных из разных таблиц, фильтрации данных по сложным условиям, выполнения вычислений по группам данных.
* **Python (pandas, numpy, matplotlib, seaborn):** Уверенное использование библиотек для обработки данных, проведения разведочного анализа данных, создания статистических моделей, визуализации данных.
* **Методы очистки и предобработки данных:** Применение различных методов обработки пропусков, выбросов, аномалий. Знание особенностей предобработки данных для различных типов моделей.
* **Создание информативных визуализаций:** Умение выбирать правильные типы графиков и диаграмм для визуализации данных, создавать понятные и информативные дашборды.
* **Yandex Datalens:** Создание интерактивных дашбордов с использованием различных виджетов, подключение к различным источникам данных, настройка обновлений данных.
* **A/B тестирование:** Понимание методологии A/B тестирования, умение формулировать гипотезы, проводить тесты, анализировать результаты и делать выводы.
* **Дополнительные:**
* **Методы машинного обучения:** Знакомство с основными алгоритмами машинного обучения (линейная регрессия, логистическая регрессия, деревья решений).
* **Инструменты Big Data (Hadoop, Spark):** Базовое понимание принципов работы с большими данными.
* **Английский язык:** Чтение технической документации, статей по анализу данных.
**Задачи:**
* **Разработка и валидация аналитических гипотез:** Формулировка гипотез на основе бизнес-задач, сбор данных, проведение анализа, проверка статистической значимости, формулировка выводов.
* **Построение моделей для прогнозирования и сегментации:** Разработка моделей машинного обучения для прогнозирования спроса, оттока клиентов, сегментации клиентов.
* **Создание комплексных аналитических отчетов:** Подготовка аналитических отчетов с описанием методологии, визуализацией данных, выводами и рекомендациями.
* **Разработка и поддержка ETL-процессов:** Разработка процессов для извлечения данных из различных источников, их трансформации и загрузки в хранилище данных.
### Senior Data Analyst
**Навыки:**
* **Экспертное владение:**
* **SQL, Python, инструменты визуализации:** Свободное владение инструментами для работы с данными, выбор оптимальных инструментов для решения конкретных задач.
* **Машинное обучение:** Глубокое понимание различных алгоритмов машинного обучения, умение выбирать оптимальные алгоритмы для решения бизнес-задач.
* **Статистика:** Уверенное владение статистическими методами анализа данных, умение применять статистические тесты для проверки гипотез.
* **Работа с большими данными:** Опыт работы с инструментами Big Data, умение обрабатывать большие объемы данных.
* **Английский язык:** Свободное общение на английском языке, написание технической документации, участие в международных конференциях.
* **Дополнительные:**
* **Облачные платформы (AWS, GCP):** Знание принципов работы облачных платформ, умение разворачивать сервисы для работы с данными.
* **Data Engineering:** Понимание принципов построения data pipelines, знакомство с инструментами для автоматизации процессов обработки данных.
* **Управление командой:** Умение ставить задачи, делегировать, мотивировать команду аналитиков.
**Задачи:**
* **Data-driven подход:** Внедрение data-driven подхода в компании, разработка data-driven культуры.
* **Комплексные модели:** Построение сложных моделей машинного обучения, ансамблей моделей, нейронных сетей.
* **Стратегия развития аналитики:** Разработка стратегии развития аналитики в компании, выбор инструментов и технологий, определение ключевых метрик.
* **Менторство:** Обучение junior и middle аналитиков, передача опыта.
* **Взаимодействие с руководством:** Подготовка презентаций для руководства компании, объяснение результатов анализа данных, формулировка рекомендаций.
3. ## Инструкция по самообучению Junior Data Analyst:
Этап 1: Основы и работа с данными (1-2 месяца)
1. Статистика и теория вероятностей:
- Пройдите онлайн-курсы: "Основы статистики" на Khan Academy, Coursera, Stepik.
- Изучите книгу: "Голая статистика" Чарльз Уилан.
2. Принципы работы с данными:
- Онлайн-курсы: "Data Literacy" на DataCamp, "Data Analysis with Python" на freeCodeCamp.
- Книга: "Data Science for Business" Фостер Провост, Том Фосетт.
3. Google Таблицы:
- Официальные руководства Google.
- Практика: найдите открытый датасет (например, на Kaggle) и попробуйте выполнить базовые операции по очистке, фильтрации и анализу данных.
4. Базовый SQL (SELECT, WHERE, ORDER BY):
- Онлайн-курсы: "Intro to SQL" на Khan Academy, "SQL Fundamentals" на Datacamp.
- Практика: создайте тестовую базу данных (SQLite) и практикуйте написание простых запросов.
5. Презентация результатов:
- Изучите принципы создания эффективных презентаций: структурирование информации, визуализация данных.
- Практика: подготовьте презентацию на основе анализа данных из открытого источника.
Этап 2: Знакомство с инструментами и задачами (2-3 месяца)
1. Знакомство с Python:
- Пройдите онлайн-курсы: "Python for Everybody" на Coursera, "Learn Python 3" на Codecademy.
- Книга: "Python Crash Course" Эрик Мэтьюз.
2. Библиотеки Python (pandas, numpy):
- Официальная документация библиотек.
- Практика: работайте с датасетами, применяя функции pandas и numpy для обработки и анализа данных.
3. Yandex Datalens (опционально):
- Официальные руководства Yandex Datalens.
- Создайте аккаунт и попробуйте подключиться к разным источникам данных, построить простые отчеты и дашборды.
4. Системы контроля версий (Git):
- Онлайн-курсы: "Git и GitHub: Базовый курс" на Stepik, "Git Essentials" на Udemy.
- Создайте репозиторий на GitHub и практикуйте базовые операции: создание веток, коммиты, pull requests.
Этап 3: Практика и поиск первых проектов (1-2 месяца)
1. Поиск и решение задач:
- Участвуйте в соревнованиях на Kaggle, решайте задачи на HackerRank, LeetCode.
- Найдите открытые данные и проведите самостоятельный анализ, построив дашборд с результатами.
2. Портфолио:
- Создайте портфолио на GitHub, где будут храниться ваши проекты, код и презентации.
3. Нетворкинг:
- Посещайте митапы и конференции по анализу данных.
- Общайтесь с экспертами в области data science, задавайте вопросы.
Важные моменты:
* Постоянная практика: решайте задачи, работайте с реальными данными, автоматизируйте рутинные процессы.
* Английский язык: читайте статьи, смотрите видеолекции на английском языке.
* Не бойтесь задавать вопросы: ищите ответы на форумах (Stack Overflow), в сообществах, у менторов.
Следуя этой инструкции, вы получите базовые навыки и знания Junior Data Analyst и сможете начать свою карьеру в анализе данных. Помните, что самое главное – это постоянное развитие, изучение новых инструментов и технологий, а также работа над реальными проектами.
4. ## Инструкция по самообучению Junior Data Analyst (с примерным количеством часов):
Этап 1: Основы и работа с данными (40-80 часов)
1. Статистика и теория вероятностей (20-40 часов):
- Онлайн-курсы: 10-20 часов
- Чтение книги: 10-20 часов
2. Принципы работы с данными (10-20 часов):
- Онлайн-курсы: 5-10 часов
- Чтение книги: 5-10 часов
3. Google Таблицы (10-20 часов):
- Изучение: 2-4 часа
- Практика: 8-16 часов
4. Базовый SQL (SELECT, WHERE, ORDER BY) (20-40 часов):
- Онлайн-курсы: 10-20 часов
- Практика: 10-20 часов
5. Презентация результатов (10-20 часов):
- Изучение: 5-10 часов
- Практика: 5-10 часов
Этап 2: Знакомство с инструментами и задачами (60-90 часов)
1. Знакомство с Python (30-40 часов):
- Онлайн-курсы: 20-30 часов
- Чтение книги: 10-20 часов
2. Библиотеки Python (pandas, numpy) (20-30 часов):
- Изучение документации: 5-10 часов
- Практика: 15-20 часов
3. Yandex Datalens (опционально) (10-20 часов):
- Изучение: 2-4 часа
- Практика: 8-16 часов
4. Системы контроля версий (Git) (10-20 часов):
- Онлайн-курсы: 5-10 часов
- Практика: 5-10 часов
Этап 3: Практика и поиск первых проектов (40-80 часов +)
1. Поиск и решение задач (20-40 часов +):
- Соревнования, задачи: 10-20 часов +
- Самостоятельные проекты: 10-20 часов +
2. Портфолио (10-20 часов):
- Оформление проектов, написание описаний.
3. Нетворкинг (10-20 часов +):
- Посещение мероприятий, общение с экспертами.
Важно:
* Это примерные временные рамки. Все зависит от вашего начального уровня, скорости усвоения материала, усердия и выбранных ресурсов.
* Уделите особое внимание практике – это ключевой элемент в освоении профессии Data Analyst.
* Не расстраивайтесь, если что-то будет получаться не сразу. Главное – постоянство и стремление к развитию.