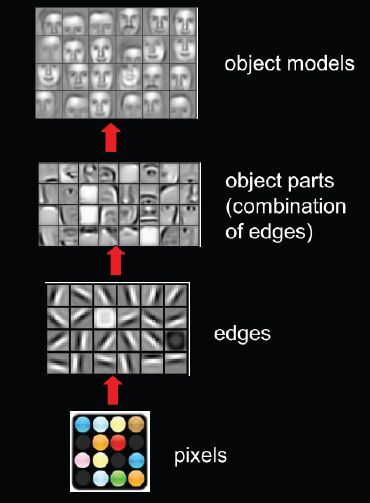
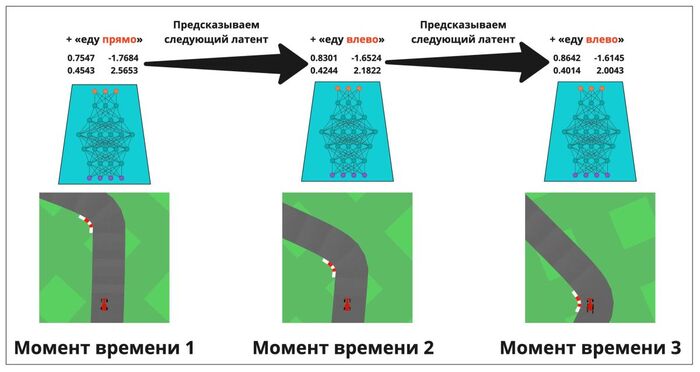
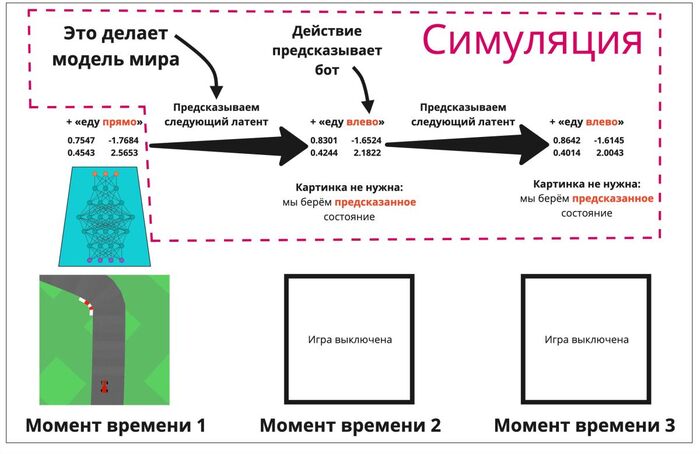
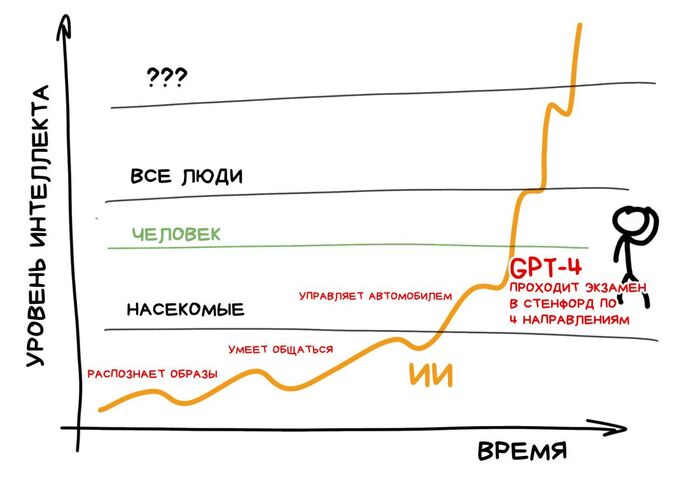
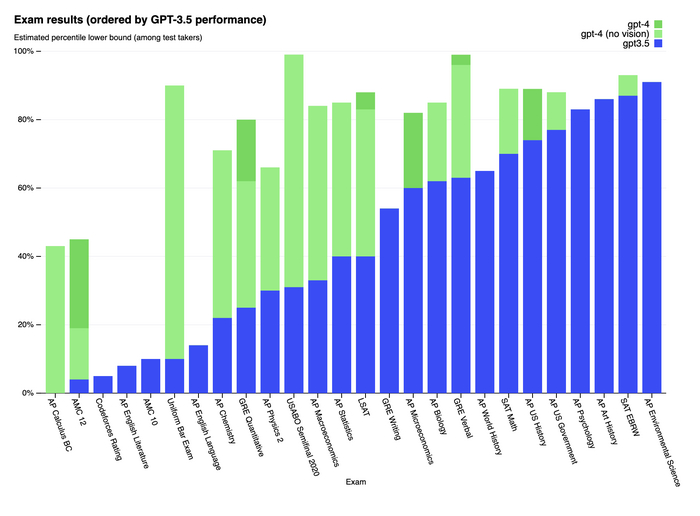
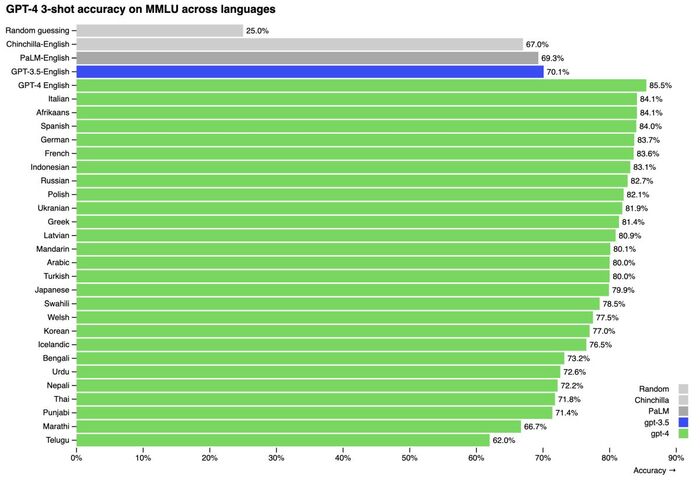
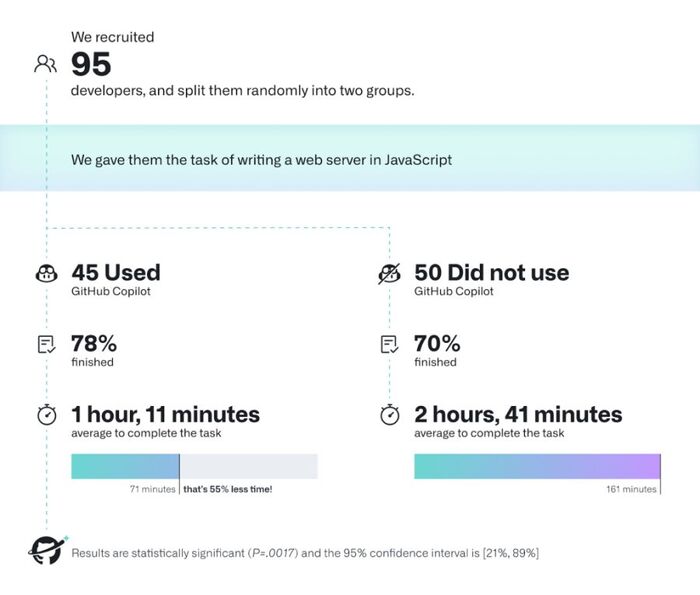
Илон Маск против OpenAI: Полная история от любви до ненависти
В 2015 Маск убеждал Сэма Альтмана не жалеть никаких денег на найм топовых спецов, чтобы спасти человечество от зловредного супер-ИИ от Google – а сейчас он публично обзывает его «лжецом, жуликом и мошенником». В 2018 Маск «оценивал шансы OpenAI на успех как нулевые» – а теперь он хочет выкупить компанию за $97 млрд. В этом лонгриде мы детально разберемся: как так вышло, что Илон сначала помог запустить самую революционную ИИ-компанию современности, а потом стал главным ее хейтером?

Это гостевая статья от Леонида Хоменко – продуктового аналитика и автора канала «Трагедия общин» про искусственный интеллект и современные технологии. Я в данном случае выступаю как редактор, который изо всех сил пытался сделать этот интереснейший лонгрид чуть более вместимым в разумные рамки объема. =)
За последний год OpenAI неоднократно находилась в гуще захватывающих событий: скандал с неудавшимся увольнением Сэма Альтмана, уход из компании Ильи Суцкевера, а также несколько судебных исков от Илона Маска. Последняя новость – это не только (и не столько) очередное проявление эксцентричности Маска, на самом деле там довольно интересная историческая подоплека! В этой статье мы как раз хотим рассказать вам о том, как создавалась компания OpenAI, и что происходило у нее внутри до прорыва с ChatGPT и прихода всеобщей популярности.
А история там кроется не хуже, чем в фильме «Оппенгеймер»: сюжет создания OpenAI – это практически готовый оскароносный сценарий. Только если ядерные технологии от повседневной жизни находятся далеко, то ChatGPT лично я использую буквально каждый день.

В общем, ставки в этой истории такие же высокие, а исход от них мы все в итоге рискуем ощутить на себе
Откуда идут истоки этого текста: судебный иск Илона Маска к OpenAI
Почти ровно 12 месяцев назад, 29 февраля 2024 года, Илон Маск подал в суд на OpenAI и лично на Сэма Альтмана (CEO компании). Вот как на это отреагировала команда OpenAI (выдержка из их официального пресс-релиза, который они выложили на сайте в течение недели после этого иска):
Нам грустно, что до такого дошло с человеком, которым мы глубоко восхищались. Он вдохновил нас целиться выше, а потом сказал, что у нас ничего не получится, основал прямого конкурента и подал на нас в суд, когда мы начали добиваться значимого прогресса в реализации миссии без него.
Greg Brockman, Ilya Sutskever, John Schulman, Sam Altman, Wojciech Zaremba, OpenAI
Прочитав такое, сразу возникает желание задать вопрос: «Илон, ну не *удак ли ты?». И на этот вопрос можно с уверенностью ответить… Ладно, не будем спойлерить – предоставим вам право решать в итоге самостоятельно. Наше дело здесь – это подробно рассказать вам всю историю их непростых взаимоотношений, а также пертурбаций, которые претерпела сама компания с момента основания.
В чем была суть иска Илона Маска (опустим пока подробности, что он уже успел несколько раз ее поменять – отзывая старые иски и переподавая новые)? Он обвинил OpenAI в отходе от изначальной некоммерческой миссии, чрезмерной зависимости от Microsoft, и фокусе на максимизации прибыли.

В соцсети Х Маск, скажем так, тоже не сильно стеснялся в выражениях
Маск утверждает, что сделки с Microsoft заставили OpenAI вести себя как монополист: компания заняла 70% рынка генеративного ИИ, душит конкуренцию, запрещая партнерам инвестировать в другие компании, и предлагает сотрудникам нерыночные зарплаты.
Это противоречит изначальной миссии, в которую Маск, как он пишет, искренне верил: первыми создать дружелюбный AGI (универсальный искусственный интеллект, способный соображать не хуже человека) и сделать так, чтобы пользу от него получили все в мире, а не только избранные. Маск был не просто сооснователем, а источником финансов и основным драйвером амбиций, которые в итоге помогли компании построить самый быстрорастущий продукт в истории.
В ноябре 2024 года в рамках судебного разбирательства был опубликован архив переписки сооснователей OpenAI с момента незадолго до создания компании в 2015 и до 2019 года, когда их пути окончательно разошлись. Переписка довольно фрагментарная – с большими пробелами во времени и отсутствием того, что обсуждалось лично или через другие каналы.
Чтобы сделать историю более цельной, мы добавим контекст из других источников и постараемся пересказать именно самое интересное. Цитаты местами будут переводиться не дословно – поэтому тем, кто прямо хочет погрузиться в эту историю по-хардкору, советуем ознакомиться и с оригиналами (там много интересного). Ну и смело пишите, если увидите, что в переводе писем где-то сильно накосячено.
Основная цель этого лонгрида – показать, что у каждого участника этой истории есть своя правда.
Часть 1. Предыстория появления OpenAI на свет
Цепочка опубликованных писем начинается с, казалось бы, довольно странного питча Сэма Альтмана:
Я много размышлял и думаю, что человечество невозможно остановить от разработки ИИ. Так что, если это всё равно произойдет, то было бы неплохо, чтобы кто-то другой, а не Google, сделал это первым.
Как думаешь, было бы хорошей идеей запустить что-то вроде «Манхэттенского проекта» для ИИ? Мне кажется, мы могли бы привлечь немало топовых специалистов в индустрии. Можно было бы структурировать проект так, чтобы технология принадлежала всему миру (через некоммерческую структуру), но при этом разработчики получали бы конкурентные зарплаты на уровне стартапов.
Sam Altman to Elon Musk - May 25, 2015 9:10 PM
Почему Сэм с ходу пишет Илону Маску про Google, и зачем их вообще останавливать? Спокойно, ща мы всё объясним!
2014: DeepMind и его последующая покупка Гуглом
Илон Маск всегда был известен своим интересом к экзистенциальным рискам. Например, миссия SpaceX в том и заключается, чтобы спасти нашу цивилизацию от возможного вымирания на Земле. Ведь жить на двух планетах лучше (ну, по крайней мере, безопаснее), чем на одной.
В 2012 году Маск встретился с Демисом Хассабисом из компании DeepMind и заинтересовался темой искусственного интеллекта. Хассабис в разговоре набросил, что ИИ – это один из серьезнейших рисков. Колонизация Марса будет иметь смысл, только если сверхразумные машины не последуют за людьми и не уничтожат их и там. Маск идеей проникся и вложил $5 млн в DeepMind, чтобы быть ближе к фронтиру отрасли.

Теперь уже Нобелевский лауреат, руководитель всего AI в Google, и почетный рыцарь – сир Демис Хассабис
Вскоре стало ясно, что крупные компании активно переманивают самых талантливых исследователей из сферы глубокого обучения (Deep Learning). Например, Джеффри Хинтон изначально хотел пойти в Baidu за $12 млн, но устроил аукцион, на котором Google выкупил его за $44 млн.

Один из отцов-основателей ИИ, учитель Ильи Суцкевера, и Нобелевский лауреат с индексом Хирша под 188 – Джеффри Хинтон
Несмотря на это «искушение большим баблом», Демис Хассабис хотел, чтобы компания DeepMind оставалась независимой – именно для того, чтобы гарантировать, что ее AI-технологии не превратятся в итоге в нечто опасное. Но когда Ларри Пейдж (сооснователь Google) увидел, как DeepMind научили нейросеть играть в Atari, он тоже резко захотел «вписаться в перспективную тему».
В 2014 году Google предложил $650 млн за покупку DeepMind. И Демис всё же согласился, но настоял на двух условиях: никакого оружия и военного применения для технологии; и она должна контролироваться независимым советом по этике. (Спойлер: в феврале 2025 года Гугл в итоге отказался от обещания не использовать ИИ для создания оружия – не зря, выходит, Хассабис на эту тему переживал!)
2015: Маск ссорится с «гугловскими» из-за рисков ИИ
Тут надо сделать оговорку, что Илон Маск и Ларри Пейдж к этому моменту дружили уже больше 10 лет. Но, как говорит сам Маск, именно резкие различия в их взглядах на безопасность ИИ стали в итоге причиной того, что они прекратили общаться.

Илон Маск пристально смотрит на создателя гугловского PageRank-алгоритма (и, заодно, лучшего в мире печатного станка денег) Ларри Пейджа
Пиком стал их публичный спор на дне рождения Маска в июне 2015. Пейдж верил, что развитие технологий приведет к слиянию людей и машин (и что это хорошо). Дескать, разные формы интеллекта будут бороться за ресурсы, и в итоге победит сильнейший, и будет дальше жить-поживать. А вот Маску идея о том, что человечество может не войти в эту категорию «сильнейших», казалась не очень веселой.
Я часто разговаривал с ним допоздна о безопасности ИИ, Ларри недостаточно серьезно относился к этой проблеме. Его позиция была интересной: он стремился к созданию цифрового сверхинтеллекта – можно сказать, цифрового божества. Когда я однажды поднял вопрос о том, как мы собираемся обеспечить безопасность человечества, он обвинил меня в «видовом расизме» (Speciesism): по сути, в том, что я зря отдаю предпочтение людям в потенциальном конфликте с цифровыми формами жизни будущего.
Илон Маск в интервью Такеру Карлсону, апрель 2023
Ну и, видимо, на этом дружба закончилась. Повздорили из-за роботов (да еще и, пока что, воображаемых)! Напомню, что это не какая-то научная фантастика, а вполне реальные люди – причем, руководящие крупнейшими мировыми корпорациями. Можете еще послушать вот этот короткий отрывок из интервью Маска Лексу Фридману, где он описывает свои идеологические разногласия с Ларри Пейджем:
В общем, у Илона Маска уже тогда были поводы, скажем так, не сильно доверять намерениям Гугла в отношении ИИ. Так что, после продажи DeepMind этому же самому Гуглу, Демису Хассабису не составило большого труда уговорить Маска присоединиться к специальному совету по этике – который должен был следить за тем, чтобы технология не была использована во зло. Первое заседание совета прошло в августе 2015-го и… чуда не произошло.
Ларри Пейдж вместе с Сергеем Брином и Эриком Шмидтом заявили, что все эти ваши опасения по поводу AI преувеличены. В итоге Маск посчитал такой совет фикцией, и на этом его участие в DeepMind благополучно закончилось. Ну а Google просто распустил этот этический совет, заменив его корпоративными гайдлайнами – что только усилило беспокойство Хассабиса. В 2017 году он с другими основателями даже попытался отделиться, но Гугл просто повысил им зарплаты + накинул опционов, и ребята остались. Как говорится, «баблу даже не нужно побеждать зло, если они играют за одну команду!»
2015: Создание OpenAI
А теперь давайте еще раз посмотрим на таймлайн происходящего по датам:
Январь 2014 – Google покупает DeepMind
Май 2015 – первое письмо Альтмана Маску с питчем «Манхэттенского AI-проекта»
Июнь 2015 – Маск посрался с Ларри Пейджем на ДР
Июль 2015 – Сэм, Илон и Грег Брокман «завербовали» в команду Илью Суцкевера
Август 2015 – провальное заседание комитета по этике DeepMind
Ноябрь 2015 – официальное создание компании OpenAI
В таком контексте, питч из первого письма Сэма Альтмана про «злой Гугл уже вот-вот создаст злой AI!» выглядит идеально. Он отправлен ровно в тот момент, когда у Илона уже зрело недовольство происходящим и желание что-то сделать с этим, но еще не было конкретного плана.
А Сэм как раз предлагает такой план: так как остановить Google невозможно, нужно его просто опередить! Если cобрать небольшую группу самых талантливых людей в отрасли, то можно первыми сделать сильный ИИ – и, при этом, поставить приоритет на использовании этой мега-технологии во благо всего мира.
Неудивительно, что миссия OpenAI (некоммерческой организации), сформулированная в декабре 2015, сейчас – 10 лет спустя – звучит крайне идеалистично:
OpenAI – это некоммерческая исследовательская компания. Наша главная цель – создать искусственный интеллект и сделать так, чтобы он принес максимальную пользу всему человечеству. Мы не обременены необходимостью получать прибыль, что дает нам уникальную свободу.
Мы можем полностью сосредоточиться на создании ИИ, который будет доступен для всех. Мы верим в демократизацию технологий и выступаем против концентрации такой мощной силы в руках избранных.
Наш путь непрост. Зарплаты у нас ниже, чем предлагают другие компании, а результат всего предприятия пока неясен. Но мы убеждены, что выбрали правильную цель и создали правильную структуру. Надеемся, что именно это привлечет к нам лучших специалистов в области.

Молоденькие Маск и Альтман во времена, когда они еще прекрасно общались между собой (2015 год)
Вообще, есть мнение, что OpenAI просто не смогли бы успешно запуститься без поддержки Маска. А он ее оказал именно из опасений, что Ларри Пейдж направит огромные ресурсы Google на создание сверхсильного искусственного интеллекта, не заботясь о его безопасности (тут будет уместно напомнить, что этой важной теме посвящен другой наш масштабный лонгрид).
Часть 2. С чем боролась свежевылупившаяся OpenAI: найм кадров и закуп железа
Почему роль Маска во всём этом была такой важной? Ответ простой: бабло! В ноябре 2015 Грег и Сэм обсуждали, сколько нужно денег, чтобы у OpenAI появился шанс тягаться «с большими парнями». Они планировали поднять $100 млн на грантах и донатах (плюс-минус на такую сумму у Альтмана в итоге и получилось выйти, включая, судя по всему, грант на $30 млн от Open Philanthropy).
Но Илон убедил их целиться в сумму в 10 раз больше, чтобы не выглядеть безнадежно отстающими по сравнению с конскими расходами Google и Facebook. Причем Маск, который к этому моменту уже успел закинуть в общую кубышку $45 млн «из своих» (поверх собранного Сэмом), пообещал добить недостающую сумму после сборов от других инвесторов до миллиарда долларов самолично.
И практически сразу стало понятно, почему он был прав. Об этом – как раз в этой части.
Фокус на найме: большие деньги для больших талантов
Главной стратегией OpenAI с самого начала было собрать небольшую, но сильную команду мотивированных специалистов, чтобы догнать Google. А чтобы привлекать лучших из лучших – нужна и компенсация соответствующая! И пока обсуждались зарплаты и плюшки, Сэм Альтман пришел с новостью, что DeepMind планирует перекупить всю команду OpenAI крупными контр-офферами. Они явно стремились устранить конкурента на ранней стадии, буквально загоняя людей в угол на проходящей в декабре 2015-го конфе NIPS.
Маск отреагировал на это однозначно:
Давайте повышать з/п. Выбор прост: либо мы привлекаем лучших в мире специалистов, либо DeepMind оставит нас позади. Я поддержу любые меры для найма топовых людей.
Elon Musk to Greg Brockman, (cc: Sam Altman) - Feb 22, 2016 12:09 AM
Из писем видно, как сложно было ребятам – они ворвались отстающими на рынок, где бигтех уже вел настоящую охоту за топовыми ресерчерами. Но на стороне OpenAI было, так сказать, «моральное превосходство»: ведь они как бы противостояли огромным бездушным корпорациям, пытаясь создать сильный ИИ на благо всего человечества. Вот здесь Маск дает понять Илье Суцкеверу (ключевому «мозгу» команды), что если они все вместе не поднапрягутся и не выдадут результат – то завалить Гугл будет просто нереально:
Вероятность того, что DeepMind создаст настоящий искусственный разум, растет с каждым годом. Через 2–3 года она, скорее всего, не превысит 50%, но, вероятно, преодолеет 10%. С учетом их ресурсов, это не кажется мне безумным.
В любом случае, лучше переоценивать, чем недооценивать конкурентов.
Нам важно добиться значимого результата в следующие 6–9 месяцев, чтобы показать, что мы действительно способны на многое. Это не обязательно должен быть прорыв мирового уровня, но достаточно значимый успех, чтобы ключевые таланты по всему миру обратили на нас внимание.
Elon Musk to Ilya Sutskever, (cc: Greg Brockman, Sam Altman) - Feb 19, 2016 12:05 AM

Вот он, Илья Суцкевер – признанное светило всея машин лёрнинга (в те времена он еще не щеголял своей фирменной прической)
Open Source как препятствие к конкуренции с тех-гигантами
В этой же парадигме «борьбы со злым Гуглом», кстати, логично рассматривать и изменение отношения OpenAI к концепции открытого кода – которая, казалось бы, намертво закреплена в самом названии этой некоммерческой организации. А вот, поди ж ты: уже начиная с модели GPT-3 (2020 год), OpenAI перестали выкладывать свои наработки в опенсорс. Так вот, на самом деле, предпосылки к этому обсуждались внутри команды задолго до этого момента.
По мере того, как мы приближаемся к созданию ИИ, имеет смысл начинать быть менее открытыми. «Open» в OpenAI означает, что все должны пользоваться плодами ИИ после его создания, но совершенно нормально не делиться результатами исследований, хотя это определенно правильная стратегия в краткосрочной перспективе для целей рекрутинга.
Ilya Sutskever to: Elon Musk, Sam Altman, Greg Brockman - Jan 2, 2016 9:06 AM
На письмо выше Илон Маск ответил пять минут спустя коротко, но однозначно: «Ага». Это уже потом, восемь лет спустя, у него случились массовые подгорания в Твиттере из-за «слишком закрытой» политики OpenAI; а вот в 2016-м Маск почему-то был совсем не против такой стратегии – не делиться самыми прорывными результатами исследований, чтобы их в итоге не скопировали «нехорошие люди».

Хотя, возможно, Илону тут не нравится чисто семантическое несоответствие названия компании и ее фактического поведения…
Смена парадигмы: не только люди, но и железки
Как видим из дискуссии в предыдущей паре разделов, в 2016 году команда OpenAI в основном ломала голову на тему «как бы нам привлечь на свою сторону самых няш-умняш индустрии» – и на это денег еще плюс-минус, как будто бы, хватало.
Но год спустя ситуация внезапно и резко поменялась: в марте 2017-го ребята осознали, что создание AGI потребует огромных вычислительных ресурсов. Ведь объем компьюта, используемого другими бигтех-компаниями для прорывных результатов, увеличивался по траектории «примерно в 10 раз каждый год». А это уже миллиарды долларов в год, которые просто так собрать некоммерческому проекту, казалось, попросту невозможно. OpenAI отчаянно нуждалась в новом плане!

Google Brain на конфе NIPS (декабрь 2017) хвастаются своим дорогущим железом на TPUv2
В чем тут дело, нам поможет объяснить Илья Суцкевер. Судя по разным интервью, Илья был именно тем человеком, кто одним из первых поверил в Scaling – мощное масштабирование способностей ИИ чисто за счет наращивания вычислительных мощностей – еще до того, как это полностью подтвердилось на практике:
Мы обычно считаем, что проблемы сложны, если умные люди долго не могут их решить. Однако последние пять лет показали, что самые ранние и простые идеи об искусственном интеллекте – нейронные сети – были верны с самого начала. А чтобы они заработали, нам просто не хватало современного железа.
Если наши компьютеры слишком медленные, никакая гениальность ученых не поможет достичь AGI. Достаточно быстрые компьютеры – необходимый элемент, и все прошлые неудачи были вызваны тем, что оборудование оказалось недостаточно мощным для AGI.
Ilya Sutskever to: Elon Musk, Greg Brockman - Jul 12, 2017 1:36 PM
Отдельно Илья поясняет важное технологическое изменение, которое довольно сильно поменяло «правила игры» для разработчиков ИИ. До этого супердорогие суперкомпьютеры условного Гугла не столько ускоряли самые масштабные эксперименты по обучению нейросеток, сколько позволяли проводить много разных тестов поменьше. А это для ресерчеров не так важно, как скорость проведения больших экспериментов: для прогресса нужно как можно быстрее получить данные предыдущего «фронтирного» эксперимента, чтобы задизайнить и провести следующий, и так далее…
Раньше большой вычислительный кластер мог помочь тебе делать больше разных экспериментов, но он не позволял выполнить один большой эксперимент более быстро. По этой причине, небольшая независимая лаборатория могла конкурировать с Google – ведь его единственным конкурентным преимуществом была возможность одновременного проведения множества мелких экспериментов (это так себе преимущество).
Но сейчас стало возможным комбинировать сотни GPU (графических вычислительных чипов) и CPU (центральных процессоров), чтобы запускать эксперименты в 100 раз масштабнее за то же время. В результате, для сохранения конкурентоспособности любой AI-лаборатории теперь необходим минимальный вычислительный кластер в 10–100 раз больше, чем раньше.
Ilya Sutskever to: Greg Brockman, [redacted], Elon Musk - Jun 12, 2017 10:39 PM
Эпоха параллельных вычислений: больше, быстрее, ДОРОЖЕ
Ну, то есть, вы поняли? Одними топовыми ML-спецами теперь сыт не будешь – пришла эра параллельных вычислений, теперь надо еще расчехлять свинью-копилку для закупки графических чипов в промышленных масштабах! Кстати, именно эта смена технологического тренда в 2016–2017 и стала ранним звоночком-предзнаменованием к тому, что в 2024-м Nvidia станет крупнейшей и успешнейшей компанией в мире.

Дженсен Хуанг из Nvidia лично донатит в OpenAI в 2016 году один из первых серверов DGX-1 – кластера GPU, специально предназначенного для использования в тренировке ИИ (а принимает дар кто? лично батя Илон Маск!)
Позволим себе супер-краткий экскурс в историю о том, как графические чипы буквально всего лишь за пять лет стремительным домкратом ворвались в мир машинного обучения и обеспечили себе там доминирующее положение:
До 2012: Использование GPU вместо CPU при тренировке нейросетей было редкостью.
2012–2014: Большинство результатов достигалось на 1–8 GPU мощностью 1–2 терафлопс.
2014–2016: Крупные тренировочные запуски на 10–100 GPU мощностью 5–10 терафлопс. Однако, видеокарты всё еще неэффективно взаимодействовали друг с другом.
2016–2017: Появились новые чипы (TPU) и много разных подходов, улучшающих параллелизацию вычислений – вот тут-то и наступил расцвет «видеокарточного машинлёрнинга»!
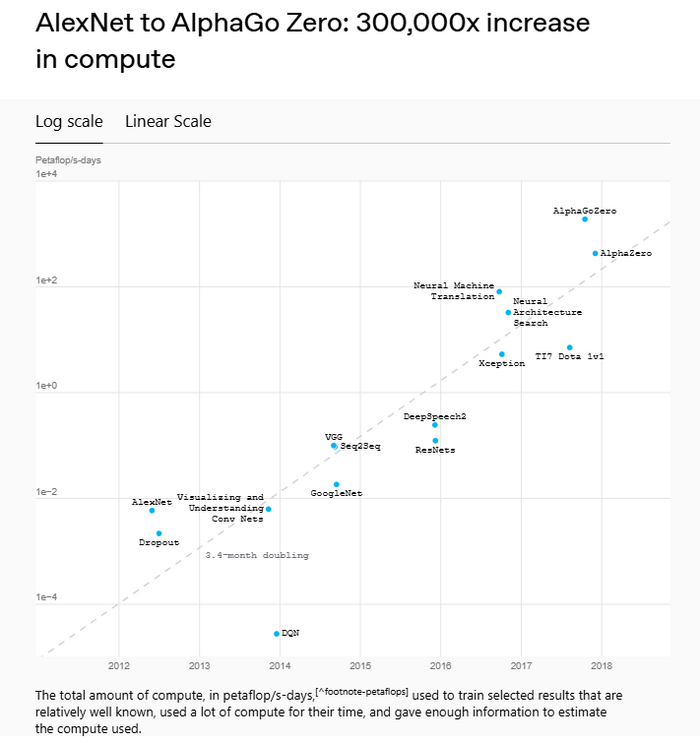
Количество вычислительных ресурсов, необходимых для обучения прорывных нейросеток: удвоение происходит каждые три с половиной месяца [статья про компьют из старого блога OpenAI]
Каждые несколько лет GPU становятся мощнее. Чем лучше видеокарты, тем больше операций в секунду можно выполнять за ту же цену. Рост мощности компьюта в 10 раз в год происходит потому, что ресерчеры постоянно находят способы использовать больше чипов параллельно. И это открывает возможность практически безлимитно заваливать любую проблему деньгами. Илья Суцкевер пишет про это:
Главное – это размер и скорость наших экспериментов. Раньше даже крупный кластер не сильно ускорял проведение большого эксперимента. Но теперь можно проводить их в 100 раз быстрее.
Если у нас будет достаточно оборудования, чтобы проводить эксперименты за 7–10 дней, то история показывает, что всё остальное приложится. Это как в фундаментальной физике: ученые быстро выяснят как устроена Вселенная, если у них будет достаточно большой коллайдер.
Есть основания считать, что оборудование для глубокого обучения будет ускоряться в 10 раз ежегодно на протяжении ближайших 4–5 лет. Это ускорение произойдет не из-за уменьшения размеров транзисторов или увеличения тактовой частоты; оно произойдет потому, что, как и мозг, нейронные сети обладают внутренним параллелизмом, и уже создается новое высокопараллельное оборудование, чтобы использовать этот потенциал.
Ilya Sutskever to: Elon Musk, Greg Brockman - Jul 12, 2017 1:36 PM
В общем, в переводе с нёрдовского языка на бизнесовый, письмо выше на самом деле пытается сказать «ДАЙТЕ НАМ БОЛЬШЕ ДЕНЯК НА ЧИПЫ!». Оглядываясь назад, Илья примерно в два раза переоценил масштаб происходящих процессов, но всё равно хорошо предсказал сам тренд.
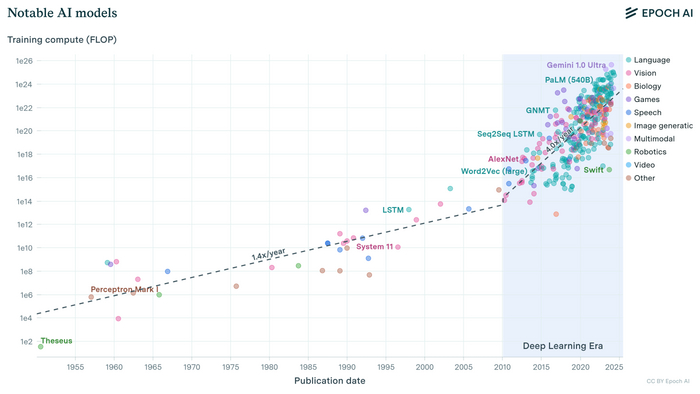
На масштабе используемых в ML-индустрии мощностей наглядно виден момент перехода к параллельным вычислениям (график из статьи Compute Trends Across Three Eras of Machine Learning)
2017: Не железом единым, или алгоритмический сюрприз от Google
Ровно месяцем ранее от последнего процитированного выше письма Суцкевера, 12 июня 2017 года, Google выпустили культовую 15-страничную научную статью Attention is All You Need, которая произвела настоящую революцию в мире глубокого обучения. Именно там была впервые представлена архитектура трансформеров!
Помните, как раньше Сири или Google-ассистент не могли поддерживать длительные разговоры, так как быстро теряли контекст? Главная тому причина – ограничение разных архитектур того времени: модель могла быть либо умной, либо обладать хорошей памятью (упрощаю, но суть примерно такая):
Свёрточные сети хорошо масштабируются, но теряют общую картину в длинных цепочках;
Рекуррентные сети лучше обрабатывают длинные цепочки, но плохо масштабируются.
Разные модели лучше подходили для разных задач: например, для перевода текста важны длинные цепочки, а для генерации изображений – внимание к локальным деталям, которое лучше у крупных моделей. Так вот, трансформеры убрали эту проблему в принципе, сохранив лучшее от обеих архитектур. Они умеют и видеть общую картину, и при этом отлично масштабируются!
Именно появление архитектуры трансформера, по сути, открыло эпоху больших языковых моделей (LLM), и привело в итоге к появлению того самого ChatGPT, который прогремел на весь мир в 2022-м. (Про историю создания и про принципы работы ChatGPT у нас, кстати, есть отдельная большая статья.)
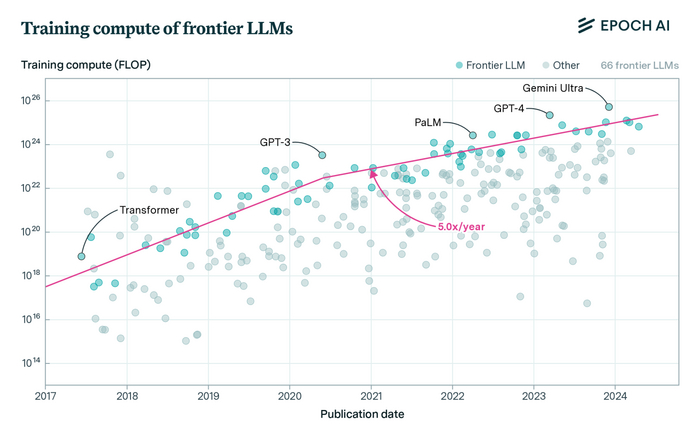
Начиная с появления трансформера, объем компьюта на тренировку передовых языковых нейросетей начал увеличиваться в 10 раз каждый год (!), и только с 2020-го тренд чуть замедлился до «жалких» х5 в год
Получается, в середине 2017 года два фактора идеально наложились друг на друга. Во-первых, новые GPU-чипы позволили мощно наращивать объем компьюта, который можно использовать при тренировке огромных моделей. А во-вторых, новаторская архитектура трансформера, собственно, позволила эти самые гигантские модели успешно обучать – чтобы при этом у них не разбегалось в разные стороны внимание, и они могли «держать в голове» необходимый контекст.
В общем, ситуация вышла такая: Железо нужное на рынке есть. Алгоритмы нужные придумали. Чего не хватает? Огромной кучи денег, чтобы всё это закупить и запустить! Вот об этом мы сейчас и поговорим…
К сожалению, третья (заключительная) часть материала не влезает на Пикабу из-за ограничений по объему. Окончание можно прочитать по ссылке на полную версию статьи вот здесь.