


Трамп ввёл 25% пошлину на импорт CSV!1

Президент Трамп хочет нацелиться на немецких поставщиков программного обеспечения для электронной коммерции.
Президент Трамп хочет нацелиться на немецких поставщиков программного обеспечения для электронной коммерции.
Как быстро удалить дублирующиеся строки в CSV, Excel и таблицах Markdown?
Если вы используете CSV, Excel или Markdown таблицы, вы можете столкнуться с дублирующимися строками. Это может произойти, если вы вручную ввели одинаковые данные или импортировали дубликаты из других источников. Какова бы ни была причина, удаление дублирующихся строк — важная часть очистки данных. В этой статье мы расскажем о нескольких способах быстрого удаления дублирующих строк из CSV, Excel и Markdown таблиц.
1. Онлайн-инструмент для таблиц (рекомендуется)
Вы можете использовать онлайн-инструмент под названием "TableConvert" для удаления дублирующих строк. С помощью этого инструмента вы легко сможете проверить и удалить дублирующиеся строки в ваших CSV, Excel и Markdown таблицах. Просто откройте браузер и перейдите по ссылке https://tableconvert.com/excel-to-excel, вставьте или загрузите ваши данные и нажмите кнопку "Deduplicate" в редакторе таблиц. Это быстро и легко. Посмотрите на изображение ниже:
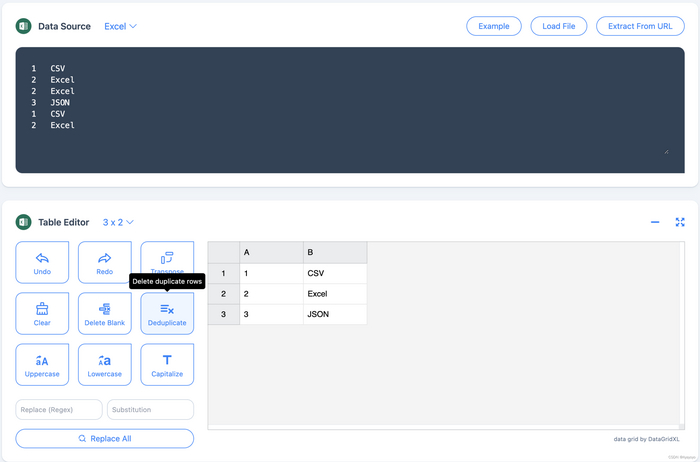
Удаление дублирующихся строк из таблиц CSV, Excel, Markdown
2. Удаление дублирующихся строк в Excel
Удаление дублирующихся строк в Excel очень просто. Сначала откройте файл Excel и выберите столбец, в котором хотите проверить дублирующиеся строки. Затем нажмите на меню "Данные" и выберите "Удалить дубликаты". Excel покажет диалоговое окно, в котором вам нужно выбрать столбцы для удаления дубликатов. Нажмите "ОК", и Excel удалит все дублирующиеся строки.
3. На Linux или Mac вы можете использовать команды uniq и sort для удаления дубликатов.
/tmp ❯ cat test.txt
test 1
test 2
test 3
test 3
test 4
test 1
/tmp ❯ cat test.txt | uniq
test 1
test 2
test 3
test 4
test 1
/tmp ❯ cat test.txt | sort | uniq
test 1
test 2
test 3
test 4
/tmp ❯ cat test.txt | sort -u
test 1
test 2
test 3
test 4
Кто-то наверняка хотел увидеть чем пригодились нейросети и какого уровня код может делать..
Но перед этим скажу, что к сожалению одной сетью Сodestral восхваляемой в предыдущем посте не обошлось.. В итоге использовал по некоторым мелким вопросам ( для уточнений скорей)- Copilot, также https://chat.deepseek.com/coder ( выпустили на днях- тоже довольно хороша для программирования). И даже немного поюзал вышедший чуть ли не вчера ( тоже улучшенный- но не специально для кода)- Claude 3.5 Sonnet, модель которая превосходит GPT-4 почти на всех тестах ( в том числе в программировании)
Claude 3.5 Sonnet уже доступна бесплатно для всех пользователей. ( я регился через sms-activate) за 10р ( конечно нужен VPN)
по факту же- основной код из https://chat.deepseek.com/coder... почему так говорю- потому что уже сам не помню- дня три долбил разные сети)) наверное с 15й попытки сделал рабочий вариант. Штука в том, что пару раз наблюдал за тем, как разные сети начинали глючить..то код не допишут, то еще чего. Я в программировании почти ноль ( на php знаю 2-3 команды и то со словарём..). Хотя кое-какие задачи для себя решаю, пишу технические задания.. И вот ниже тех.задание которое я запихивал в нейросеть- нужное для моих целей.
Ниже также будет опубликован рабочий код. Так что и программисты и любители могут оценить..поругать..или поудивляться что может нейросеть..или оценить свои перспективы.
Итак- вот такое было тех.задание:
Напиши программу на php, которая обрабатывает файл prices.csv, при запуске проверяет существование файлов ostatki.txt и pusto.txt, если эти файлы не существуют, создаёт их. Если файлы существуют, очищает их содержимое. Также если не существует, то создается база sqlite ostatki.db с с двумя таблицами: таблица ostatki с полями artikul ( число), tovar (текстовое), qty ( числовое) и таблица pusto с полями artikul (число), tovar (числовое), qty (текстовое) . Также добавь вывод ошибок php в начале файла.
Если скрипт запускается первый раз ( это можно проверить по отсутствию базы ostatki.db)- если файла базы нет ostatki.db, она создается как написано выше и запуск считается первым, в этом случае идет обработка файла prices.csv по таким правилам:
файл prices.csv содержит разделители ; ( точка с запятой)
обработка файла prices.csv начинается со второй строки.
2ая колонка в prices.csv это переменная artikul (артикул товара), 3я колонка это name (название товара), 14ая колонка это qty ( количество), считываем все данные из prices.csv построчно, для ускорения процесса используем массив, записываем данные в базу данных ostatki.db в таблицу ostatki по соответствующим названиям полей и переменных ( artikul в artikul и так далее, при условии что в 14й колонке содержится любое число, если в 14й колонке пусто, тогда данные artikul, tovar записываются в таблицу pusto, а в поле qty этой таблицы pusto записывается текстовое значение zero.
Происходит запись лог файлов ostatki.txt и pusto.txt по таким правилам:
в файл ostatki.txt идет построчная запись товаров с нулевыми остатками, то есть из таблицы ostatki берется товар где qty=0 и в этом случае формируется запись: Товар artikul name закончился, проверьте остатки! И так до тех пор, пока будут проверены все нулевые значения таблицы ostatki в поле qty в базе ostatki.db
в файл pusto.txt построчно записываются значения из таблицы pusto в таком формате Товар artikul name не был заведён по каким-то причинам. После первого запуска идет отправка данных с помощью функции
maillogfile, ее описание в конце текста. И после запуска этой функции maillogfile идет остановка программы, она считается завершенной.
.
При повторном запуске программы ( повторным считается запуск если существует база ostatki.db)
идет проверка на изменение данных в базе данных при сравнении с файлом prices.csv по таким правилам ( начиная со второй строки):
Если в файле prices.csv где 2ая колонка в prices.csv это переменная artikul (артикул товара), 3я колонка это name (название товара), 14ая колонка это qty ( количество), считываем все данные из prices.csv построчно ( ускоряем процесс с помощью массива), если определяется что qty=0 нужно проверить совпадение в базе данных ostatki.db в таблице ostatki по артикулу ( artikul), если в таблице также в qty находится 0, то ничего не делаем, и запись в лог файл ostatki.txt не производим. Если в таблице prices.csv qty=0 ( это 14ая колонка), а в базе данных ostatki.db в таблице ostatki значение qty больше нуля, тогда делаем запись в лог файл ostatki.txt в формате Товар artikul name закончился, проверьте остатки!
Если при сравнении prices.csv и таблицы ostatki в базе данных ostatki.db при совпадении artikul число qty отличается от нуля ( не пустая строка и не отсутствие значения), и qty в prices.csv отличается от qty в таблице ostatki то делаем перезапись значения qty в базе данных.. Если artikul в prices.csv не находится в ostatki.db в таблице ostatki, при втором и последующих запусках программы, значит данного товара еще не было и создается новая строка с данными artikul, tovar, qty и также идёт запись в ostatki.txt такого вида: Добавлен товар artikul name с остатком qty.
Также проверяем проходя 2, 3, 14 колонку файла prices.csv и таблицу pusto в базе данных, если artikul содержит qty от 0 и выше, и при этом данный artikul содержится в таблице pusto, то удаляем эту строку из базы данных из таблицы pusto.
Также идёт проверка таблицы pusto, если в файле prices.csv есть пустые значения в qty ( 14ая колонка), то есть это не 0 и не число, и такое же точно значение уже есть в таблице pusto по значению artikul, и в qty находится zero, то в файл pusto.txt ничего не пишем и проверяем дальше. В итоге после всех проверок
Запускается функция для отправки maillogfile, ее описание ниже.
Функция maillogfile содержит отправку по заданному адресу с другого заданного адреса с использованием библиотеки Phpmailer ( она находится в папке PHPMailer/src/, адрес куда отправлять берет из файла email.txt, откуда отправлять и другие настройки берет из файла email.cfg в формате json, пример содержимого email.cfg с соответствующими настройками, чтобы ты знал как создать функцию maillogfile с использованием данных файлов в виде настроек приведены ниже в кавычках {}
{
"smtp_host": "smtp.mail.ru",
"smtp_auth": true,
"smtp_username": "de--@Mail.ru",
"smtp_password": "H--—9H",
"smtp_secure": "ssl",
"smtp_port": 465
“Name”: ”Dimitriy”
}
Здесь Name это имя отправителя, все остальные данные совпадают с переменными..
Эта функция при запуске отправляет во вложении файлы ostatki.txt и pusto.txt, также тексты добавляются из файлов в тело письма, , при условии что в данных файлах содержится текст, если файлы пустые, не содержат текст, то письмо не отправляется.
Также в данной функции должна проводиться проверка на отправку почты, если по причине технической ошибки отправка не произошла выводится текст на экран: Ошибка, почта не была отправлена. В случае успеха- на экран выводится: Почта с нулевыми остатками отправлена.
Если лог файлы ostatki.txt и pusto.txt пустые- выводится - Ничего не изменилось, поэтому письмо не отправлено. Также проследи чтобы не было проблем с кодировкой при отправке писем, чтобы заголовки и сам текст был в одной кодировке. Также учти чтобы при чтении файла prices.csv не было проблем с кодировкой ( текст внутри этого файла prices.csv в кодировке windows-1251), следует при записи в базу данных и обработке делать преобразование в utf-8 текстовых данных.
В коде должна быть определена только одна функция maillogfile, всё остальное описанное в задании нужно делать строго по моему описанию выше, не создавая для этого специальных функций.
Также проверь время выполнения файла и выведи в конце подробную информацию- сколько времени было выполнение файла.
А вот такой вышел код: ( реально рабочий- через Cron на хостинге запускаю каждые полчаса- но как говорится и в этом есть нюансы)- но в итоге работает.
<?php
ini_set('display_errors', 1);
ini_set('display_startup_errors', 1);
error_reporting(E_ALL);
function maillogfile($to, $from, $fromName, $smtpSettings) {
require 'PHPMailer/src/PHPMailer.php';
require 'PHPMailer/src/SMTP.php';
require 'PHPMailer/src/Exception.php';
$mail = new PHPMailer\PHPMailer\PHPMailer();
$mail->isSMTP();
$mail->Host = $smtpSettings['smtp_host'];
$mail->SMTPAuth = $smtpSettings['smtp_auth'];
$mail->Username = $smtpSettings['smtp_username'];
$mail->Password = $smtpSettings['smtp_password'];
$mail->SMTPSecure = $smtpSettings['smtp_secure'];
$mail->Port = $smtpSettings['smtp_port'];
$mail->CharSet = 'UTF-8';
$mail->setFrom($from, $fromName);
$mail->addAddress($to);
$mail->Subject = 'Остатки товаров';
$ostatkiContent = file_get_contents('ostatki.txt');
$pustoContent = file_get_contents('pusto.txt');
if (empty($ostatkiContent) && empty($pustoContent)) {
echo "Ничего не изменилось, поэтому письмо не отправлено.";
return;
}
if (!empty($ostatkiContent)) {
$mail->addAttachment('ostatki.txt');
$mail->Body .= $ostatkiContent;
}
if (!empty($pustoContent)) {
$mail->addAttachment('pusto.txt');
$mail->Body .= $pustoContent;
}
if (!$mail->send()) {
echo 'Ошибка, почта не была отправлена.';
echo 'Mailer Error: ' . $mail->ErrorInfo;
} else {
echo 'Почта с нулевыми остатками отправлена.';
}
}
$startTime = microtime(true);
$dbFile = 'ostatki.db';
$csvFile = 'prices.csv';
$ostatkiFile = 'ostatki.txt';
$pustoFile = 'pusto.txt';
$emailFile = 'email.txt';
$emailConfigFile = 'email.cfg';
if (!file_exists($ostatkiFile)) {
file_put_contents($ostatkiFile, '');
} else {
file_put_contents($ostatkiFile, '');
}
if (!file_exists($pustoFile)) {
file_put_contents($pustoFile, '');
} else {
file_put_contents($pustoFile, '');
}
$ostatkiBuffer = '';
$pustoBuffer = '';
if (!file_exists($dbFile)) {
$db = new SQLite3($dbFile);
$db->exec("CREATE TABLE ostatki (artikul INTEGER, tovar TEXT, qty INTEGER)");
$db->exec("CREATE TABLE pusto (artikul INTEGER, tovar TEXT, qty TEXT)");
$db->exec("CREATE INDEX idx_ostatki_artikul ON ostatki (artikul)");
$db->exec("CREATE INDEX idx_pusto_artikul ON pusto (artikul)");
$insertOstatki = $db->prepare("INSERT INTO ostatki (artikul, tovar, qty) VALUES (:artikul, :tovar, :qty)");
$insertPusto = $db->prepare("INSERT INTO pusto (artikul, tovar, qty) VALUES (:artikul, :tovar, 'zero')");
$csvData = [];
if (($handle = fopen($csvFile, "r")) !== FALSE) {
fgetcsv($handle, 0, ";"); // Skip header
while (($data = fgetcsv($handle, 0, ";")) !== FALSE) {
$csvData[] = $data;
}
fclose($handle);
}
$db->exec("BEGIN TRANSACTION");
foreach ($csvData as $data) {
$artikul = $data[1];
$tovar = mb_convert_encoding($data[2], 'UTF-8', 'Windows-1251');
$qty = $data[13];
if (is_numeric($qty)) {
$insertOstatki->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$insertOstatki->bindValue(':tovar', $tovar, SQLITE3_TEXT);
$insertOstatki->bindValue(':qty', $qty, SQLITE3_INTEGER);
$insertOstatki->execute();
} else {
$insertPusto->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$insertPusto->bindValue(':tovar', $tovar, SQLITE3_TEXT);
$insertPusto->execute();
}
}
$db->exec("COMMIT");
$ostatkiBuffer = '';
$pustoBuffer = '';
$result = $db->query("SELECT * FROM ostatki WHERE qty = 0");
while ($row = $result->fetchArray()) {
$ostatkiBuffer .= "Товар {$row['artikul']} {$row['tovar']} закончился, проверьте остатки!\n";
}
$result = $db->query("SELECT * FROM pusto");
while ($row = $result->fetchArray()) {
$pustoBuffer .= "Товар {$row['artikul']} {$row['tovar']} не был заведён по каким-то причинам.\n";
}
file_put_contents($ostatkiFile, $ostatkiBuffer);
file_put_contents($pustoFile, $pustoBuffer);
$email = file_get_contents($emailFile);
$emailConfig = json_decode(file_get_contents($emailConfigFile), true);
maillogfile($email, $emailConfig['smtp_username'], $emailConfig['Name'], $emailConfig);
} else {
$db = new SQLite3($dbFile);
$updateOstatki = $db->prepare("UPDATE ostatki SET qty = :qty WHERE artikul = :artikul");
$insertOstatki = $db->prepare("INSERT INTO ostatki (artikul, tovar, qty) VALUES (:artikul, :tovar, :qty)");
$deletePusto = $db->prepare("DELETE FROM pusto WHERE artikul = :artikul");
$insertPusto = $db->prepare("INSERT INTO pusto (artikul, tovar, qty) VALUES (:artikul, :tovar, 'zero')");
$csvData = [];
if (($handle = fopen($csvFile, "r")) !== FALSE) {
fgetcsv($handle, 0, ";"); // Skip header
while (($data = fgetcsv($handle, 0, ";")) !== FALSE) {
$csvData[] = $data;
}
fclose($handle);
}
$db->exec("BEGIN TRANSACTION");
foreach ($csvData as $data) {
$artikul = $data[1];
$tovar = mb_convert_encoding($data[2], 'UTF-8', 'Windows-1251');
$qty = $data[13];
if (is_numeric($qty)) {
$result = $db->querySingle("SELECT qty FROM ostatki WHERE artikul = '$artikul'", true);
if ($result) {
if ($result['qty'] != $qty) {
$updateOstatki->bindValue(':qty', $qty, SQLITE3_INTEGER);
$updateOstatki->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$updateOstatki->execute();
}
if ($qty == 0 && $result['qty'] > 0) {
$ostatkiBuffer .= "Товар {$artikul} {$tovar} закончился, проверьте остатки!\n";
}
} else {
$insertOstatki->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$insertOstatki->bindValue(':tovar', $tovar, SQLITE3_TEXT);
$insertOstatki->bindValue(':qty', $qty, SQLITE3_INTEGER);
$insertOstatki->execute();
$ostatkiBuffer .= "Добавлен товар {$artikul} {$tovar} с остатком {$qty}.\n";
}
$deletePusto->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$deletePusto->execute();
} else {
$result = $db->querySingle("SELECT qty FROM pusto WHERE artikul = '$artikul'", true);
if (!$result) {
$insertPusto->bindValue(':artikul', $artikul, SQLITE3_INTEGER);
$insertPusto->bindValue(':tovar', $tovar, SQLITE3_TEXT);
$insertPusto->execute();
}
}
}
$db->exec("COMMIT");
file_put_contents($ostatkiFile, $ostatkiBuffer);
file_put_contents($pustoFile, $pustoBuffer);
$email = file_get_contents($emailFile);
$emailConfig = json_decode(file_get_contents($emailConfigFile), true);
maillogfile($email, $emailConfig['smtp_username'], $emailConfig['Name'], $emailConfig);
}
$endTime = microtime(true);
$executionTime = $endTime - $startTime;
echo "Время выполнения скрипта: " . round($executionTime, 2) . " секунд";
?>
Сам бы я такое на написал даже после обучение в полгода-год как мне кажется.. по сути тут работы с нейросетью мне на полдня ( хотя в итоге было три попытки- часа по два каждый раз)
Еще стоит учесть что и тех.задание переписывал ( это уже вторая версия глобально). В первый раз почти все получилось- но что-то пошло не так..и на второй день уже снова делал с нуля..и новое тех.задание ( другими словами). Первые запуски были тормозные- секунд по 20.. было переформулировано- сделай быстрей... Нейросеть давала советы- как сделать лучше- переписывала код.. В итоге обработка файла где 1000 товаров- происходит примерно за секунду.
Так то можно даже чему-то научиться если читать советы:-)
Вот и смотрите теперь- как вам такое? Может ли быть полезно? Всякие обработки эксель файлов на ура с кучей условий ( мне практические такое требуется). В итоге конечно на практических примерах лучше тренироваться- тогда можно научиться чему-то.. а если теоретически- даже и не знаю что у этого железного мозга спрашивать:-)
Были нюансы- на хостинге через планировщик не запускалось- были ошибки- спросил в чем дело- оно тоже дало совет, варианты из-за чего могла быть проблема.. так что пользы много))
Нужна помощь обычному пользователю ПК, как переименовать файлы расширения *csv с одним листом по ячейке A1.
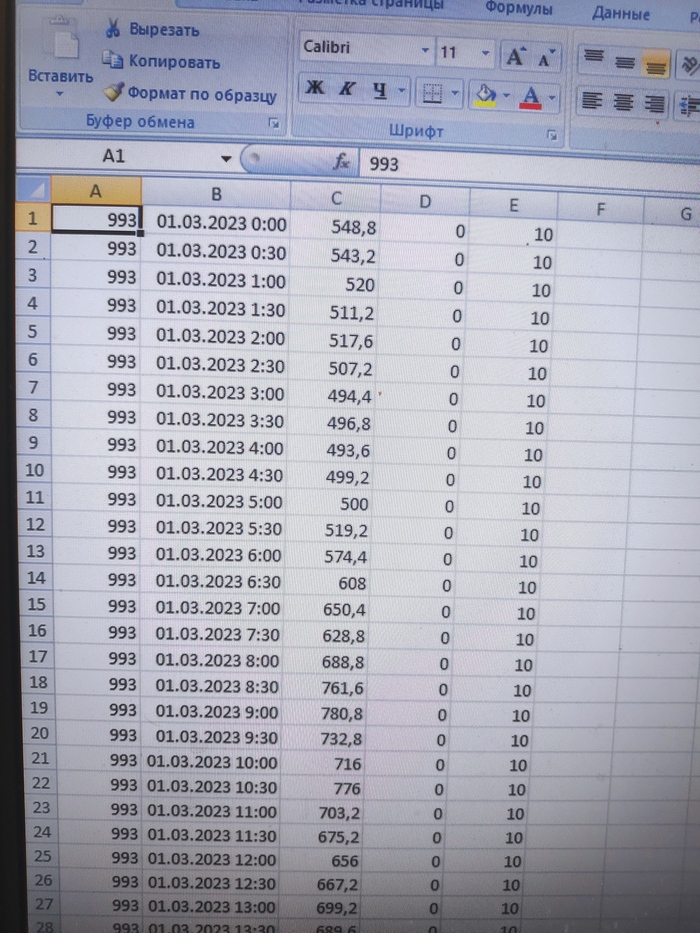
Имеется папка с большим количеством файлов формата CSV, все они одной структуры(столбцы одинаковы)
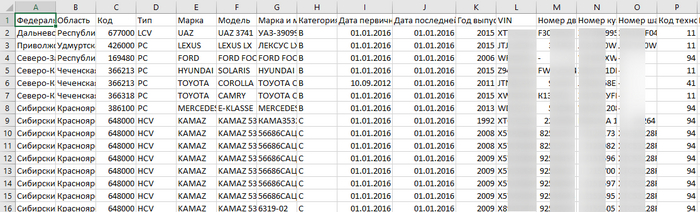
Файлы CSV являются текстовыми и имеют структуру через разделение символом ;
Сделаем обработку файлов и сохранение в базу данных
В общем виде, открываем файл на чтение, читаем каждую строку, получаем данные столбцов и сохраняем в таблицу:
$DIR = 'data/';
$files = scandir($DIR);
foreach($files as $k => $file)if($file!='.'&&$file!='..'){
$cfile = $DIR.$file;
$pi=pathinfo($cfile);
$open = fopen($cfile, "r");
$strnum=0;
while (($data = fgetcsv($open, 10000, ";")) !== FALSE){
$data = array_map( "convert", $data );
if($strnum>$proc['pos']){
DB_insert($DB,$data,$file);//записываем в таблицу
}
}
fclose($open);
}
function convert( $str ) {//преобразуем кодировку для базу данных
return iconv( "Windows-1251", "UTF-8", $str );
}
Код обходит указанную папку, открывает каждый файл и заносит данные в базу данных. Процесс долгий и его необходимо выполнять в консоли или реализовывать процесс сохранения этапа работы в отдельный файл и при новом вызове брать параметры.
function DB_insert($DB,$data,$file){
$values = array();
$kol=0; $i=0; foreach($polya as $k => $v){
if(isset($data[$i])&&$data[$i]!='') $values[] = '"'.$DB->rescape($data[$i]).'"';
else { $values[] = '""'; $kol++; }
$i++;
}
if(count($polya)!=$kol){
$sql = 'INSERT INTO tablevins VALUES(0,"'.$DB->rescape($file).'",'.implode(',',$values).');';
$rez = $DB->QUR($sql);
}
}
Реализация WEB интерфейса для поиска данных
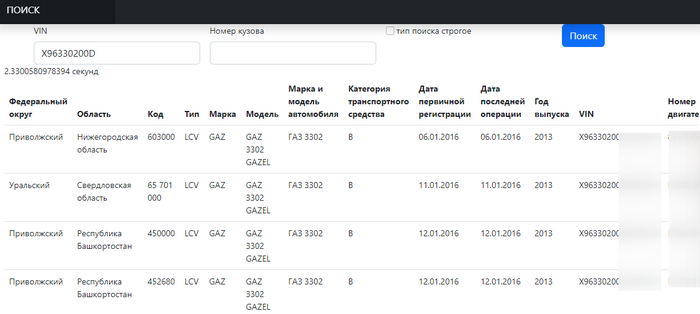
Поиск происходит по двум полям VIN и номеру кузова. Опция «тип поиска» позволяет объединять искомые по условию «И» или «ИЛИ»
Функция для поиска в таблице данных, универсальная и получает опции поиска через переменную $data
function DB_search($DB,$data){
$out = array(); $usl = array();
foreach($data['where'] as $k => $v){ if($v!=''){
$usl[] = $k.' LIKE "%'.$DB->rescape($v).'%"';
}
}
if(count($usl)){
$tip = ' OR '; if($data['tipsearch']==1) $tip = ' AND ';
$sql = 'SELECT * FROM tablevins WHERE '.implode($tip,$usl);
$rez = $DB->QUR_SEL($sql);
if(!$rez['err']&&$rez['kol']){ $out = $rez['rez']; }
}
return $out;
}
Более подробно можно посмотреть на https://alneo.ru/2022/12/poisk-v-fajlah-csv/
Доброго дня всем.
Вопрос такой. Есть много файлов CSV с данными.
Можно ли как то объединить все эти файлы для более удобного поиска в них информации?
Может создать какую то БД в которой будет вся информация из файлов и по ней уже можно будет искать?
Возможно ли какими то средствами это сделать? MySQL?
В программировании не понимаю вообще, но попробовать хочется.

Необходимое предисловие в эти чёрные дни
С началом войны РФ с Украиной мои статьи потеряли смысл на фоне этого ада. Продуктивно работать почти невозможно. Кто-то потерял дом, кто-то детей. Миллионы беженцев. Два из трёх этажей своего дома я отдал под размещение двух семей беженцев с детьми. Если у вас есть возможности, помогайте нуждающимся. Сейчас много пишут про поддержку бизнеса в РФ. Самая лучшая поддержка бизнесу и народу — вывести войска из Украины. Людей убивать нельзя!
Деньги на ЕГРИП были собраны донатами до войны. С опозданием, но я должен выполнить обещанное.
Доступ к данным ЕГРИП в XML и JSON
Если вы не прочитали статью “ЕГРЮЛ, доходы и расходы, налоги, количество сотрудников в XML и JSON бесплатно”, то начните с неё, там описано как получить данные в XML или JSON по ИНН или ОГРН. Там же есть примеры кода и ссылки на описание форматов данных. Для индивидуальных предпринимателей точно также данные получаются по ИНН или ОГРНИП.
Все индивидуальные предприниматели, доступны по следующим ссылкам с ИНН физических лиц:
https://egrul.itsoft.ru/770300584079.json
https://egrul.itsoft.ru/770300584079.xml
https://egrul.itsoft.ru/770300584079
Индивидуальные предприниматели также доступны по ссылкам с ОГРНИП.
https://egrul.itsoft.ru/308774631700332.json
https://egrul.itsoft.ru/308774631700332.xml
https://egrul.itsoft.ru/308774631700332
Оригинальные архивы ЕГРЮЛ, ЕГРИП
Эти архивы ФНС РФ предоставляет за 300 000р. в год:
новый формат ЕГРЮЛ (архивы с 2021 года)
старый формат ЕГРЮЛ (архивы с 2018 года)
новый формат ЕГРИП (архивы с 2021 года)
Мы написали претензию ФНС с требованием выложить все архивы с 2002 года и получили отписку. Сейчас в данных обстоятельствах нет моральных сил с ними судиться и биться за развитие российской экономики. Пока взяли паузу. Может война закончится, а может экономика. И тогда вопрос отпадёт сам собой. В папках _FULL все данные на начало года. Далее изменения.
Обработанные данные в форматах csv
Архивы ЕГРЮЛ, ЕГРИП и обновления к ним в формате csv.
- org: ОГРН, ИНН, max_num;
- org2: организации;
- person: физические лица и индивидуальные предприниматели;
- org_chief: руководители организаций;
- founder: учредители;
- mng: управляющие организации;
- income_outcome: доходы и расходы;
- taxes: налоги;
- tax_systems: налоговые системы;
- ssch: среднесписочная численность;
- msp: микропредприятия, малые, средние;
- support: господдержка;
- okved_ref: оквэд;
- opf: организационно-правовая форма;
- org_status_ref: справочник статусов организаций;
- org_status: статусы организаций;
- predecessor: предшественники;
- country: страны.
min_num, max_num, cdate_num, update_at_num — это сокращённая форма даты в виде двухбайтового целого. Дата в номер и обратно преобразуется по следующим правилам:
$d = date(‘Y-m-d’);
$d_num = (intval($d[2] . $d[3])<<9) + (intval($d[5] . $d[6])<<5) + intval($d[8] . $d[9]);
$d2 = ‘20’ . sprintf(“%’.02d”, $d_num>>9) . ‘-’ . sprintf(“%’.02d”, ($d_num>>5)&15) . ‘-’ . sprintf(“%’.02d”, $d_num&31);
Эти поля нужны для реализации Медленно меняющихся измерений (от англ. Slowly Changing Dimensions, SCD) типа 2. min_num или cdate_num хранят дату начала действия этой строки, например, для руководителя — это дата когда человек стал руководителем организации. max_num, updated_at_num — дата последней выписки где данный факт был обнаружен. Если дата org_chief.max_num меньше org.max_num, то org_chief.max_num дата, когда человек пропал из руководителей в ЕГРЮЛ. Реально он мог перестать быть руководителем чуть раньше.
Актуальные данные надо соединять по ogrn и org.max_num. Записи в соединённых таблицах с max_num < org.max_num хранят историю по организации.
org2.crc32 — это уникальный ключ crc32(kpp, short_name, full_name, street, house, corpus, apartment). В org2 хранится история изменения юридического адреса и наименования организации.
По остальным таблицам полагаю должно быть всё понятно из названия полей и документации к данным (см. Приказ ФНС России от 18.01.2021 N ЕД-7–14/17@).
Уставной капитал
Уставной капитал отсутствует в некоторых ООО. Но его можно вычислить по сумме уставных капиталов учредителей.
Отчёты и анализ данных ЕГРЮЛ, ЕГРИП
- Топ управляющих организаций по количеству организаций, которыми они управляют.
- Топ руководителей организаций по количеству организаций, которыми они руководят.
- Топ предпринимателей по количеству организаций, которые они учредили.
- Топ организаций по количеству организаций, которые они учредили.
- Организации, где учредитель РФ.
- Организации, где есть учредитель иностранное лицо.
- Организации с оборотом от миллиарда рублей за 2020 год.
В отчёте “Организации с оборотом от миллиарда рублей за 2020 год” вы можете видеть, что налогов ряд крупных организации платят около нуля, сотрудников в некоторых тоже крайне мало в пересчёте на приход. Если сравнить с малым бизнесом, где налоговая нагрузка порядка 3–7%, то крупные компании явно недоплачивают и работают там какие-то многорукие и многоголовые, что на одного сотрудника бывает миллиарды прихода.
Невероятное
Леденев Владимир Владимирович руководитель в 2874 организациях с большим отрывом опережает всех остальных. Правда там за ним следуют 8 руководителей в 1000 организаций. Эх, нам бы базу с 2002 года, вот это бы данные были. Такие люди заслуживают статьи в Википедии.
Присылайте ссылки на ваши проекты
Ссылки на полезные и бесплатные проекты мы опубликуем на нашем сайте.
Если вы сделаете анализ выложенных данных
У нас запланирована следующая статья с рядом очень интересных отчётов. Количество отчётов, которые только можно придумать огромное. Поэтому мы рады будем всем любителям анализировать данные.
Донаты
На следующий год проекту нужно 300 000р на покупку данных у ФНС РФ. Нужен второй сервер. Не помешают деньги на дальнейшее развитие и добавление других данных. Кто-то обещал задонатить после публикации ЕГРИП и архивов. Пожалуйста, закиньте денег сколько можете. Это реально важно.
Подробности и дополнительная информация здесь.
Всем доброго времени суток. Выгружаю csv с сайта-конструктора , затем создаю новый документ в excel и импортирую данные из csv файла. Все прекрасно открывается и редактируется. А как сохранить изменения именно в исходном csv файле? "Сохранить как - csv" не подходит, так как мы создаем новый файл, а не обновляем старый-отображение уже поменялось, и конструктор сайтов начинает жаловаться.
Если обновить данные, excel обновляет все от исходного csv файла, то есть все изменения откатываются(значок сбоку на скрине).
Простыми словами - чтобы в выгруженной мешанине внести правки и такую же мешанину скормить конструктору.







