


Оперативно-тактический комплекс анализа производительности СУБД PostgreSQL "PG_HAZEL" - общая схема
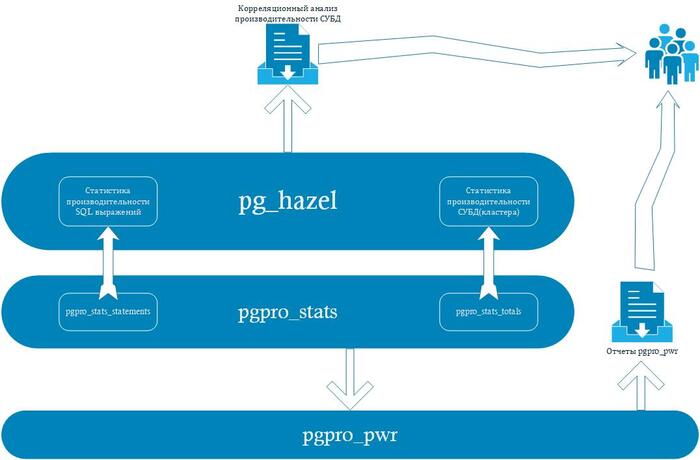
Общая структурная схема потоков данных
На текущий момент - 756КБ исходников на bash и PL/pgSQL .
Показать полностью
1
Общая структурная схема потоков данных
На текущий момент - 756КБ исходников на bash и PL/pgSQL .
Имеется SQL запрос используемый , используемый в качестве бенчмарка.
Идея очень простая - среднее(медианное) время выполнения запроса является показателем пропускной способности СУБД в целом.
Гипотеза - увеличение benchmark кластера 📈при нулевом значении ожиданий - свидетельствует о нехватке вычислительной мощности для СУБД. Или другими словами - пропускная способность СУБД не соответствует характеру нагрузки.
При проведении нагрузочного тестирования хорошо видно, что после определённого значения нагрузки на СУБД (количество сессий pgbench), среднее время бенчмарк увеличивается . Т.е. если гипотеза подтвердится , то можно будет использовать бенчмарк для оценки пропускной способности СУБД.

Начало и описание метрик производительности : PG_HAZEL - оперативно-тактический комплекс мониторинга производительности СУБД PostgreSQL .
Какая База Данных оказывает наибольшее влияние на производительность кластера в целом?
Какой/какие SQL запросы оказывают наибольшее влияние на снижение производительности ?
Данные вопросы имеют смысл для анализа производительности СУБД в ходе эксплуатации. При проведении нагрузочного тестирования заранее известно - какая База Данных оказывает влияние на производительность СУБД в целом и какой SQL запрос оказывает наибольшее влияние на производительность кластера.
Поэтому будут рассмотрены лишь общие методики тактического анализа и связь между метриками производительности СУБД .
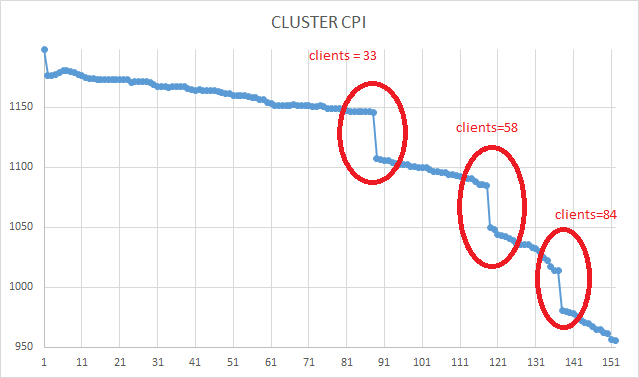
Ось X - точка времени . Ось Y - комплексный индикатор производительности СУБД
Таким образом из графика можно сделать следующий вывод: наибольшее влияние на производительность кластера оказывает нагрузка в ходе нагрузочного тестирования при 33, 58 и 84 клиентских сессий pgbench.
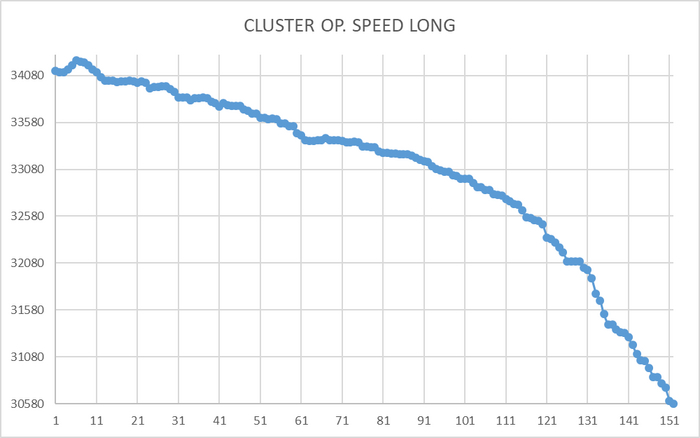
Ось X - точка времени . Ось Y - операционная скорость СУБД
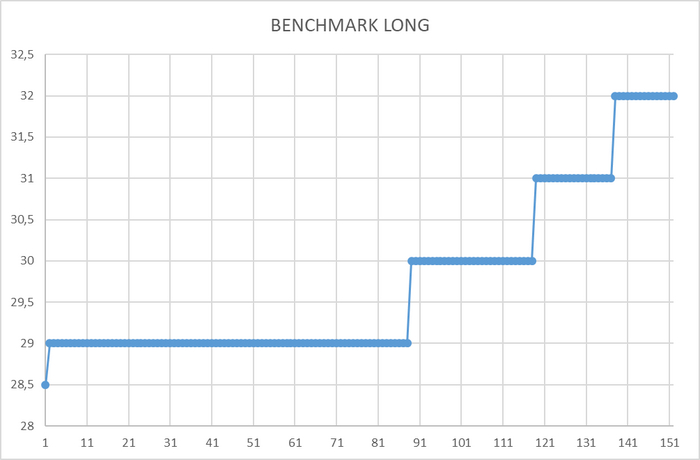
Ось X - точка времени . Ось Y - медианное время работы BENCHMARK СУБД
Нагрузка на тестовую СУБД оказывает влияние на производительность СУБД в целом при количестве клиентов pgbench = 33, 58, 84.
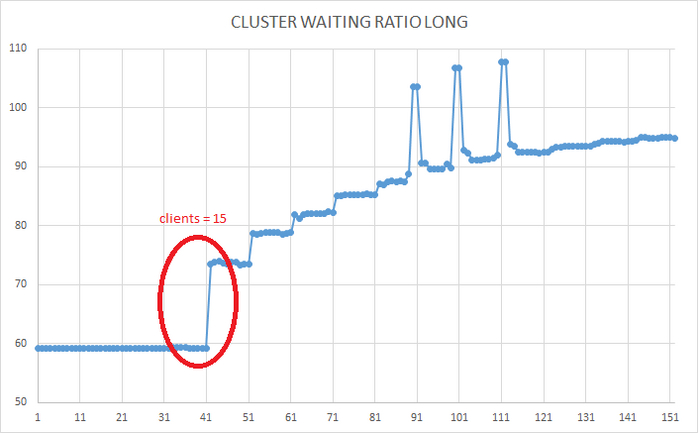
Ось X - точка времени . Ось Y - отношение времени ожиданий к общему времени работы СУБД
При количестве клиентов pgbench = 15 ожидания резко возрастают.
По итогам анализа метрик производительности СУБД на тактическом уровне , можно сделать следующие выводы по производительности данной СУБД при данном характере нагрузки :
Штатная нагрузка на СУБД составляет 15 клиентов.
После 33 клиентов начинается влияние и деградация производительности СУБД в целом.
Сбор и статистический анализ информации по ожиданиям клиентских SQL запросов
Обновление методики корреляционного анализа Корреляционный анализ для определения причин деградации производительности СУБД PostgreSQL с использованием нового инструментария

Начало и описание метрик производительности : PG_HAZEL - оперативно-тактический комплекс мониторинга производительности СУБД PostgreSQL .
Стандартный сценарий аналогичный TPC-B.
Рост нагрузки , экспоненциально : --client=клиенты
Число имитируемых клиентов, то есть число одновременных сеансов базы данных.
Продолжительность тестового прохода = 10 минут.
Максимальная нагрузка = 100 клиентов.
Общее число проходов = 20
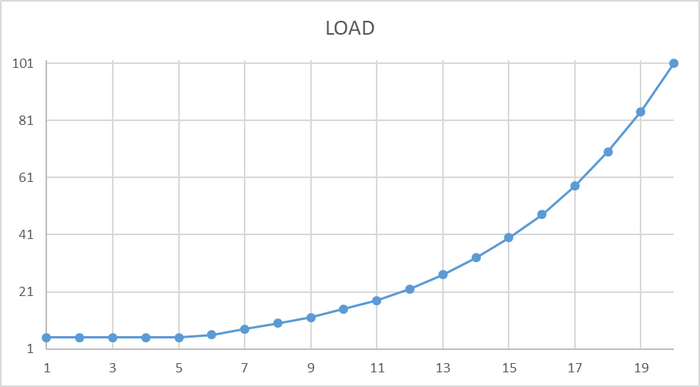
Ось X - номер прохода. Ось Y - количество клиентов.
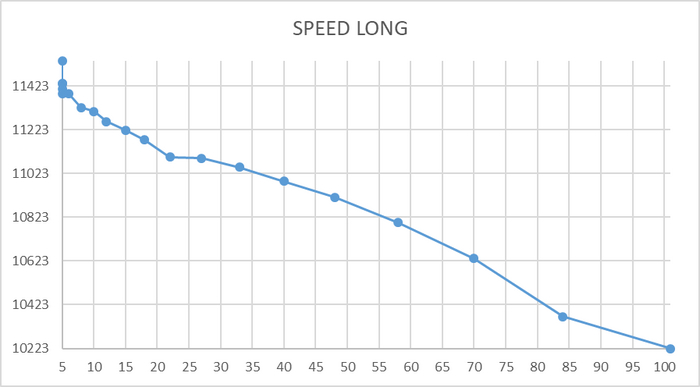
Ось X - количество клиентов. Ось Y - операционная скорость.
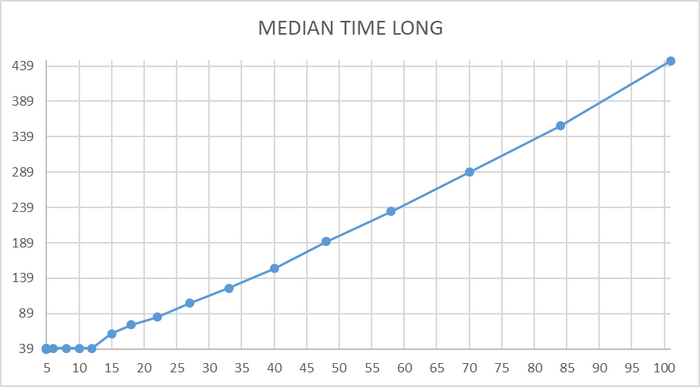
Ось X - количество клиентов. Ось Y - медианное время работы SQL запроса
Как было определено в статье PG_HAZEL : оперативно-тактический комплекс мониторинга производительности СУБД PostgreSQL - общее описание.
В процессе анализа производительности СУБД , во-первых необходимо решить задачи оперативного уровня :
В каком состоянии находится производительность СУБД в данный момент времени?
Какая тенденция развития производительности СУБД на текущий момент или в прошлом?
На сколько снизилась производительность СУБД по сравнению с выбранным промежутком из прошлого?
Для ответа на данные вопросы достаточно проанализировать график изменения комплексного индикатора производительности в ходе нагрузочного тестирования.
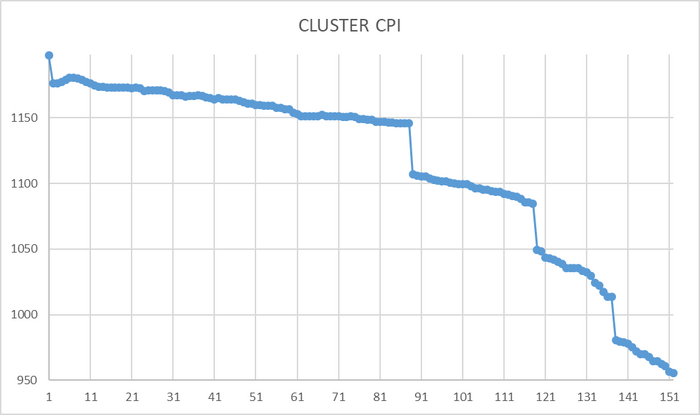
Ось X - точка времени снятия данных . Ось Y -комплексный индикатор производительности СУБД
Ответ - функция комплексного индикатора производительности носит кусочно-непрерывный характер и уменьшается в ходе тестирования.
Снижение производительности в ходе нагрузочного тестирования составило -20,1969%
Использование оперативно-тактического комплекса pg_hazel позволяет решать задачи анализа производительности СУБД на оперативном уровне.

Рgpro_pwr — инструмент стратегического мониторинга нагрузки на базу данных, который помогает DBA выявлять самые ресурсоёмкие операции.
Однако, в ходе решения задач сопровождения СУБД PostgreSQL возникают не только стратегические , но и оперативные и тактические задачи для которых инструмент стратегического мониторинга довольно громоздкий , что не очень удобно для быстрого решения ряда задач.
Задачи решаемые на оперативном уровне:
В каком состоянии находится производительность СУБД в данный момент времени?
Какая тенденция развития производительности СУБД на текущий момент или в прошлом?
На сколько снизилась производительность СУБД по сравнению с выбранным промежутком из прошлого?
Задачи тактического уровня:
Какая База Данных оказывает наибольшее влияние на производительность кластера в целом?
Какой/какие SQL запросы оказывают наибольшее влияние на снижение производительности ?
В ходе предварительных исследований были проверены разные способы расчета метрики производительности СУБД .
Подробнее здесь: Производительность СУБД PostgreSQL — расчет метрики, временной анализ, параметрическая оптимизация
Однако , методы описанные в статье , к сожалению имеют свои аномалии.
Теоретически, наиболее близким к физическому определению производительность системы будет объемная скорость информации переданной клиенту , или другими словами - объем строк переданных запросом. Но к сожалению, на текущий момент , получить такую информацию - нет технической возможности. Важно - количество строк в запросе это не объем. Длина строки внутри выборки может меняться в очень широких диапазонах.
Поэтому было принято решения - непосредственный расчет производительности СУБД как физической величины - отложить на будущее, до реализации механизма получения объема данных переданных запросом.
Для решения задач анализа производительности СУБД используются индикаторы производительности СУБД и комплексный анализ изменения значений метрик производительности СУБД.
Источником данных являются представления расширения pgpro_stats
Статистика, собираемая модулем, выдаётся через представление с именем pgpro_stats_statements. Это представление содержит отдельные строки для каждой комбинации идентификатора базы данных, идентификатора пользователя и идентификатора запроса
Агрегированная статистика, собранная модулем, выдаётся через представление pgpro_stats_totals. Это представление содержит отдельные строки для каждого отдельного объекта БД
Данные собираются ежеминутно и агрегируются на 3-х уровнях:
Уровень Кластера
Уровень Базы Данных
Уровень SQL запроса
Как было указано ранее данные о среднем времени выполнения запроса собираемые в расширениях pg_stat_statements или pgpro_stats имеют очень серьезную проблему - среднее арифметическое не устойчиво к выбросам.
Поэтому для корректного расчета среднего времени выполнения запроса используется не среднее арифметическое , а медиана.
К сожалению, расчет проводимый на уровне БД требует специальной подготовки для тестового запроса и дополнительных ресурсов для хранения и статистического анализа данных. Поэтому применяется не для всех SQL запросов а только для конкретных тестовых запросов:
Benchmark кластера - медианное время выполнения тестового запроса для оценки производительности кластера в целом.
Тестовый запрос стресс-тестирования - медианное время выполнения запроса по выбранному сценарию в ходе проведения стресс-теста(нагрузочного тестирования)СУБД.
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за период.
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания СУБД за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий СУБД в общем времени работы СУБД за период.
CORRELATION - коэффициент корреляции между количеством активных сессий и операционной скоростью.
BENCHMARK - медианное время выполнения тестового запроса.
CPI - комплексный индикатор производительности = Операционная скорость / BENCHMARK .
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за период.
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания БД за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий БД в общем времени работы БД .
Операционная скорость - количество завершенных операций и сформированных строк за период .
Объемная скорость - объем обработанных блоков распределенной/локальной/временной области за за период .
Активные сессии - количество активных сессий на точку времени.
Ожидания - количество событий ожидания SQL запроса за период.
BUFFERPIN - количество событий ожидания bufferpin за период.
EXTENSION - количество событий ожидания extension за период.
IO - количество событий ожидания io за период.
IPC - количество событий ожидания ipc за период.
LOCK - количество событий ожидания lock за период.
LWLOCK - количество событий ожидания lwlock за период.
WAITING_RATIO - относительная доля ожиданий SQL запроса в общем времени работы SQL запроса .
Важное уточнение
Для данных используется медианное сглаживание - короткий период 10 минут , долгий период 60 минут.
Примеры практического применения и анализа на основе собранных данных - в следующих статьях.
Оригинал статьи: Дзен канал Postgres DBA
Необходимое предисловие
Статья создана в далеком 2019 году. Это была моя первая статья на Хабре.
Теперь в качестве первой статьи в сообществе Пикабу.
Как известно, существует всего два метода для решения задач:
Метод анализа или метод дедукции, или от общего к частному.
Метод синтеза или метод индукции, или от частного к общему.
Для решения проблемы “улучшить производительность базы данных” это может выглядеть следующим образом.
Анализ — разбираем проблему на отдельные части и решая их пытаемся в результате улучшить производительности базы данных в целом.
На практике анализ выглядит примерно так:
Возникает проблема (инцидент производительности)
Собираем статистическую информацию о состоянии базы данных
Ищем узкие места(bottlenecks)
Решаем проблемы с узких мест
Узкие места базы данных — инфраструктура (CPU, Memory, Disks, Network, OS), настройки(postgresql.conf), запросы:
Инфраструктура: возможности влияния и изменения для инженера — почти нулевые.
Настройки базы данных: возможности для изменений чуть больше чем в предыдущем случае, но как правило все -таки довольно затруднительны, особенно в облаках.
Запросы к базе данных: единственная область для маневров.
Синтез — улучшаем производительность отдельных частей, ожидая, что в результате производительность базы данных улучшится.
Как происходит процесс решения инцидентов производительности, если производительность базы данных не мониторится:
Заказчик -”у нас все плохо, долго, сделайте нам хорошо”
Инженер-” плохо это как?”
Заказчик –”вот как сейчас(час назад, вчера, на прошлой деле было), медленно”
Инженер – “а когда было хорошо?”
Заказчик – “неделю (две недели) назад было неплохо. “(Это повезло)
Заказчик – “а я не помню, когда было хорошо, но сейчас плохо “(Обычный ответ)
В результате получается классическая картина:

На первую часть вопроса ответить легче всего — виноват всегда инженер DBA.
На вторую часть ответить тоже не слишком сложно — нужно внедрять систему мониторинга производительности базы данных.
Возникает первый вопрос — что мониторить?
Путь 1. Будем мониторить ВСЁ

Загрузку CPU, количество операций дискового чтения/записи, размер выделенной памяти, и еще мегатонна разных счетчиков, которые любая более-менее рабочая система мониторинга может предоставить.
В результате получается куча графиков, сводных таблиц, и непрерывные оповещения на почту и 100% занятость инженера решением кучи одинаковых тикетов, впрочем, как правило со стандартной формулировкой — “Temporary issue. No action need”. Зато, все заняты, и всегда есть, что показать заказчику — работа кипит.
Можно мониторить, чуть по-другому- только сущности и события:
На которые инженер DBA может влиять
Для которых существует алгоритм действий при возникновении события или изменения сущности.
Исходя из этого предположения и вспоминая «Философское вступление» с целью избежать регулярного повторения «Лирическое вступление или зачем все это надо» целесообразно будет мониторить производительность отдельных запросов, для оптимизации и анализа, что в конечном итоге должно привести к улучшению быстродействия всей базы данных.
Но для того, чтобы улучшить тяжелый запрос, влияющий на общую производительность базы данных, нужно сначала его найти.
Итак, возникает два взаимосвязанных вопроса:
какой запрос считается тяжелым
как искать тяжелые запросы.
Очевидно, тяжелый запрос это запрос который использует много ресурсов ОС для получения результата.
Переходим ко второму вопросу — как искать и затем мониторить тяжелые запросы ?
По сравнению с Oracle, возможностей немного, но все-таки кое-что сделать можно.

Для поиска и мониторинга тяжелых запросов в PostgreSQL предназначено стандартное расширение pg_stat_statements.
После установки расширения в целевой базе данных появляется одноименное представление, которое и нужно использовать для целей мониторинга.
Целевые столбцы pg_stat_statements для построения системы мониторинга:
queryid Внутренний хеш-код, вычисленный по дереву разбора оператора
max_time Максимальное время, потраченное на оператор, в миллисекундах
Накопив и используя статистику по этим двум столбцам, можно построить мониторинговую систему.
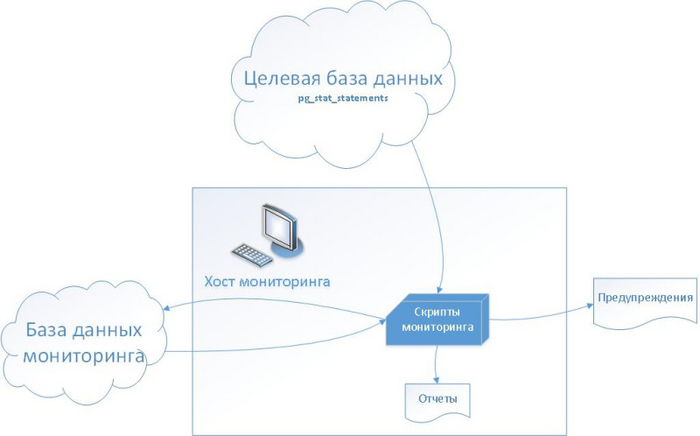
Для мониторинга производительности запросов используется:
На стороне целевой базы данных — представление pg_stat_statements
Со стороны сервера и базы данных мониторинга — набор bash-скриптов и сервисных таблиц.
На хосте мониторинга по крону регулярно запускается скрипт который копирует содержание представления pg_stat_statements с целевой базы данных в таблицу pg_stat_history в базе данных мониторинга.
Таким образом, формируется история выполнения отдельных запросов, которую можно использовать для формирования отчетов производительности и настройки метрик.
Основываясь на собранных данных, выбираем запросы, выполнение которых наиболее критично/важно для клиента(приложения). По согласованию с заказчиком, устанавливаем значения метрик производительности используя поля queryid и max_time.
Мониторинговый скрипт при запуске проверяет сконфигурированные метрики производительности, сравнивая значение max_time метрики со значением из представления pg_stat_statements в целевой базе данных.
Если значение в целевой базе данных превышает значение метрики – формируется предупреждение (инцидент в тикетной системе).
История планов выполнения запросов
Для последующего решения инцидентов производительности очень хорошо иметь историю изменения планов выполнения запросов.
Для хранения истории используется сервисная таблица log_query. Таблица заполняется при анализе загруженного лог-файла PostgreSQL. Поскольку в лог-файл в отличии от представления pg_stat_statements попадает полный текст с значениями параметров выполнения, а не нормализованный текст, имеется возможность вести лог не только времени и длительности запросов, но и хранить планы выполнения на текущий момент времени.
Continuous performance improvement process
Мониторинг отдельных запросов в общем случае не предназначен для решения задачи непрерывного улучшения производительности базы данных в целом поскольку контролирует и решает задачи производительности только для отдельных запросов. Однако можно расширить метод и настроить мониторинг запросы для всех базы данных.
Для этого нужно ввести дополнительные метрики производительности:
За последние дни
За базовый период
Скрипт выбирает запросы из представления pg_stat_statements в целевой базе данных и сравнивает значение max_time со средним значением max_time, в первом случае за последние дни или за выбранный период времени(baseline), во-втором случае.
аким образом в случае деградации производительности для любого запроса, предупреждение будет сформировано автоматически, без ручного анализа отчетов.
В описанной подходе, как и предполагает метод синтеза — улучшением отдельных частей системы, улучшаем систему в целом.
Запрос выполняемый базой данных – тезис
Измененный запрос – антитезис
Изменение состояние системы — синтез

Расширения собираемой статистики добавлением истории для системного представления pg_stat_activity
Расширение собираемой статистики добавлением истории для статистики отдельных таблиц участвующих в запросах
Интеграция с системой мониторинга в облаке AWS
И еще, что-нибудь можно придумать…

Взято из архива основного технического канала Postgres DBA
Предисловие
В ходе работ по подготовке эпюры производительности СУБД в очередной раз была получена иллюстрация проблем использования среднего арифметического при расчете производительности СУБД .
Последовательный рост нагрузки на СУБД
По X - номер итерации. По Y - количество сессий pgbench
Первые же результаты , показали несогласованность pgbench - TPS - с реальными показателями производительности СУБД
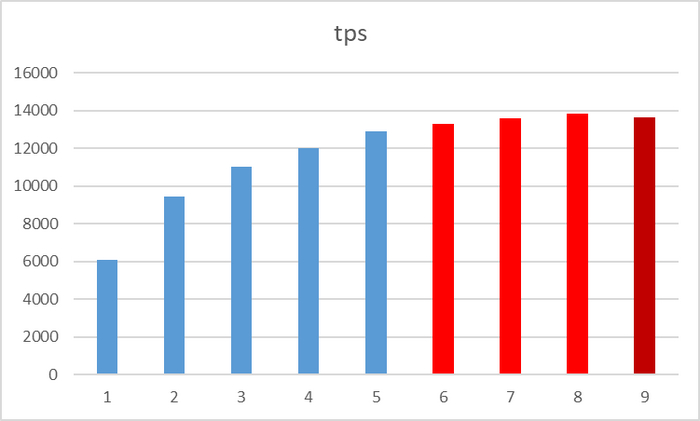
По оси X - номер итерации. По оси Y - TPS. TPS по результатам pgbench - растет.
Значение tps получено тривиально, из результата теста :
лог | grep tps
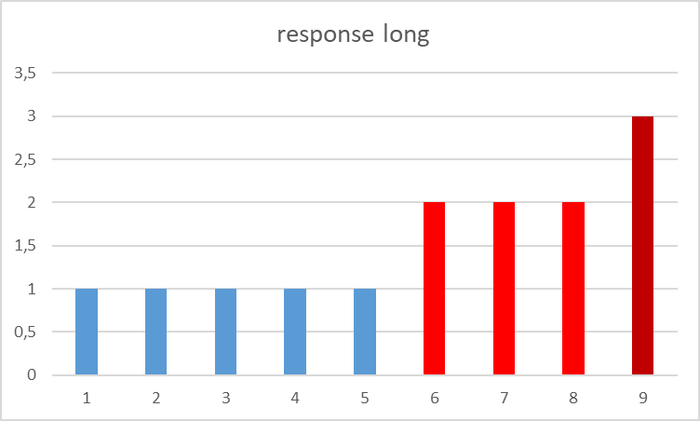
По оси X - номер итерации. По оси Y - среднее время отклика СУБД.
Время отклика вычисляется , также, стандартно:
SUM(total_exec_time) / SUM(calls)
За период из представления pg_stat_statements.
1) Если ориентироваться на результаты pgbench, то , при росте количества подключений c 60 до 70 - tps вырос с 12870,870996 до 13294,489494 (+3%)
2) Если ориентироваться на среднее время отклика СУБД , то, при аналогичном росте количества подключений c 60 до 70 - среднее время отклика увеличилось на 100%
Производительность СУБД растет с ростом нагрузки или нет ?
Очередная иллюстрация на тему - ни TPS , ни время отклика - по отдельности не являются метриками производительности СУБД, потому, что не позволяют предсказать и описать реальную картину и получить объективные данные о реальной производительности СУБД .
P.P.S. Также нужно отметить, что история и анализ данных tps из лога pgbench с помощью grep - не самая удобная процедура . Особенно если не одна итерация, а несколько десятков.
Так, что - как средство создания нагрузки pgbench вполне рабочий и удобный инструмент. Как средство анализа результатов - нет.
Послесловие
Материал носит ознакомительный, справочный характер. Используемая методика расчета среднего времени отклика СУБД в настоящее время не используется. Вообще , среднее арифметическое в расчетах не используется. Да и методика расчета производительности СУБД сильно изменена , в настоящее время идут тесты и анализ результатов. Статьи будут чуть позже.
В связи с проблемами более подробно разобранными в статье О проблеме использования mean_exec_time при анализе производительности PostgreSQL
В качестве дополнения к статье Первый пост
Важное пояснение
Статья только в качестве "на память" и для популяризации и обсуждения идеи , описываемые методики изменены и сейчас не используются, ведется работа по тестированию новой методологии и инструментария. Материалы и результаты расчетов - будут чуть позже.

Как известно, основная задача DBA - обеспечить наиболее эффективную и производительную работу вверенной ему в сопровождение СУБД. Для выполнения задачи одно из основных требований - умение определить насколько производительно/эффективно СУБД справляется с получаемой нагрузкой и выдает требуемый результат. Для этого необходимо определить такое понятие как производительность СУБД. Потому, что очень важно, для начала, хотя бы обеспечить мониторинг и иметь возможность сразу сказать - в каком состоянии СУБД - минимальная загрузка, оптимальная, перегруз, авария. Однако, как выясняется, общего понятия "производительность СУБД" до недавнего времени не существовало. Каждый DBA понимал под производительностью, то , что лично ему нравится - количество запросов в секунду, количество зафиксированных транзакций, среднее время отклика СУБД и даже процент утилизации CPU+RAM или вывести на экран десяток другой графиков мониторинга и каким то мистическим образом определить хорошо работает СУБД или плохо.
Ситуацию надо было менять , ибо , как говорится - для того, что бы чем то управлять и улучшать надо это уметь измерять.
Для начала надо определиться с определением и ответить на главный вопрос - что есть производительность СУБД ?
Вспоминая физику , можно использовать базовое понятие:
В физике производительность — это величина, которая обозначает объём работы, выполняемый за единицу времени (например, за час или за день). По-другому её можно назвать скоростью выполнения работы
На этапе нагрузочного тестирования одного проекта, возникла необходимость - оценить степень влияния изменений вносимых разработчиками, на эффективность работы СУБД. Тогда впервые и возникла идея - надо считать метрику производительности .
А может быть производительность СУБД это вектор: (N1, N2, N3),где:N1 - количество активных сессийN2 - количество транзакцийN3 - количество запросов к СУБД в секунду.
В принципе, метрика вполне себе работала и показывала ожидаемые результаты - основная часть изменений не оказывали вообще никакого влияния на работоспособность СУБД . В результате было сохранено очень много рабочего времени , потому , что не нужно стало объяснять и доказывать неэффективности предлагаемых изменений. Все видно на графиках и в таблицах.
Однако, как можно понять - метрика в общем то не совсем производительность считает. Очень важный момент - "количество активных сессий" , и тут возможна первая аномалия.
Аномалия учета ожиданий
Возможна ситуация - особенно при продуктивной нагрузке - работоспособность СУБД падает, а метрика растет.
Причина- количество активных сессий учитывает не только сессии выполняющие запросы , но и находящиеся в состоянии ожидания.
Порядок расчёта метрики производительности СУБД был изменен.
Было принято решение изменить методику расчета, используя вектор:(N1, N2, N3, N4, N5), где:N1 - количество страниц shared_buffer , прочитанных в секундуN2 - количество страниц shared_buffer, записанных в секундуN3 - количество страниц shared_buffer, измененных в секундуN4 - количество завершенных запросов в секундуN5 - количество зафиксированных транзакций в секунду
Этот вариант проработал дольше . И обеспечил хорошую базу для работ по статистическому анализу производительности СУБД.
Аномалия изменения плана выполнения запроса.
Для того, что бы обнаружить аномалию достаточно было провести очень простой эксперимент:
Создаем большие таблицы: родитель-потомок.
В таблицах не создаем индексы.
Подготавливаем запрос. Поскольку индексов нет , используется последовательное чтение.
Выполняем несколько итераций, фиксируем время выполнения запроса и показатель производительности СУБД.
Создаем индексы для таблиц.
Выполняем итерации того же самого запроса.
Фиксируем время выполнения запроса и показатель производительности СУБД.
Аномалия заключается в том, что запрос стал работать на порядки быстрее , стоимость запроса кардинально снизилась , следовательно эффективность резко возросла, но значение метрики - уменьшается.
Причина: При выполнении индексного доступа к данным количество обработанных страниц shared_buffer существенно уменьшается. А при использовании метода доступа Index Only Scan вообще будет нулевым. В результате значение метрики производительности уменьшается.
Для решения проблемы аномалии изменения плана выполнения запроса, расчет метрики был изменен. Необходимо было ввести новые определения .
Полезными операциями(результатами) работы СУБД являются:
Количество строк выданных пользователю.
Количество запросов выполненных пользователем.
Количество зафиксированных пользователем транзакций.
Разделив количество на количество секунд (DB Time), которые потребовались на выполнения операций СУБД в изменяемый промежуток получаем - вектор , определяющий операционную(результативную) скорость:
QPS: Количество запросов в секунду.
TPS: Количество транзакций в секунду.
RPS: Количество строк в секунду.
Для того, что бы иметь одну цифру используется модуль вектора ( QPS , TPS , RPS ).
Полученное значение и будет считаться операционной скоростью.
Работа СУБД заключается в обработке блоков информации:
Прочитанные разделяемые блоки
"Загрязнённые" разделяемые блоки
Записанные разделяемые блоки
Прочитанные локальные блоки
"Загрязнённые" локальные блоки
Записанные локальные блоки
Прочитанные временные блоки
Записанные временные блоки
Таким образом, применив тот же подход , что и для расчета операционной скорости получим- вектор, определяющий объёмную скорость :
RSBS : Прочитанные разделяемые блоки в секунду.
DSBS : "Загрязнённые" разделяемые блоки в секунду.
WSBS : Записанные разделяемые блоки в секунду.
RLBS : Прочитанные локальные блоки в секунду.
DLBS : "Загрязнённые" локальные блоки в секунду.
WLBS : Записанные локальные блоки в секунду.
RTBS : Прочитанные временные блоки в секунду.
WSBS: Записанные временные блоки в секунду.
Аналогично, для получения значения используем модуль вектора ( RSBS , DSBS , WSBS , RLBS , DLBS , WLBS , RTBS , WSBS ).
Полученное значение и будет объемной скоростью.
Отношение операционной скорости к объемной скорости и будет принято как производительность СУБД.
Как видно, производительность СУБД в течение заданного промежутка времени прямо пропорционально объёму полученного результата и обратно пропорциональна объёму обработанной для получения результата информации.
Другими словами - данная метрика показывает - насколько эффективно СУБД выдаёт результат, обрабатывая объем информации .
Т.е. если план запроса изменился так, что запрос стал выполняться быстрее и читать меньше блоков (стоимость запроса снизилась) , то в этом случае значение метрики - увеличится .
Для удобства , обозначим производительность СУБД как CPI. Тогда производительность СУБД в момент времени t , есть значение дискретной функции CPI(t).
Для сглаживания графика и исключения выбросов используется медианное сглаживание.
Дополнение: очень вероятно , что корреляция между операционной и объёмной скоростью - очень интересная тема для более подробного анализа . Нужно протестировать в самое ближайшее время .
Задача анализа производительности СУБД сводится к анализу временного ряда, сформированного из значений функции CPI(t) , для значений t от начала до окончания анализируемого периода .
Задача по оптимизации производительности СУБД сводится к задаче оптимизации функции CPI(t) при изменении набора конфигурационных параметров СУБД .
Задача - определить комбинацию параметров дающих наибольший прирост производительности .На текущий момент, первое, что сразу приходит в голову - использовать метод покоординатного спуска (в данном случае - подъёма )
Примечание
В настоящее время в стадии сбора данных несколько экспериментов по параметрической оптимизации. Результаты будут опубликованы после окончания и анализа.
В комментариях к предыдущей статье было предложено использовать не Евклидову, а Манхеттенскую метрику для расчета модуля векторов операционной и объёмной скорости . Поскольку , в общем случае, размерности векторов нельзя считать независимыми . В настоящий момент , тема в проработке. Возможно смена метрики позволит избежать каких то еще аномалий , которые пока не проявились.
