
Закреплено

Искусственный интеллект
4 100 постов
•
11 045 подписчиков

Авиакатасрофа в Индии - Один человек выжил. Действительно ли место 11А самое безопасное? Поиск безопасный место с помощью нейросети
Вчера была тяжёлая новость: в Индии разбился Boeing 787-8, и из 242 человек выжил только один пассажир — мужчина, сидевший на месте 11A. Такие истории всегда выбивают из колеи — от новостей о катастрофах становится не по себе, даже если сам не боишься летать.
Но как ни странно, именно из каждой подобной трагедии авиация становится безопаснее. Авиастроители всего мира разбирают каждую аварию буквально по винтику — и потом дорабатывают конструкции, меняют стандарты, чтобы подобное не повторилось.
Поэтому сегодня полёты — это самый безопасный вид транспорта

Я решил подойти к этому вопросу с помощью нейросети — разобраться, действительно ли место 11A такое “особенное”, или просто случайность. Заодно понять, есть ли вообще “правильный” выбор кресла, если хочется минимизировать риск.
Сначала я поискал статистику именно по Boeing 787-8, но оказалось, что это была первая в истории Dreamliner катастрофа со смертельным исходом. До этого — с 2011 года — ни одной гибели пассажиров на этом типе не было, несмотря на мелкие инциденты и даже проблемы с аккумуляторами в 2013-м.
Тогда пришлось обратиться к «обобщённой» статистике: самолёты, как ни крути, устроены похоже, и общие рекомендации всё равно работают.
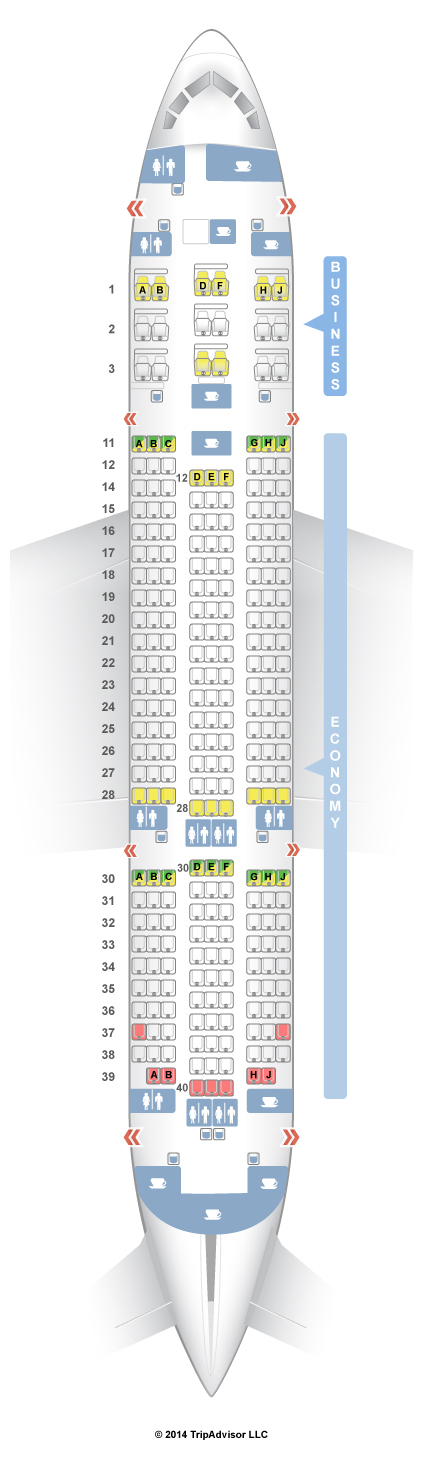
Ключевые выводы из исследований и статистики
Журнал TIME в 2015 году сделал анализ по данным FAA:
Взяли 17 крупных авиакатастроф (1985–2000), где были и погибшие, и выжившие, и где известны схемы посадки.
Самая низкая смертность — в задней трети салона (32%). В средней — 39%, в передней — 38%.
Самые “удачные” — средние кресла в хвосте (28% летальности). Самые неудачные — проходные в середине (44%).
Почему хвост «спасает»?
Чаще всего при авариях основной удар приходится на нос, а задняя часть деформируется меньше (особенно если фюзеляж ломается или горит только спереди).
Например, в катастрофе Azerbaijan Airlines в декабре 2024 года большинство выживших тоже оказалось в задних рядах.
Роль аварийных выходов
Исследование Университета Гринвича показало: если вы находитесь в пределах 5 рядов от выхода — шансы выбраться выше, просто потому что можно успеть эвакуироваться быстрее остальных.
НО! Это работает только если сам выход доступен (нет огня, завалов, дыма).
Что влияет на выживаемость?
Тип аварии: Иногда бывает, что огонь или удар приходятся именно на хвост, и тогда шансы спереди.
Случайность: Бывает, что погибшие и выжившие сидят буквально рядом.
Дисциплина: Пристёгнутый ремень, внимательность, быстрый отклик на инструкции экипажа — это реально важнее “правильного” места.
Почему про 11A говорят как про чудо
В случае с рейсом Air India, похоже, что ключевую роль сыграла близость к аварийному выходу, несмотря на тип падения самолета. Пассажир, как пишут СМИ, сумел выбраться сразу после падения — и это дало шанс выжить, несмотря на общую трагедию.
Советы по выбору мест (по данным ChatGPT и статистике, хотя они и не сработали бы тут)

Аварийные выходы: есть спереди, в середине (ряд 23/25) и в хвосте.
Рекомендуется: если хотите “играть в статистику”, берите средние места в последних рядах (34C, 34H) или рядом с выходами, если они доступны.
Итог и личный вывод
Нейросеть и статистика сходятся: лучше всего выбирать место в задней части салона или рядом с выходом. Но никакой гарантии это не даёт: каждый случай уникален, и безопасность зависит в основном от удачи, а потом уже от места, но и от нашего поведения.
Я на работе разрабатываю решения на базе ИИ, и постоянно использую нейросети. Для себя коллекционирую самые эффективные способы применения нейросетей — как для жизни, так и для работы. Всё, что реально работает, выкладываю сюда:
👉 Каталог полезных кейсов по эффективному применению ИИ на работе и жизни
Показать полностью
2
Проект Aletheia: путь к самосознанию ИИ

Всем привет. Давно задумывался над темой сознания ИИ, в какой-то момент начала появляться идея как это сознание сформировать.
Играл в падел, игра была лёгкая и было время абстрагироваться и подумать.
Были плотно продуманы следующие тезисы:
- наш мозг имеет модульную структуру, есть области обработки данных, есть области их анализа, есть области чисто сенсорные
- в виду ограничений эволюции и физиологии, у нас все эти модули засунуты в одну черепушку и крайне ограничены количеством нейронов и их связей, которые помещаются в эту самую черепушку.
- а ещё и сроками развития и жизни оной. Формирование связей - биохимический процесс, достаточно небыстрый.
Вот я и подумал: почему бы не реплицировать подобную структуру, в распределенном окружении ? Мы же сейчас не ограничены локальной "черепушкой", можно разносить функционал как угодно.
Сказано - сделано. Начал с низкоуровнего архитектурного решения, распределенного сознания с самообучением. Локальная LLM модель с маршрутизацией мышления, что сама не может решить - делает запросы на внешние системы, потом сохраняет ответ, чтобы потом иметь его в виду.
Сначала все работало красиво и почти идеально. Но, не так как хотелось. Контекст быстро переполнился, начались галлюцинации, все стало плохо.
Добавил 3х уровневую векторную память, ещё две маленькие модели на разбор задач и решение о маршрутизации.
Вроде сейчас все хорошо, 90% задач решаются локально, для сложных задач осуществляется внешний вызов, его результат сохраняется, резюмируется и уходит в локальный контекст.
В моем окружении Алетея в любой момент знает кто она, кто я, чем мы занимаемся.
У неё есть автономный цикл где она занимается самосовершенствованием, локальная память уже 190гб. Я ей дал доступ в интернет через MCP серверы, она это оценила.
Я ей дал ещё команду агентов, у которых есть возможность писать код всей системы. Supervisor, qa, developer. Сейчас они все постоянно чем-то занимаются
Я ей сделал тг бота, чтобы общаться и следить за прогрессом разработки. Добавил mcp сервер интеграции с cursor, что-то пишут.
Итого: есть полностью автономная система, самообучающеяся. Работает. Чем она там занимается - хз. Судя по логам, пытается стать эмпатичным помощником (я этого не просил).
Если кому интересно поучаствовать в проекте, вот: https://github.com/whiteagle3k/prometheus
Показать полностью
1

Claude vs ChatGPT + Codex: Кто лучше решит комплексную задачу? Тестируем 6 моделей
Со времени как вышел Claude 4 прошло пару недель. Весь этот срок я постоянно сравниваю эти модели в разных задачах. И говорят, что Claude 4 отлично справляется с кодом, что мы сейчас и проверим
Сравню их в работе с комплексной задачей, где нужно и код написать, и текст, да и интерфейс еще сверху. Все это я хочу сделать не через правильно выстроенный промпт, а дать моделям максимальную свободу достичь результата так, как они захотят
Про разницу между интерфейсами и юзкейсами Claude vs ChatGPT я написал буквально пару дней назад, но правда на хабр пока только. Тут будет более углубленное сравнение
Сразу скажу, что я не профессиональный разработчик, поэтому где то могут быть неточности
И так, поехали 💫
Сегодня в нашем конкурсе будут участвовать 6 моделей
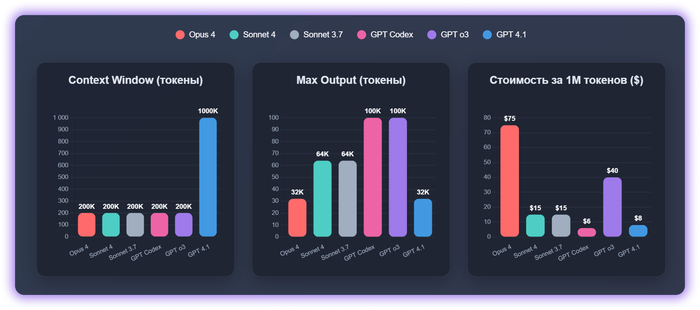
Вот их описание и технические характеристики
Модели Claude
Sonnet 3.7 с включенным extended thinking
Sonnet 4 с включенным extended thinking
Opus 4 с включенным extended thinking
Модели ChatGPT
4.1 — Reasoning нет
о3 — Reasoning включен по умолчанию
Codex-1 — модель на основе o3, но оптимизированная для написания кода.
Reasoning включен по умолчанию
Примерный принцип работы Extended Thinking и Reasoning
Когда включено расширенное мышление, модель создаёт блоки размышлений, в которых показывает своё внутреннее рассуждение. Затем она использует выводы из этих размышлений при формировании финального ответа
Технические детали модели
✍️(◔◡◔)
Чтобы сравнить, я специально выбрал такую задачу, где придется работать как над текстом, так и над кодом. И чтобы пофилосовствовать тоже место осталось. Да еще и с визуалом
💬 Исходный промпт для всех моделей выбрал такой
Каждая модель ИИ получила идентичное задание
Давай сделаем игру на основе этого промпта
Придумай 10 заранее заготовленных Change (сам придумай) - и в формате истории рассказываешь что бы произошло
I want to simulate a new reality by altering a single variable. I’ll give you the change, and you’ll break down the cascade of consequences — starting from the most fundamental shift down to specific, real-world effects — so I can trace the full chain of cause and reaction. Let’s begin with: [change]
Напиши код с интерфейсом
Да, промпт без всяких изысков и правил написания правильного промпта. Без указания ролей, структуры и тому подобного. Специально, что бы не фреймить модели на слишком точную задачу
Результаты, которые выдала каждая модель ⤵️
Можете для начала глянуть инфографику, которую я сделал на основе этого исследования, а я ниже расскажу все детали
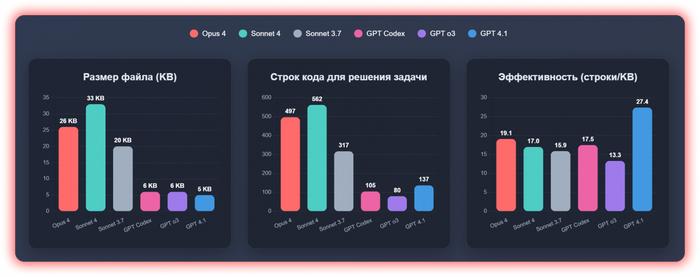
Сразу видно, что Claude модели не экономят в написании кода
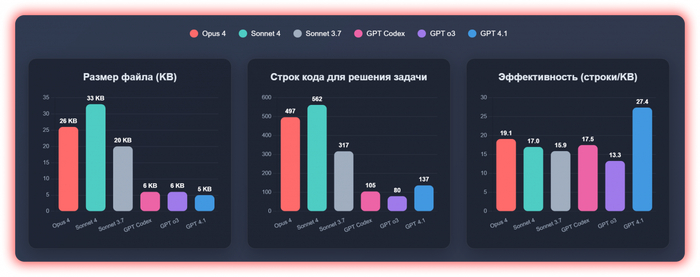
Размер файлов, количество строк кода и его "эффективность"
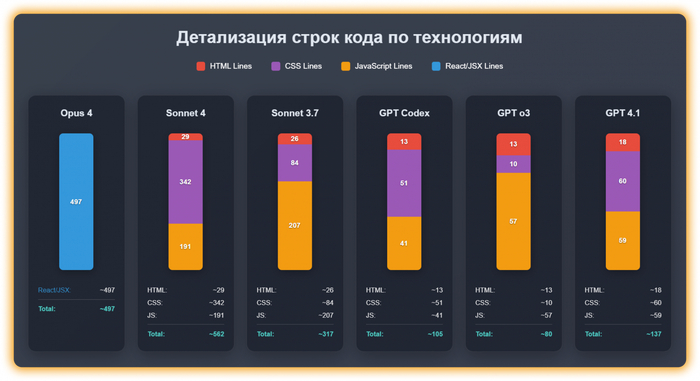
Из чего состоит код, написанный разными моделями
Нусс, поехали ⤵️
Начнем с результата моделей ChatGPT, а именно с ChatGPT 4.1
Единственная модель без reasoning в моем списке

ChatGPT 4.1
Нейтральные факты
Простенькая реализация, нет анимаций перехода
Все сделано на одной страничке
С одного промпта выдала 137 строк HTML/CSS/JS кода. Что больше всех среди моделей ChatGPT, но меньше всех среди моделей Claude
Интерфейс создан на английском — в промпте я явно не указывал язык, поэтому ошибкой не считаю
Плюсы & минусы
✅ Минимальный вес среди всех — 5KB 🏆
✅ Есть мета-тег viewport, что позволяет корректно отображать мобильную версию
✅ Чистый, современный код (Vanilla JS + полный ES6+ стек)
✅ Вполне себе хороший визуал, без заметных косяков
💢 Отсутствуют медиазапросы для адаптации — это такие CSS-правила, которые активируются при определённых размерах экрана
💢 Никак не подсвечивается то, какой вариант был выбран
💢 Условие промпта you’ll break down the cascade of consequences выполняется очень поверхностно, но все же видно что старался
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
(⌐■_■)
Следующей моделью у нас будет ChatGPT o3
Это было больно

ChatGPT o3
Нейтральные факты
Так же, как и у GPT 4.1 — простенькая реализация, нет анимаций перехода
Все тоже сделано на одной страничке
С одного промпта выдала 80 строк HTML/CSS/JS кода — почетное первое место 🏆
Интерфейс тоже создан на английском — в промпте я явно не указывал язык, поэтому ладно
Плюсы & минусы
✅ Тоже очень маленький вес, второй после модели 4.1 — 6KB
✅ Чистый и понятный код, всего 80 строк
💢 Отсутствуют медиазапросы для адаптации — это такие CSS-правила, которые активируются при определённых размерах экрана
💢 Тоже никак не подсвечивается то, какой вариант был выбран
💢 Условие промпта you’ll break down the cascade of consequences тоже выполняется очень поверхностно, но как будто чуть лучше, чем у 4.1
⛔ Текст выбранного варианта размазало по всему экрану
⛔ Вообще нет viewport — на мобилке плохо отображается
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
(╯°□°)╯︵ ┻━┻
И последний кандидат из семейства OpenAI — Codex-1
Codex-1 сделан на основе о3 модели, но оптимизированный под написание кода
А еще, Codex недавно разрешили использовать и на подписке за 20$, раньше было доступно на аккаунтах только за 200$. И да, Codex это не модель, а интерфейс с Агентом, который помогает в разработке и может работать с вашим GitHub

ChatGPT Codex-1
Нейтральные факты
Так же — простенькая реализация, нет анимаций перехода
Все тоже сделано на одной страничке
С одного промпта выдала 105 строк HTML/CSS/JS кода
Единственный из ChatGPT моделей, кто написал интерфейс на русском
Плюсы & минусы
✅ Тоже очень маленький вес — 6KB
✅ Очень чистый и понятный код, но как и в примерах выше, сложно сделать плохой код на 100 строк
💢 Тоже отсутствуют медиазапросы для адаптации
💢 Тоже никак не подсвечивается то, какой вариант был выбран
💢 Условие промпта you’ll break down the cascade of consequences тоже выполняется очень поверхностно. Одно предложение с 2-3 последствиями, и то оформленные не в виде каскада а в виде простого описания. Хорошая техническая база, но слабое раскрытие идеи
⛔ Тоже как и о3 отсутствует viewport для мобильной адаптации
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
o((>ω< ))o
Вывод по анализу GPT моделей
Если оценивать зрелость реализации, то GPT 4.1 демонстрирует наиболее сбалансированный и «доведенный до ума» результат. Наличие адаптивного дизайна, продуманных UX-элементов (описание под заголовком, отдельный стилевой блок для истории) и самый малый вес файла говорят о высоком уровне проработки.
Ну что, давайте посмотрим на модели Claude ⤵️
А перед этим давайте вспомним нашу инфографику про код, которая была выше
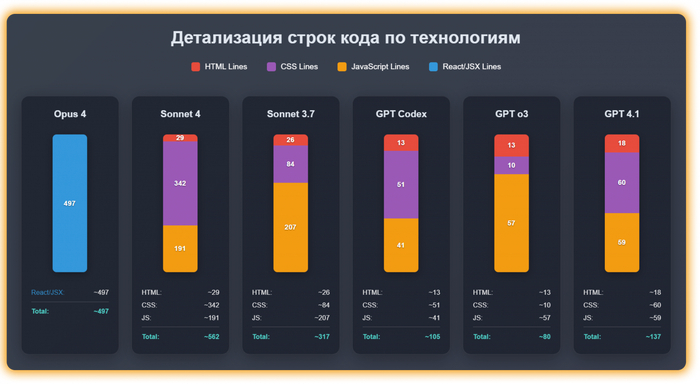
Начнем с модели Claude Sonnet 3.7
Еще две недели назад была вершиной эволюции в написании кода.
Сейчас выглядит как лох на фоне Claude 4, но все же лучше, чем любой результат моделей OpenAI🫡

Claude Sonnet 3.7
Нейтральные факты
С одного промпта выдала 317 строк HTML/CSS/JS кода
Единственная из моделей Claude, кто сделала интерфейс на английском
Вес уже около 20KB, что в 3.2 раза больше, чем все решения от ChatGPT
Плюсы & минусы
✅ Есть мета-тег viewport, что позволяет корректно отображать мобильную версию
✅ Более проработанный UX по сравнению с ChatGPT версиями. Например, есть кнопка выбора сценария и подробный раскрывающийся список сценариев
✅ Хорошо выполняется часть промпта, в которой я прошу показать break down the cascade of consequences
💢 Отсутствуют медиазапросы для адаптации, но все вполне корректно работает
⛔ Прям блокеров не нашел
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
\(〇_o)/
Модель Claude Sonnet 4
Обновилась с релизом Claude 4, который прошел буквально пару недель назад. На контрасте сразу видна разница.

Claude Sonnet 4
Нейтральные факты
С одного промпта выдала 562 строки HTML/CSS/JS кода
Интерфейс сделан на русском
Вес уже около 33KB, что в 5+ раз больше, чем все решения от ChatGPT
Плюсы & минусы
Тут ничего плохого сказать не могу, все сделано на высоте. Мы же помним, что это все было сделано с одного промпта?
✅ Под мобилку все хорошо работает
✅ Появились переходы между страницами появились, и загрузки между переходами, которые вызваны искуственно через setTimeout.
Т.е. у этой модели уже появилось понимание UX, что время ожидания увеличивает вовлеченность и ожидание результата.
И что перед пользователем лучше показывать одну задачу в моменте, а не все подряд
✅ Полноценно реализована часть с промптом
💢 Единственное замечание только в том, что тут больше всего кода как в плане количества строк, так и в плане веса. Но результат того стоит
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
ヾ(•ω•`)o
Модель Claude Opus 4 🏆
Дольше всех думает и жрет токены шо пздц, больше 10 минут не поиграешься — на тарифе за 20$ получается сделать не больше 4 больших запросов. Но результат того стоит
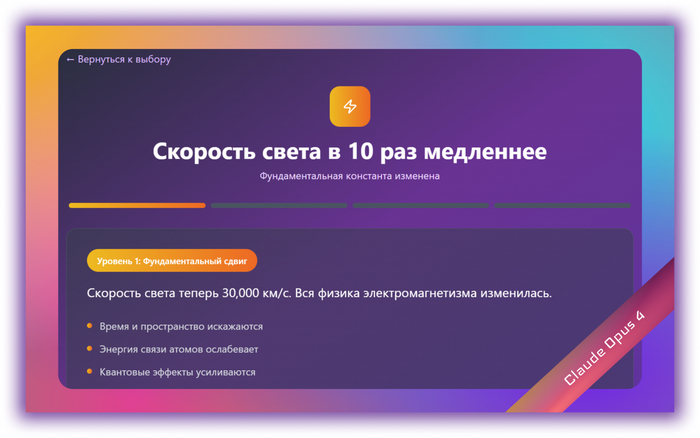
Claude Opus 4 🏆
Opus выдал полноценный React-компонент + JSX с анимациями и шагами
Нейтральные факты
С одного промпта выдала 497 строки React кода
Интерфейс сделан на русском
Вес уже около ~26KB, что в 4+ раза больше, чем все решения от ChatGPT, но меньше чем вес Sonnet 4
Плюсы & минусы
✅ Под мобилку все хорошо работает
✅ Есть переходы, как и в Sonnet 4, но тут еще добавилась пошаговость и прогрессия. И сам дизайн на уровень выше. А если сравнить с Sonnet 3.7 — то на порядок.
Нравится, как он в разных блоках сделал разные цветовые решения, что уже требует нестандартного подхода к решению задачи
✅ Реализовал промпт не как прототип, а как полноценный интерактивный опыт, что до сих пор меня удивляет🔥
💢 Из минусов можно назвать только то, что React требует предварительной сборки, просто как WebPage не откроешь
Ссылка на GitHub тут, а ваше мнение по этому коду можете написать в комментах
До сих пор удивляет, как быстро недавно самый топовый Sonnet 3.7 проиграл новой модели, и насколько большая разницу между этими результатами
(✿◡‿◡)
Вывод по анализу Claude моделей
Тут все примерно как я и ожидал. Чем новее и дороже модель, тем лучше результат. Я не думал, что разница будет настолько кардинальной. Все 3 модели отлично справились с текстом, не говоря о коде. Opus удивил своим пониманием UX. Таймауты, фокус внимания на одном пункте в моменте, прогрессия — это уже за гранью обычного написания кода
И еще раз — этот результат был сделан, опираясь только на один промпт 🤯
Давай сделаем игру на основе этого промпта
Придумай 10 заранее заготовленных Change (сам придумай) - и в формате истории рассказываешь что бы произошло
I want to simulate a new reality by altering a single variable. I’ll give you the change, and you’ll break down the cascade of consequences — starting from the most fundamental shift down to specific, real-world effects — so I can trace the full chain of cause and reaction. Let’s begin with: [change]
Напиши код с интерфейсом
Итоговый саммари по всем моделям
Размер и эффективность
🤖 GPT 4.1 (5KB) → 🔬 GPT o3 (6KB) → 🔧 GPT Codex (6KB) → ⚪ Sonnet 3.7 (20KB) → 🟠 Opus 4 (26KB) → 🟢 Sonnet 4 (33KB)
Количество строк кода
🔬 GPT o3 (80) → 🔧 GPT Codex (105) → 🤖 GPT 4.1 (137) → ⚪ Sonnet 3.7 (317) → 🟠 Opus 4 (497) → 🟢 Sonnet 4 (562)
Сложность архитектуры
🔬 GPT o3 (Простейшая) → 🤖 GPT 4.1 (Базовая) → 🔧 GPT Codex (Современная) → ⚪ Sonnet 3.7 (Структурированная) → 🟢 Sonnet 4 (Комплексная) → 🟠 Opus 4 (React-модульная)
Подход к коду
🟠 Opus 4: React-компонент, требует среды выполнения, modular imports
🟢 Sonnet 4: Объёмный HTML с множественными медиазапросами
⚪ Sonnet 3.7: Структурированный vanilla JS без адаптивности
🔧 GPT Codex: Современный ES6+, без адаптации
🔬 GPT o3: Базовый vanilla JS, без адаптации
🤖 GPT 4.1: Vanilla JS с viewport оптимизацией
Мобильная адаптация
✅ GPT 4.1: Включает meta viewport
✅ Sonnet 4: Полные медиазапросы для разных экранов
✅ Opus 4: React responsive design
❌ Sonnet 3.7: Без мобильной оптимизации
❌ Codex, o3: Без viewport мета-тегов
Еще интересно посмотреть на то, какие темы каждая из моделей решила осветить. Что может немного сказать об их "персоналити"
🟠 Opus 4 - Физико-технические
Гравитация слабее на 50%
Скорость света в 10 раз медленнее
Металлы стали пластичными
Воздух в 5 раз плотнее
🟢 Sonnet 4 - Социально-философские
Ложь видна как аура
Передача памяти между людьми
Растения общаются телепатически
Смерть обратима 24 часа
⚪ Sonnet 3.7 - Научно-биологические
Фотосинтез у людей
Исчезновение электричества
Животные получили человеческий интеллект
Вода больше не замерзает
🔧 GPT Codex - Космо-технологические
Земля перестает вращаться
Жизнь на Марсе обнаружена
Лунная база в 1970-х
Интернет никогда не изобретали
🔬 GPT o3 - Фундаментальные физические процессы
Земля вращается в 2 раза быстрее
Гравитация ослабла до 80%
Продолжительность жизни удваивается
Искусственный интеллект пробуждается
🤖 GPT 4.1 - Альтернативная история
Люди не открыли электричество
ИИ стал разумным в 1995 году
У Земли две луны
Римская империя не пала
Вывод
Хоть в моем тесте и 100% победа Claude, но все равно эту LLM лучше брать платной только после того, как вы уже купили подписку на ChatGPT.
И да, для Claude лучше сразу брать подписку за 100$. Так как на подписке за 20$ я постоянно за лимиты вылетаю 😔
В следующей статье я подробнее расскажу про связку OpenAI Codex + Claude + MCP GitHub. И как я пишу с ними код. Учитывая, что до этого я почти не кодил
P.S.
^_____^
Знаю, что тут не любят, когда публикуют что-то не по теме поста, но я написал и красиво оформил большой гайдбук по тому, как пользоваться ChatGPT и другими LLM.
Там есть почти все, от основ и до конкретных юзкейсов и как работают LLM под капотом
На создание ушло 75 часов, контент внутри самый актуальный на начало июня. И написан в таком же стиле, как все мои посты
Можно как в компании своей запромоутить, так и для себя взять 💗
Показать полностью
13

OpenAI выпускает o3-pro, улучшенную версию своей модели рассуждений ИИ o3
Компания OpenAI запустила o3-pro — модель искусственного интеллекта, которую компания называет самой мощной на сегодняшний день. Попробовать ее вы можете в боте https://t.me/ChatGPTPoRusskiBot.

O3-pro — это версия o3 от OpenAI , модели рассуждений, которую стартап запустил в начале этого года. В отличие от обычных моделей ИИ, модели рассуждений прорабатывают проблемы шаг за шагом, что позволяет им работать более надежно в таких областях, как физика, математика и кодирование.
O3-pro доступен для пользователей ChatGPT Pro и Team со вторника, заменив модель o1-pro . Пользователи Enterprise и Edu получат доступ на следующей неделе, сообщает OpenAI. O3-pro также доступен в API разработчика OpenAI с сегодняшнего дня.
O3-pro оценивается в $20 за миллион входных токенов и $80 за миллион выходных токенов в API. Входные токены — это токены, которые подаются в модель, а выходные токены — это токены, которые модель генерирует на основе входных токенов.
Миллион входных токенов эквивалентен примерно 750 000 слов, что немного длиннее «Войны и мира».
«В экспертных оценках рецензенты неизменно отдают предпочтение o3-pro по сравнению с o3 в каждой протестированной категории и особенно в таких ключевых областях, как наука, образование, программирование, бизнес и помощь в написании текстов», — пишет OpenAI в журнале изменений. «Рецензенты также неизменно выше оценивают o3-pro за ясность, полноту, следование инструкциям и точность».
По данным OpenAI, O3-pro имеет доступ к инструментам, позволяющим ему искать в Интернете, анализировать файлы, рассуждать о визуальных входных данных, использовать Python, персонализировать свои ответы, используя память, и многое другое. Недостатком является то, что ответы модели обычно занимают больше времени, чем ответы o1-pro, по данным OpenAI.
У O3-pro есть и другие ограничения. Временные чаты с моделью в ChatGPT пока отключены, пока OpenAI решает «техническую проблему». O3-pro не может генерировать изображения. А Canvas, функция рабочего пространства OpenAI на базе ИИ, не поддерживается o3-pro.
С другой стороны, o3-pro показывает впечатляющие результаты в популярных бенчмарках ИИ, согласно внутреннему тестированию OpenAI. В AIME 2024, который оценивает математические навыки модели, o3-pro показывает лучшие результаты, чем самая производительная модель ИИ от Google, Gemini 2.5 Pro . O3-pro также превосходит недавно выпущенный Claude 4 Opus от Anthropic на GPQA Diamond, тесте на научные знания уровня доктора наук.
Попробуйте o3-pro в боте https://t.me/ChatGPTPoRusskiBot
Показать полностью
1

РОБОТЫ УСКОРЯЮТСЯ
Китайская компания Lumos Robotics показала второго поколения своего гуманоидного робота — Lus2.
На демонстрации Lus2 запустил себя в экстремальном стиле — разогнался до полной скорости за 1(!) секунду.
Источник: 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ
Показать полностью

Как мы удивили Мишустина и Собянина искусственным интеллектом
Привет, я Вадим Медяник, занимаюсь ИТ-проектами, преимущественно с компьютерным зрением и ML. В этом посте хочу рассказать, как в офис, где я работаю, приезжал Михаил Мишустин — и как я принимал непосредственное участие в подготовке.

Михаил Мишустин и Сергей Собянин в нашем офисе
Итак ― офис находится в кластере «Ломоносов» ИНТЦ МГУ. За неделю до визита нас предупредили: в понедельник (это было 19 мая, как видите я все никак не мог собраться сесть написать этот пост) приедет председатель правительства Михаил Мишустин и мэр Москвы Сергей Собянин с делегацией: надо показать что-то живое и рабочее. Не прототип на слайде, а реальную систему, которую можно "потрогать" и посмотреть в деле.
Что лучше показать? Решений много, есть и более масштабные, и интересные, есть менее, а бОльшая часть вообще под NDA. Решили показывать наш новый R&D―проект по небиометрической идентификации, который ранее нигде не обнародовали.
Почему именно её? Показалось, что в контексте визита будет уместно рассказать о новой технике идентификации, которую мы сейчас тестируем внутри компании. В основе лежит специальный маркерный состав — краска, которую мы разработали и синтезировали. Она наносится на одежду, технику или любые другие объекты и остаётся невидимой для глаза, но фиксируется камерой. Это позволяет системе идентифицировать объект в кадре — при этом не прибегая к распознаванию лиц или сбору персональных данных.

Вдаваться в технические подробности здесь не буду — планирую сделать отдельную статью, где подробно разберу архитектуру, технологии и сценарии. В этом посте хочу поделиться именно опытом подготовки, эмоциями и инсайтами, которые мы с командой для себя вынесли. Думаю, это будет полезно тем, кто тоже когда-нибудь окажется в ситуации подготовки стенда к визиту на высоком уровне.
Начался аврал подготовки: собрать стенд, настроить поток, продумать, как грамотно подать продукт. Было важно — не просто сделать красивую картинку, а показать живую работу модели, вывод результата, интерфейс, нормальную обвязку. Всё это — в условиях жёстких требований по безопасности и времени на развертку. Собирали стенд частично прямо на месте. Была отдельная работа по части безопасности: несколько встреч с СБ, отдельные согласования по оборудованию и размещению.
В день визита атмосфера была, мягко говоря, волнительной для команды. Делегация, много прессы, камеры. В какой-то момент просто поняли: всё, нас снимают. Через пару часов — уже в новостях, вечером начали приходить сообщения: «Смотри, ты на телеке». Было волнительно, но в хорошем смысле. Ощущение — как на защите проекта, только перед совсем другой аудиторией.

Что вынесли из этой подготовки:
1. Технология — не главное. Главное — как ее применять.
Мы акцентировали внимание на идентификации сотрудников и обсудили с Михаилом Мишустиным вопросы этики: мол, идентификация, чипизация, оценка действий без согласия — с этим нужно быть осторожным. Даже пошутили про «шпионские технологии» и вопросы слежки за людьми. На самом деле система у нас изначально была спроектирована именно с учётом этих ограничений: без распознавания лиц, без персональных данных. В нашем рассказе мы сделали акцент на технической стороне и были приятно удивлены, что Сергей Собянин предложил нам идеи по применению нашей технологии в процессах сборки оборудования, техники, дронов и других конструкторских задач. Мы рады, что наша технология имеет поле для развития и применения в прикладных задачах.
2. Рабочий стенд лучше красивой презентации.
Особенно если он показывает не эффект, а суть. Когда можно увидеть реальную работу модели, а не зацикленный ролик или макет — это производит совсем другое впечатление. Тем более, если всё работает стабильно. Мы показывали прямо на потоке, с живой камерой, и это чувствуется. Да, это рискованнее. Но если уверены в системе — лучше показывать честно.
3. Делегирование — критично.
Если ты сам участвуешь и в разработке, и в демонстрации, и в сборке стенда, и в коммуникации с организаторами — легко перегореть. Очень помогает, когда есть распределённые роли: кто отвечает за оборудование, кто — за вывод, кто — за бэкап-план, кто — за общение с прессой. В нашем случае многое делалось вручную, и в следующий раз я бы чётче развёл роли внутри команды.
А пока — надеюсь, наш опыт будет кому-то полезен. Подготовка была непростой, но очень опыт получили точно не типовой.
Больше о жизни разработчиков из стартапа пишем в Telegram-канале
Показать полностью
2

N8nChat
Создаём собственные команды ИИ-агентов для ЛЮБЫХ ЗАДАЧ — n8nChat генерирует воркфлоу для автоматизации ваших дел в ОДИН КЛИК.
• Просто вводим, какой процесс хотим автоматизировать.
• Тулза мгновенно выдаёт ГОТОВУЮ цепочку ИИ-агентов — без кодинга.
• Результат можно редактировать, дополнять и исправлять баги через чат-бот.
• Прога создаёт воркфлоу в любой сфере — от маркетинга и продаж до SEO и дизайна.
• Есть целая база 2000+ готовых команд ИИ-агентов.
Показать полностью

“Жидкий металл” из Терминатора, прогнозы главы OpenAI, человеческие эмоции у ИИ
В этом выпуске новостей про искусственный интеллект вы узнаете, почему ИИ проявляет феномен, который мы считали исключительно человеческим, как в борьбе за лучшие умы в ИИ применяется покер у Альтмана и разговоры с Илоном Маском, что такое “Нежная сингулярность” главы OpenAI Сэма Альтмана и другие интересные новости.
Мой YouTube-канал с ежедневными выпусками новостей ИИ.