
Кино вино и домино
3 поста
3 поста
26 постов
35 постов
13 постов
9 постов
11 постов
Смотался по своим личным делам в Хошимин. Он же Сайгон. Прошлый раз «не проездом» я там был еще до ковида, 3000 лет назад.
Полеты внутри Юго-восточной Азии, особенно без багажа, относительно дешевые. К примеру, на 26.02 Bamboo Airways Бангкок – Хошимин стоит 74$ без багажа.
Важно: берите куртку и маску. Не знаю, кто так настраивает обдув, но в самолете было как-то очень свежо, и постоянно кто-то чихал.
Виза: для граждан РФ для целей туризма виза во Вьетнам и Таиланд не нужна, штамп по прилету на 45 дней. В Камбоджу виза нужна, оформляется или заранее через сайт электронной визы Камбоджи (картой Мир оплатить нельзя), или на месте за наличку. Бронирование отеля не требуется, обратный билет не нужен, но билет могут и спросить, и тогда придется покупать прямо на месте.
Что поменялось в Хошимине, а что нет.
Там по прежнему и летом тепло, но сыро, и зимой тепло, но, обычно, сухо. Хотя, по меркам РФ, зимой там «кошмар как жарко», летом «как тут люди то живут». Нормально живут, 2-3 литра воды, лучше минеральной или подсоленной, каждый день, мазать нос и уши кремом хотя бы 10, лучше 50, следить за собой, быть осторожным, менять носки на сухие, есть креветки. Креветки, действительно очень хорошие.
Таможня в аэропорту SGN (Tan Son Nhat International Airport), как и ранее, ничего особенного из себя не представляет. Лимит на ввоз денег без декларации – 5000$, с декларацией ввоз без ограничений (хотя, чемодан с наличкой не возил). Лимит на вывоз такой же, и не знаю, не проверял, что будет если поймают. Дальних знакомых ловили на вывозе налички, получили штраф в пару тысяч без конфискации. Как и раньше, можно за 7 или 8 тысяч донг (считайте 1:4, 30 рублей) доехать до центра города на обычном автобусе. За час. Или за 400к (1600 рублей) и 20 минут на такси. И еще к этим 400 у вас попросят 20 «за выезд», такие вот там странные таксисты.
Обменник BIDV и продажа сим карт находится почти сразу после таможни, мимо не пройдете. Симкарта стоит от 100 до 300 донгов, трафик – в зависимости от тарифа. В том числе и всамделишный анлим, без ограничений на раздачу с телефона. МТС бы от жадности удавился.
Гостиницы и прочие отели. Отелей меньше не стало, места есть. Искать и бронировать удобнее всего через Агоду. У ряда отелей есть «бронирование без предоплаты», что очень удобно. Ценник – разный, условия тоже разные.
Что в самом Хошимине.
Во первых, открылось, наконец-то, метро. Пока одна ветка, но выглядит пристойно, люди ездят. Во вторых, ввели штрафы за езду по тротуарам, езду не по ряду для байков, езду на красный свет, и еще всякое. Расставили везде камер, и беспощадно угнетают. Говорят, стало больше пробок – не заметил, но как-то поспокойнее стало, чтоли.
Вроде стало еще почище. Но увидеть ночью крысу, куда-то идущую по своим делам – легко.
Обменники. Курс по доллару был 25000 донгов за доллар, но он плавает туда-сюда. В турзоне курс чуть ниже – скажем, в Хошимине курс будет 25, в Дананге 25.5. Как и ранее, нужно брать доллары «новые» - образца 2013 года, и купюрами по 100$, на них курс 25 (плюс минус). Официальные курсы банков можно смотреть у них на сайтах, например BIDV - https://bidv.com.vn/en/ty-gia-ngoai-te сейчас покупает купюрами 50 и 100 – по 25,220, купюрами 1,2,5,10,20 – по 24,211. В банках вроде нет ограничений на старые \ новые купюры, но я не проверял. Доллары в оплату принимают в туристических ларьках с экскурсиями, но сдачу дадут донгами.
Из основных туристических мест:
Центральный рынок и фудкорт. Не заметил каких-то изменений – вещами торгуют, едой кормят. Есть нюанс – крой, поэтому за кроем «для РФ» лучше прогуляться на «русский рынок».
Центральный собор. По прежнему красив и хорош.
Башня Bitexco. Закрыли кафе, раньше можно было и кофе на 48+ этаже выпить.
Зоопарк. Хороший.
Старый рынок. Почему-то не пошел.
Дворец независимости. По прежнему красив, на крыше первого корпуса, как и раньше, есть холодильник с водой, и сувенирка.
Музей мира. В нем сделали новую экспозицию – тюрьмы в Республике Вьетнам. Это тот, который был такой весь демократический и южный. Экспозиция годная, с фото, макетами барака, и прочими милыми деталями. Гуманизм? Гуманизмом в детстве мальчики занимаются, а тот, кто говорит о гуманизме – шпион.
Впечатлительным дамам в ту часть, где показано (в том числе в спирту) влияние агента Оранж, лучше не ходить. Раньше еще и живой сотрудник был, выхвативший не очень счастливый билет.
Всякие храмы. Храм и храм, ничего особенного.
Дельта Меконга. Мне было лень, и я не поехал.
Тоннели Кучи (Cu Chi Tunnel). Вот там экспозиция здорово изменилась. Всякой побитой техники натащили, раньше (лень архив фото поднимать) был один ржавый танк без ничего, теперь все стащили на входную площадку. В наличии тот же танк, вертолет, джип, пушка, и самолет.
Есть стрельбище, где, за очень дорого, (60к донгов – 240 рублей за патрон!!) можно пострелять из убитого и прибитого к стойке АК, такого же убитого карабина, пистолета и пулемета. Был еще Гаранд, но больше нет. М16 нет, М14 нет, короче так себе.
В самой экспозиции добавили тоннелей, теперь их там метров 250, а не 50. Вентиляция и освещение внутри есть, всякие отвороты сделаны тупиковыми (я слазил и проверил), внутри добавлены экспозиции «подземный госпиталь». По теме стоит прочитать:
Данг Тхюи Чам. Дневник врача на войне
Ле Као Дай. Дневник вьетнамского врача (она же – На плато Тенгуен). Извините за ВК.
Есть еще «О медиках сражающегося Вьетнама», но я не читал.
Что еще скажу про тоннели. Это, хотя и расширенный под стандартного (читай – жирного) туриста и безопасный (свет, принудительная вентиляция, отделка стен, обязательное сопровождение гида) аттракцион, но он ничуть не легкий. И в одном бункере арматура торчит. Местами там нужно или гусиным шагом идти, или на 4 точках ползти. Метров 50 пройдите гусиным шагом, и ощутите свою слабость и ничтожность следующие два дня.
Совокупно, стало намного лучше, а с детьми (мальчиками) так вообще AS MAST.
Экскурсию все равно где брать, это сбор туристов на какую-то машину. С гидом, но гид будет английский. Русского гида не искал. Из отеля заберут, в отель отвезут. Самому ехать – ну не. Берите маску и куртку, кондиционеры в автобусах выставлены на режим мгновенной заморозки.
Во всякие краеведческие музеи, с бивнем мамонта, с прочим разным, не пошел.
Хотел еще сгонять в Дананг, но посмотрел прогноз погоды, и отказался. Что-то холодно зимой в Дананге, и, особенно, в горах. Весной, летом или осенью, главное чтобы не в циклон или муссон, гораздо лучше.
Из интересного. Забегал в один вьетнамский банк, встретил пару руссо туристо. Им кто-то сказал, что во Вьетнаме счета открывают всем подряд, даже влетевшим без рабочей визы, или хотя бы, евизы. Как они собирались, вообще не зная ни слова по английски, что-то объяснять персоналу банка, не понимаю. И нет, счет во Вьетнаме просто так теперь не откроют, а даже если и откроют, то пластик к нему получать можно очень не везде. Очень изменилась ситуация за 2022-2024.
Фотографий пока не будет.
Для ЛЛ: где же вы, настоящие послушные мужики с доходом от 500к рублей, и высоко квалифицированные низко оплачиваемые кадры.
Я чего не писал недели три? Прилетала ко мне погреть кости и вообще пожариться – HR с одной из работ. Так что я зависал, в излишествах и беспробудном алкоголизме. С меня компания, кабаки и прочие поездки на пляж и к тиграм, в их королевство. Есть тут такая локация.
И возник у меня с ней разговор, точнее начала она мне рассказывать, что в ее окружении, и окружении ее подруг, а там дамы уже за 30, и даже за 35, куда то, ну совершенно, пропали «нормальные мужики».
Я, конечно, попросил определить, что такое «нормальные».
Определения, конечно, не было. Полчаса наводящих вопросов, прочей стимуляции, готового результата все равно не дали.
Проще всего было с материальным положением – доход хотя бы 300к. Лучше 400к и выше. Надо сказать, что там не линейный HR, а что-то еще не HRD, но уже не девочка с обзвоном. Ее доход что-то под 300+ без премии. Москва. Можете сразу сказать, что я наврал, и такого не бывает.
С формулировкой остальных требований было хуже. Примерно никак. Потому что каждый раз в итоге последовательных упрощений вылезало два требования:
Чтобы нравился.
Чтобы делал, что ему говорят. То есть слушался.
То есть, любая попытка выборки статистики упирается, в первую очередь, сразу в два фильтра, которые не могут быть определены численно или качественно.
Если внешняя красота, еще как-то сводится к рост-вес-спортивность, то проблема возникает с вторым фильтром – вот не желают «настоящие мужики» на руководящих должностях, слушаться, и все тут.
В том числе поэтому она и во втором разводе – не выносят мужики долго сцен 'ты виноват в том, что я обиделась, потому что ты не делал, как я хочу'. Не те.
Где-то тут схема и ломается.
В мужском коллективе в среднем чаще (хотя я могу и врать - исследований и цифр у меня нет, тем более для РФ) нормально работает распределение ролей - лидер, заместитель, линейные работники. Это не мешает иногда заму пытаться подставить босса, или заказать его, или пойти через голову.
Но все же начальник скорее заберёт с собой на повышение хорошего зама.
В женском коллективе все не так. В женском коллективе, скорее всего, будет только один лидер, и все остальные. Чтобы остальные не бросали вызов боссу.
Женщина, скорее, не потащит женщину подчиненного. Но может потащить толкового подчиненного. Но вряд ли будет рекомендовать толкового подчиненного.
Возможно поэтому, чем выше позиция в управлении, тем меньше женщин. За, опять же, исключениями типа Маргарет Тетчер, Дианы Спенсер , Ангелы Меркель, Барбары Микульски, и прочих Мадлен Олбрайт, Викторий Нуланд, и, конечно, Эльвира Набиуллина. Исключения есть. Но все равно, на 2024 - доля женщин в бундестаге - 35,3 процента.
Почему так?
ВАЖНО! Ниже идет глубокомысленное ковыряние в носу, не опирающееся на какие-то статистические данные и исследования!
Существует понятие «технологического уклада», сейчас вроде как шестой. Первый – прядильные машины, второй – паропанк, железо и уголь, третий – дизельпанк, нефть и сталь.
Четвертый – массовое производство на конвейерах, пятый – ракеты, спутники, атом и космос.
Шестой – нанотехнологии, чтобы это не значило.
На 1,2,и даже 3 техноукладе людей никто не считал. Прогресс медицины за 19 век, с мытьем рук, чистой водой, асептикой и антисептикой был таков, что население стало резко расти везде.
Где-то раньше, где-то позже. Широко известный труд «Скромное предложение, имеющее целью не допустить, чтобы дети бедняков в Ирландии были в тягость своим родителям или своей родине, и, напротив, сделать их полезными для общества» - 1729 год.
Менее известный, Положение рабочего класса в Англии – 1845.
Еще менее известный, Берви В. В. Положение рабочего класса в России: Наблюдения и исслед. Н. Флеровский. - Санкт-Петербург: Н.П. Поляков,1869, - [6], II, 494 с., 1 л. карт. – 1869.
Замечу, вопреки мнению некоторых тут аффтаров, что борьба рабочего класса за свои права началась где-то за тысячу лет до образования СССР, с 1215 года и хартии вольностей от Иоанна Безземельного. Он же принц Джон из Айвенго и прочих Робин Гудов.
The Noble and Holy Order of the Knights of Labor – 1869 год.
American Federation of Labor – 1881
Western Federation of Miners - 1893
Confédération générale du travail - 1895
Industrial Workers of the World – 1905
После первой мировой в Европе оказалось, что люди очень даже могут кончиться, и что после войны надо что-то делать с сотнями тысяч инвалидов с всех сторон. В СССР, ввиду сочетания малоземелья, 90-95% крестьянства, и массы других проблем, необходимость заниматься ростом населения скорее проигнорировали. После второй мировой, когда нужны были одновременно ракеты, бомбардировщики, нюки и ПВО – игнорировать необходимость роста населения не смог даже СССР. Кто-то должен проектировать, строить и клепать заклепки.
Отсюда, в том числе, возник ряд программ, как сейчас бы сказали «для молодой семьи и вообще семьи» - и жилищная программа, и образование, и прочая.
Возник конфликт в социуме, потому что:
В левом углу ринга оказалась патриархальная модель. Не будем забывать, что до 60х – в СССР преобладает сельское, а не городское население.
Есть муж, есть за ним жена "как за каменной стеной". Вдобавок к каменной стене прилагается "а что ты хотела?", приготовленный к приходу мужа с работу ужин и выстроенные его встречать дети и "если муж сказал, на рыбалку, значит, на рыбалку".
В правом углу ринга оказались реалии СССР, в котором примерно всю дорогу мужчин не хватало, потому что регулярно что-то происходило, что их прореживало сильно лучше, чем женщин. То есть женщину вынь и положь к станку, иначе работать некому. С прочно сидящей в массово еще крестьянских головах патриархальной моделью это стыковалось никак.
По той же причине, что "на десять девчонок по статистике девять ребят", мы имеем изначальный взлет однополых семей из мамы и бабушки, и очень неравноправный вход на брачный рынок: парням компостируют мозг, что надо пройтись по базару, и никуда не торопиться, и вообще, наше дело не рожать, сунул, вынул - и бежать, а девкам, наоборот, что упустишь свое Щастье, неча тут ломаться, надо в загс бежать.
Добавим сюда и "девочки не знают математику" и "зачем учиться, все одно замуж выйдешь" от выпускниц программы: "Ума нет - иди в пед".
Получаем кашу в неокрепшем мозгу, бабушка говорит одно, мама (с папой, при наличии) - другое, в школе третье, по радио четвертое. Этот супчик вполне себе варился в мозгах и в 70-е, и в 80-е, о чем даже кино снимали, просто оно не сильно на слуху. До поры до времени все нивелировалось благостным застойным обществом, в котором, без дураков, уж если родился, то не пропадешь.
Тут влетают девяностые, с кучей западных фильмов из 80-х с их уже победившим феминизмом. А кроме фильмов, появляются мужички в поиске дешевой бесправной жены (которая при этом будет жить изрядно лучше, чем в мазер раша), см. Интердевочка, и появляются местные товарищи, которые куда как лучше все еще изрядно патриархальных девочек приспособлены к разборкам и теркам.
В неокрепшие умы влетает идея: "любой ценой замуж, свесить ноги и ничего не делать", которая в момент находит отражение в ящике и на радио. И проблема в том, что изнанку, которую в той же Интердевочке вполне показали, большинство не считывало. Равно как и иронические интонации в голосе консерваторской выпускницы Апиной в сокрушительном хите "Американ бой". 1990 год.
И. Некоторым удается. Именно что некоторым, но за счет того, что им весь квартал завидует, модель успеха поселяется в массовом бессознательном.
На загнивающем Западе от первых суфражисток до победившего классического (не путать с радикальным) феминизма прошла добрая сотня лет, в СССР/России на то же самое ушла пара поколений. В супчике, варящемся в мозгах, рождается ядерная смесь из патриархального "как за каменной стеной" и модернистского "мое мнение значит столько же", причем местами густо намазанное не менее патриархальным «Мужчина голова, а женщина шея. Куда шея повернет, туда голова и смотрит».
В мужских мозгах тоже начинает вариться супчик из "я глава семьи, как я сказал, так и будет" и "пусть жена работает, я ее что, содержать должен, что ли". Сюда накладывается и объективный факт, что содержать неработающую жену может, дай бог, 10% популяции (как и за кордоном, в общем-то), при этом неработающая жена настолько просаживает средний уровень дохода, что дважды подумаешь, насколько нужна эта постылая.
И имеем в популяции мало что не одну, а две, в целом, комплементарных модели: патриархальную и модернистскую, и их неработоспособный гибрид.
Отсюда и летят "убила лучшие годы", "я его содержала" и аналогичное с другой стороны. При этом комплементарные пары уходят с брачного рынка надолго, а порой и навсегда, и в инете ничего громко не пишут.
Перемножая все N-мерные матрицы выше, получаем пустую выборку из социума.
Человек с доходом выше 300-500к уже так или иначе будет работать не только техническим специалистом, а скорее всего будет занимать на 10-50% какую-то руководящую (административную) роль. Да, есть (в ИТ) наносеки сеньоры в разработке и не только, с доходом (с одной работы) до и чуть больше миллиона, но это уже или своя фирма и десяток подрядов, или именно на позициях сеньоров, с руководством проектом, но не РП в чистом виде, а играющий тренер. Всегда, без исключений, на таких позициях уже нужны лидерские качества, и управлять таким человеком сложно.
И при этом всегда приходится кооперироваться, что-то обсуждать, договариваться итд. Может, это воспитание такое, может в мужском коллективе с детства социальная модель предусматривает быстрое построение кооперативной модели работы, о чем я выше и писал. С обсуждениями и генерацией идей, и потом, в основном, соблюдения договоренностей. Конечно, бывает иначе – у меня в удаленной команде есть один очень умный, который делает порой совсем не то.
Поэтому Стандартные Шаблонные конструкции методы «надуться как мышь на крупу», «игнорировать» и «не говорить, на что обиделась», не просто не работают, а работают наоборот.
Один раз что-то обсудили и решили, два, а потом вопрос «вдруг ставший ненормальным мужик» может и ребром поставить. Потому что:
- Пап, а тяжело ли быть начальником?
- Нет сынок, это то же самое, что сидеть в бассейне с говном на горящем велосипеде, но он не едет потому что в говне. Вот у тебя из-за этого задницу печёт, во рту говно и выбраться из этого у тебя не получится, как бы ты сильно не крутил педали.
А все вокруг тыкают в тебя пальцем и кричат - вот он пид@рас, из-за которого всё плохо...
На следующей итерации от женщин, для которых нет нормальных мужиков (тм), будут извинения.
Но.
Не изменение поведения на «больше так не буду», а куда-то между «я тогда так не думала (и не собираюсь так думать в будущем)», и «ты недостаточно показал, что ..».
Интересно, что в корпоративной сфере будет корпоративный булшит про 'примем меры', но я про это уже писал.
Все, приехали.
Пустая выборка – мужики есть, но «не те», и «не такие».
Как, впрочем, и выборка «высококвалифицированные низкооплачиваемые кадры».
Есть, есть что-то общее в искренних страданиях HR – ов, которые не могут оценить реалии рынка в ИТ, и в страданиях тех же HR, что нет нормальных мужиков».
Модная концовка.
Сумбурно как-то получилось, конечно. Потому что в РФ, вопреки мнению из 1917, не два класса (пролетариат и буржуазия), а четыре.
Для ЛЛ: нудное про все сразу
Историческая справка
Алексей Алексеевич Епишев. Начальник главного политического управления Советской армии и Военно-морского флота (1962—1985).
Вместо предисловия
Ехал по своим делам поездом, обратил внимание на проверку колесных пар. Как и сто лет назад, работники идут вдоль состава и стучат по колесу – целое ли, и по узлу подшипников (буксе).
Часть 1. Сага о ЖД подшипниках.
В настоящее время в тележках для грузовых вагонов применяется два типа устройства буксового узла: цилиндрические роликовые подшипники в буксе в вагонах старого типа; конические роликовые кассетные подшипники с адаптером в так называемых инновационных вагонах с повышенной грузоподъёмностью
ЖД подшипник – очень простая вещь (нет). 2 тележки на вагон, 8 колес, 50-60 тонн вагона, и всего 7 – 7.5 тонн на подшипник.
Плюсы кассет известны:
Срок службы кассетного подшипника — 16 лет, комплект из двух подшипников, необходимый для оснащения одной колёсной пары, обходится примерно в 52 тыс. рублей.
Роликовый подшипник служит 3 года и не подлежит ремонту.
Пикабу
В то же время, кассетные подшипники дороже, отмечает издание: комплект из двух узлов для одной колесной пары стоит около 52 тыс. руб. против примерно 14 тыс. руб. у роликовых. Но за 16 лет эксплуатации кассетных подшипников роликовые придется поменять 5 раз, затраты только на их покупку составят 70 тыс. руб.
Перевод грузовых вагонов в РФ на кассетные подшипники займет 8-10 лет
Кассетные подшипники
В 2019 году заявляли:
"Все производители кассетных подшипников нацелены на долгосрочное развитие своих мощностей на территории нашей страны, для чего все они работают в направлении максимальной локализации производства", – утверждает Минтранс, уточняя, что существующий уровень локализации у Brenco, SKF – 85%, Timken – 40%.
Оказалось, что не все так хорошо, но теперь все хорошо:
Констатируем, что мы, что “ЕПК-Бренко” вышли на полную мощность, дефицита подшипников сегодня нет.
Но есть нюанс:
Операторы, использующие кассетные подшипники от иностранного производителя на условиях анонимности признаются, отечественный производитель на рынок вывел продукцию более доступную по цене, но пока она не соответствует запросам по качеству. В брак, со слов собеседника РЖД-Партнера, отправляют каждое второе изделие.
В прессе все хорошо, подшипники выпускаются. Подумаешь, немного брака, и пока нет информации о том, как будут работать импортозамещенные версии через 3-5 лет.
Часть 2. Сага про гражданскую авиацию.
В 2023 году было построено 9 (девять) гражданских и транспортных самолетов. Точнее, 8.5:
Суперджет-100 RRJ-95NEW-100 (бортовой № 97 021),
6 армейских Ил-76МД-90А,
Ил-96–400М (RA-96 103) – один опытный
Бе-200 для Алжира (7T-VPW). Отгружен заказчику 12 декабря 2024 года. Должен был быть отгружен еще в 2023.
Обещали еще 3 Ту-204\214, но так и не доделали.
В 2024 году было построено 0 (ноль) гражданских самолетов.
Теперь обещают сразу два новых Ту-214, но в октябре 2025:
Первые два самолета Ту-214 отправят в татарстанскую авиакомпанию «ЮВТ Аэро» в октябре 2025 года. Составлен маршрут перелетов и обучены пилоты, сообщил ТАСС гендиректор авиакомпании Петр Трубаев.
МС-21-310 – перенесен на 2026. Опытные экземпляры:
Иркут МС-21-310 73051 – идет отработка молниезащиты.
Иркут МС-21-310 73054 – летает, идет отработка противообледенительных процедур.
Иркут МС-21-310 73055 – с октября 2024 «находится в высокой степени готовности». Новое крыло, новая электрика.
Иркут МС-21-310 73056 - на испытаниях с PW1400G-JM. Летает.
Иркут МС-21-310 73057 /73361 - не летает с апреля 2024. Тот самый, с импортозамещенным крылом, с ПД-14, и с заменой кабельных трасс -
06.02.2025 В цехе окончательной сборки гражданской авиатехники Иркутского авиазавода (№277) на опытном самолёте МС-21-310 (бортовой номер 73057, заводской номер МС.0013) приступили к проверке функционирования систем под электрической нагрузкой. Об этом сообщает заводская газета «Иркутский авиастроитель».
В ноябре 2023 обещали:
От «Яковлева» выступил заместитель генерального директора по материально-техническому обеспечению, закупкам и логистике Олег Нестеров. Из его презентации следует, что первый полёт полностью импортозамещённого самолёта МС-21 планируется выполнить в 2024 году.
Первым полностью импортозамещённым бортом станет опытный экземпляр самолёта с бортовым номером 73057 (заводской МС.0013). Ранее самолёт имел регистрацию 73361. Крыло этой машины изготовлено из российских ПКМ, первоначальная силовая установка – два редукторных ТРДД PW1400G, сейчас на ИАЗ идёт его ремоторизация под двигатели ПД-14. Осенью 2022 года борт летал на сертификацию российского композитного крыла.
Ожидается, что снова в небо он поднимется в апреле 2024 года.
И, наконец, SSJ ПД-8. Неделю назад на завод самолетов торжественно отгрузили новые двигатели, ПД-8 поколения 3 (Если три, конечно). Прошлые два поколения, как клевещут очернители, не прошли тесты на летающей лаборатории, пришлось переделать. Эти пока работают.
26 декабря 2022 – тесты v1 на Ил-76ЛЛ
03.03.2024 тесты v2 ? Скромно пишут: Запланированная ранее на декабрь 2023 г. сертификация турбореактивного двигателя ПД-8 для самолетов семейства «Суперджет» и Бе-200 перенесена конец 2024 г.
28 ноября 2024 - тесты v3 на Ил-76ЛЛ
Тесты SSJ ПД-8 заявлены на март - апрель 2025, потом еще год сертификация и устранение дефектов.
В прессе все хорошо, сделаноунас (сайт ранее был забанен за накрутку просмотров) пишет что «вот, уже». Впрочем, они так же писали про российские процессоры, где производство оказалось на Тайване.
Часть 3. Импортозамещение в ИТ.
С импортозамещением в ИТ все еще интереснее, и хуже. Под термином «импортозамещение» понимается не своя разработка, а использование opensource, его «русификация» и «модернизация». И нескучные обои.
Рекламщики разных фирм каждый год обещают «убийцу VMware», «унижателя Oracle» и «почти SAP, только не работает».
Самый продвинутые рекламщики уже прикупили по рекламному блоку на Хабре, и пишут теперь там. За деньги в копроблоге – пишите что хотите. Не удивлюсь, если на Хабре уже стали выдавать не только «+5 .. 10 к каждой статье в копроблоге», но и право банить. Автослив кармы за неприятное в комментариях в копроблоге работает уже лет 5, может больше.
Стоит каждый раз начать разбираться, «что там придумали», как выясняется что король не просто голый, он еще и с отставанием в умственном развитии.
Почему так? Потому что:
в опенсорсе, собравшемся вокруг Столмана и его GNU Project еще с 1983 года, уже давно прогрессирует кризис.
Реддит: The Hidden Crisis in Open Source Development: A Call to Action (ссылка оттуда идет на статью только по подписке)
Medium (начало доступно)
The Silent Crisis in Open Source: When Maintainers Walk Away
Кризис комплексный:
Поколение Столмана, 1950-1980 годов рождения, как-то совмещало идеи «большие злые корпорации против свободного мира».
Новое поколение любит роскошь, плохо воспитано, насмехается над начальством, не уважает стариков, перечит родителям. И считает, что ему должны, в том числе должны написать нужный код, потому что ему надо.
Код стал сложным.
март 1994: Linux 1.0.0 - 176 250 строк кода.
январь 2025: Linux 6.13 - 39.8 млн. строк кода.
Из 40 млн строк 24 млн относятся к коду драйверов (например, код драйверов для GPU AMD занимает около 5 млн строк), а 4.4 миллиона специфичны для различных аппаратных архитектур (для поддержки архитектуры x86 используется примерно 500 тысяч строк).
При этом тестирование ядра ничуть не помогает с проблемами работы планировщика процессора (cpu scheduling), и с постоянно всплывающими проблемами безопасности. Может, кто-то вспомнит, как еще 15-20 лет одной из идей безопасности open source решений «От Торвальдса лично» было «этот код просмотрят пару тысяч раз, и все ошибки сразу и найдут».
И? 10 февраля 2025, Seven Years Old Linux Kernel Vulnerability Let Attackers Execute Remote Code
Хотя, история с Log4j куда показательнее. Никто не посмотрел в код с десяток лет, пока не всплыли проблемы.
Сеть.
С сетью в линуксе не то чтобы хорошо, не то чтобы плохо. Но, как только мы начинаем говорить про сеть, тут же всплывает OVN и Nicira. Продукт хороший, но слишком сложный для entry \ middle уровня, и не дотягивающий до NSX. Середину еще поискать, чтобы было хотя бы уровня Standard vSwitch (vSS) или vSphere Distributed Switch (VDS) или даже хотя бы простейшего Microsoft network controller.
Теперь все вместе. На примере такой простой сущности как гипервизор на x86.
Если взять разработчиков, которым не очень интересен проект,
добавить туда плотное непонимание менеджмента, что такое гипервизор, почему к нему сразу нужны средства отладки хотя бы уровня davg\kavg, как гипервизор управляется,
добавить не понимание, почему к продукту нужна открытая документация, почему KVM проигрывает как гипервизор в плотности размещения и управлении,
Добавить в проект такого менеджера, который отлично знает, откуда биткойны берутся, и как сети работают, но не понимающего, что не так в продукте, одна же виртуалка запускается, и даже LAG есть, что не так то.
Добавляем вопросы в группах «расскажите, есть ли в нашем куске кода хоть что-то рабочее». Причем, если бы еще в нужной группе вопросы были, а то среди таких же любителей майнер на площадку притащить.
И получится стандартный импортозамещенный продукт.
В итоге получаем продукт без экспертной поддержки на уровне разработчика. Просто потому, что в Linux kernel нет команды vm-support, дальше все, приехали.
В прессе все хорошо, блок на хабре оплачен, значит можно замалчивать неприятное и писать только непроверяемое приятное.
Разве что в комментариях могут сказать, что весь текст - FUD (акроним от англ. fear, uncertainty and doubt — «Страх, неуверенность и сомнение»). То есть ЛПП. И немного могут носом повозить, по незнанию маркетологами базовых вещей. Даже не очень приличные люди, как Гилев, после такого тыкания носом в глубину незнания, удаляют профиль. Но, маркетологам в проплаченном блоге такая вещь как стыд, не знакома.
Итого
В прессе, как видно на трех примерах, все и везде отлично.
Если не писать про брак, или сваливать проблемы с браком на то, что подрядчики «не так хранят».
Если не писать, что планы по авиации изначально были не выполнимы, и в итоге сорваны на 2-3 года.
Если не писать, что у продуктов нет даже базового функционала по сравнению с проприетарным ПО 15 летней давности, не говоря уже про документацию, открытые стенды итд.
Нет даже намеков на базовые вещи, типа
https://www.vmware.com/resources/hands-on-labs
https://learn.microsoft.com/en-us/training/azure/
https://www.redhat.com/en/services/training/learning-subscription
И, еще раз подтверждается вывод, особенно актуальный после ухода из РФ западных вендоров. Если у компании есть блог на хабре (Промо - 180 к рублей за 6 месяцев, а так – полмиллиона рублей за полгода), но в нем написано про что угодно, кроме как про компани, значит компания очень беспокоится за рекламу, а все остальное – не очень. Особенно это хорошо видно на примере МТС и Базис (Ростелеком). Хотя и остальные копроблоги последние два года такие, что не понятно, они что, студентов нанимаюь писать за еду?
Технике, любой, все равно, что будут писать маркетологи.
Если сталь для подшипника и последующий процесс получения и роликов, и изготовления смазки, и набивания в готовый подшипник смазки не соответствуют требованиям, то подшипник развалится.
Если двигатель (или турбину большой мощности) делать под крики «давай-давай надо вчера», то она разлетится сначала на стендах, затем на летающей лаборатории.
Если делать продукт командой, вообще не понимающей, что они делают, то будет не работоспособный продукт.
Словесная магия не работает.
При чем тут Епишев, спросите вы?
При том, что при умелом руководстве ГлавПУР – СССР получил в Афганистане:
Санитарные потери — 53 753 раненых, контуженных, травмированных; 415 932 заболевших[3]. Из заболевших — инфекционным гепатитом — 115 308 чел., брюшным тифом — 31 080, другими инфекционными заболеваниями — 140 665 человек.
Вирусные гепатиты А и Е с фекально-оральным механизмом передачи и их скрытым периодом в месяц они такие, коварные. И никакой плакат их не остановит, как и конспектирование текущей мировой ситуации.
Модная концовка.
Я, как обычно, ничего не придумал.
PS.Кто постарше, может вспомнит - был такой робот Федор. Как он там, волнуюсь за него.
Для ЛЛ: занудное капитанство.
Третьего дня обсуждал с одним знакомым проблему того, что его джуны вообще не понимают, как чего происходит. Джуны прочитали (с трудом) только проект Феникс, но не прочитали Дедлайн. Менеджмент не хочет читать ни мифический человеко-месяц, ни пояснительных записок.
Вторая его проблема – объем данных в его фирме плавно подходит к суммарно 200 терабайт, что же делать.
По второму вопросу я не смог понять, в чем проблема, кроме бедности, переходящей в нищебродство.
В современную all-flash СХД размером 2 юнита влезает до 36 palm NVME дисков. Берем 30 дисков 02355PWS или 02355FQB по 15 тб, вот и 400 Тб доступного места. Берем 15 дисков 02355WSM по 30 Тб – вот и 360 Тб. В два юнита полпетабайта точно войдет, может и петабайт получится, считать надо.
По первому же вопросу, я поддался на провокацию и решил написать черновик для базы для джунов.
Все это есть в книжке от ЕМЦ, про переход к управлению данными, вот бы ее кто-то еще читал.
От хранения данных к управлению информацией: Оглавление , отрывок
Но, все же.
Вначале была перфокарта, и ее тоже изобрели (не совсем), но патент) в IBM. Потом появился бит, и этот бит был в байте, и этот байт был на панели переключателей. Затем и магнитных лент напридумывали, IBM 726 – это 1952 год. Дальше было всякое, как первый диск IBM 350 из 1956. Все это легаси до сих пор живет и работает, пусть и в сильно измененном виде, как те же дискеты 3.5 на Airbus 320 и Boeing 747-400.
Что осталось на сейчас, и где начинаются проблемы восприятия.
Когда кто-то пишет свою первую программу, она, очевидно, сначала хранится на жестком диске. Он, конечно, уже давно не диск, а привод, Solid-State Drive, хотя и механические диски еще не сдали свои позиции. Но, конечно, сейчас уже не то – эпоха дисков на 15.000 оборотов закончилась в 2016 году, диски 10к потихоньку умирают, если не умерли совсем – объемов выше, чем 2.4TB SAS 10K SFF (HPE 881457-B21) я не видел. Это все те же Seagate Exos 10E2400 из 2020 года, что-то уровня ST2400MM0129. Все что позже – 7200. Не знаю даже – живы ли ноутбучные 5400. SSD подешевели, милорд. Но, что-то я ушел от темы. Проще сказать, что SSD выбили HDD с огромной части рынка, и идти дальше.
Когда у вас один диск в системе, и нет задачи обеспечения доступности хотя бы с 8 утра до 20 вечера с понедельника по пятницу, с перерывом не более часа, то вопрос отказоустойчивости не стоит. На малых объемах, и при отсутствии требований по доступности, хоть раз в месяц на внешний диск, или в облако*, или и туда и туда, свои данные копируйте, и все будет отлично.
*Кроме российских облаков, конечно, которые могут лежать и сутки, и неделю, и потерять данные совсем.
Когда возникают хоть какие-то требования по доступности, обязательно подкрепленные грязными зелеными бумажками, начинаются изучения вариантов «как повысить доступность данных».
Еще раз: если потеря данных не стоит «ничего», если простой считается как «бесплатный», то и беспокоиться не о чем.
Один из самых старых методов – собрать массив из дисков, Redundant Array of Independent Disks. Raid. Обеспечили избыточность в 1,2,3 диска (при этом зеркало (Raid-1 \ Raid 10\ Raid 50), не дает защиты от выхода из строя двух ЛЮБЫХ дисков), и все хорошо, и относительно недорого – нужны только диски, хотя желательно (не обязательно) иметь аппаратный RAID контроллер. С аппаратными контроллерами свои сложности, с программными - свои. Про MS Storage spaces, Storage spaces direct и LVM будет ниже (или нет).
Ок, от выхода из строя 1,2,3,N дисков застраховались, но на пути к доступности данных еще много препятствий. В обычном сервере (не рассматривая BullSequana и очень толстые IBM) отказ любого процессора, модуля памяти (с оговорками, не все вендоры серверов умеют исключать из работы модуль памяти с некорректируемыми ошибками), сетевой карты, итд – ведет к потере доступности данных. Хорошо, если «перезагрузили и заработало», но как быть, если «перегрузили и не работает»? Сами данные, может, и целы, но сервис, работавший с этими данными, не доступен.
Сноска: интересна ситуация со старыми Lenovo и Supermicro в blade системах. Я сталкивался на HS-22, коллеги ловили такое поведение на Supermicro. Сетевая карта просто пропадает из системы, но возвращается не после перезагрузки, но только после полного обесточивания лезвия. Выключили лезвие, выдернули из слота, подождали минуту, вернули – сетевая карта на месте. Может снова пропасть через 3-6 месяцев. Начинается такое поведение через 5-7 лет работы.
Есть много других неприятностей, таких как одинокий коммутатор. Или стек коммутаторов – стекированные коммутаторы при обновлении время от времени отказывают всем стеком, при этом встает намертво что элитный Cisco vPC (Virtual Port-Channel), что другой обычный порошок коммутатор с MC-LAG (Multi-Chassis Link Aggregation Group). В том числе поэтому в проприетарных решениях уже давным-давно есть Switch Embedded Teaming (SET) и vSphere Standard Switch с active-active, что позволяет выкинуть проблемы с отказом стека, и получить не менее (не)приятные проблемы при других сценариях отказа.
После всех размышлений, оказывается, что для решения проблемы отказа одного сервера – надо хотя бы два сервера (до георезервирования дойдем чуть позже). И два коммутатора, но лучше четыре – два под обмен обычными данными, и два под сеть передачи данных хранения. И не пускать во вторую сеть никого, особенно не пускать сетевиков. Простая, надежная сеть с включенным RDMA и настроенным DCB (или DCBX - data center bridging eXchange, ECN - Explicit Congestion Notification, Priority Flow Control)).
Как данные передавать будем? Есть несколько вариантов решения, самый простой – SAS корзина, осталось только как-то убедить операционные системы не конфликтовать друг с другом и не писать в один блок на дисках – разные данные, что тоже не так просто.
Поэтому возникает не самый простой вариант, точнее два.
Первый. Синхронизацией данных занимается операционная система. Записали данные на одном сервере, отправили блоки данных на другой, записали там, получили со второго сервера «ок», отчитались приложению (или нет). Как DRBD.
Второй. Два приложения на двух серверах могут и сами позаботиться о надежности. MS SQL и Oracle Real Application Clusters умеют в репликацию данных «из коробки». Oracle с 2001 года, MS - не знаю, в версии SQL Server 2008 R2 уже был Failover Cluster. В Postgre вы попляшете вокруг pacemaker, corosync, patroni (и к нему etcd), vipmanager, PgBouncer, pgpool-II, Slony, Stolon и еще чем-то, и потом попляшете с WAF. Обычно это теперь работает, хотя еще недавно (2016 год) Uber сказал «ну нафиг». Прошло уже столько лет, сейчас есть вроде живой Autobase for PostgreSQL. Решения есть, выбор за вами.
Все это отлично работает, пока вы оперируете 1-2 серверами. Ну 3-4. Ну 10. И пока у вас на складе всегда есть запасной сервер, или вам по гарантии привезут все, что надо за 1-3 бизнес-дня. Отказал сервер – не беда, достали холодный, поставили ОС, а хоть и ироником, или поставили и прокатили плейбук или воткнули под DSC -
Нащяльника, мая сервира паставиль, фрибизьдя инсталя сделаль, апачи сабраль, пыхапе патключиль, сапускаю, а ано - ажамбех пашамбе эшельбе шайтанама!
В комнату входят виртуализация и контейнеры.
Все, что выше, хорошо выглядит на примере baremetal. Когда в системе все четко - один сервер, одна программа, одна база данных, один монолит. (Гусары, молчать). Только это дорого – на современном сервере по 12-90 (на arm до 192 ядер у Ampere, и обещают 256) ядер на сокет, 2 сокета, и даже если ставить туда всего 2 модуля памяти по 64 Гб «из экономии», то все равно как-то не экономично получается. Потому что оперативная память ничего не стоит на фоне всего остального. Получается, что сервер на 90%, а то и 99.95% простаивает.
Почему? Потому что часть программ, как та же 1с – не умеют в многопоточность без особой магии, да и с магией не умеют. А если за дело берутся маркетологи, которых по недосмотру не усыпили, да потом они же пишут статьи «как настроить 1с», не понимая ни как работает турбобуст, ни как работает переподписка и планировщик, и даже не пробуя читать ИТС и настройки параметров рабочего процесса, то тут ничего не спасет от закупок baremetal. На Core i9. Техническая безграмотность, но оплаченный маркетинг – получаем безграмотные статьи в корпоративных блогах. Про это я попозже напишу, была тут эпичная битва двух якодзун на одном сайте.
В остальных случаях возникает экономическая потребность и выгода от виртуализации. Конечно, можно обойтись и без нее, но разбираться в хитросплетении зависимостей от разных библиотек зачастую экономически бессмысленно – на выяснение может уйти 8, 16, 40, 240 рабочих часов. Дешевле разнести приложения по разным виртуалкам. Попутно можно получить кучу бонусов, наподобие HA, FT, vmotion, и так далее.
Но. Если у нас внизу, в аппаратном сервере, нет доступного разделяемого внешнего хранилища, то мы будем вынуждены перемещать данные с сервера на сервер для любого обслуживания сервера, или делать какое-то иное резервирование. Про HCI будет позже, в самом низу.
Это возможно, но есть проблема роста объемов данных.
Одно дело, если у вас скромные 10-20-200 гигабайт данных. С современными дисками, с современной хотя бы 25G сетью, даже с давно уже копеечным, неуправляемым 10G коммутатором, без MPIO вы получите на чтение и запись что-то около 0.5 – 0.7 гигабайта \ секунду, 30-40 гигабайт в минуту. 5-10 минут и 200 гигабайт переместились, все рады. А если там система в 2 терабайта? Полтора часа туда, полтора часа оттуда, и необходимо на каждом сервере держать немалый запас свободного места. Плюс иметь на каждый сервер по запасному диску на горячую замену. Плюс на каждом сервере теряется 2 диска на Raid 6.
10 серверов – минус 30 дисков просто для отказоустойчивости, и еще держать свободный объем на 2 самые крупные базы данных, или хранилища, или что-то. Даже если скриптами подбирать конфигурацию оптимального размещения по объему, может возникнуть проблема шумных соседей, когда две базы (или два сервиса) что-то одновременно пишут. Для SSD это не так критично, но RAID берет свое, даже на SSD и NVME. Особено на NVME. Или вдруг два бекапа запустились, и сеть забилась.
Зато, до какого-то предела, наглядно и дешево, не надо никаких систем хранения данных.
Тут вы, конечно, скажете – товарищ Отрепьев, а вы ж врете и не краснеете, зачем нам RAID, если мы разносим данные на уровне серверов. Значит, достаточно LVM, или базу по файлам или партициям разделить по sda, sdb и далее. И я отвечу – все так и есть, вообще без проблем. Восстанавливать потом как будете, переливать весь объем данных, или настраивать репликацию диск в диск, причем с авто восстановлением конфигурации? Можно и так сделать, только насколько это удобно и надежно? Или все же RAID, чтобы система сама выкинула неисправный диск и пошла работать?
Но.
С RAID возникает еще 1 проблема, которая порождает сразу 3 других. И эта проблема – восстановление при сбое.
Проблема №1. Raid 5 не очень надежен на механических дисках, и особенно диски consumer \ home grade.
Математика ребилда известна, при объемах данных в терабайты и обычных (не enterprise) механических жестких дисках и домашних \ consumer SSD шансы потерять данные:
6 дисков по 2000 Гб, ошибка 1*10(-14) – шансы на потерю данных 55-65 % на каждом ребилде. Калькулятор 1, калькулятор 2.
Шансы потерять данные за 2 года эксплуатации при оптимистичном MTBF в 250.000 часов – 20%. Калькулятор 3. При консервативном подходе – 33% риска потерь за 2 года эксплуатации.
С ростом объемов риски растут, и использование 10 дисков по 4 Тб в R5 с даже в 10 раз меньшим числом ошибок (1*10(-15)) дает что-то порядка 80% удачи, 20 % неудачи, и 10% риска потери данные за первые 2 года эксплуатации дисков (при консервативной оценке MTBF).
Простая математика:
Consumer SSD error rates are 10^16 bits or an error every 1.25PB.
Enterprise SSD error rates are 10^17 bits or an error every 12.5PB
Статья: Flash banishes the spectre of the unrecoverable data error
Если у вас хранятся пользовательские фотографии, или какое-то видео котиков, то испортился бит, или потеряли этих котов десяток – да и наплевать. Вот бы еще все было так просто, что случилась ошибка на ребилде, и было бы сразу понятно, что ошибку можно пропустить, и будет потерян всего лишь звук загрузки и два пикселя фотографии кота на рабочем столе. А если нет? Нехорошо как-то. Особенно нехорошо, что при ребилде нет кнопки «пропустить». Придется тащить диски в какую-то лабораторию (которых еще поискать), перечитывать данные еще раз (может, прочитаются, может и нет), тратить какие-то деньги на все эти операции, все это время система без дисков будет или стоять, или работать на только втором сервере.
Raid 10 тут в чем-то хуже, хотя перечитывать и восстанавливать нужно суммарно только объем одного диска. Зато можно внезапно обнаружить, что второй диск тоже умер, просто его не давно не проверял никто в фоновом режиме.
Проблема №2. Работа под нагрузкой при ребилде
Пока все данные пересчитываются и перечитываются, какой-то % дисковых операций тратится на них. Параметр регулируемый, но все равно, на время ребилда классического рейда, эта нагрузка, скорее всего, будет так или иначе заметна. При этом диск в плохом случае вылетит не в пятницу вечером, а в середине расчета зарплаты.
Проблема №3. Скорость ребилда
Поскольку надо восстановить целый диск, то все восстанавливаемые данные будут писаться на один диск, через его один интерфейс. Это долго, это часы и даже дни. Использовать raid 2.0 \ draid – raid контроллеры пока не умеют.
С контейнерами все становится или лучше, или хуже, это как посмотреть.
Пока контейнеры живут, как и положено, в режиме «жил жил, пока не умер – stateless», ничего страшного не происходит. Умер Максим, и ладно. В доме заиграла музыка, k8s\ k3s\ прочие оркестры сыграли марш и подняли новые контейнеры. Как только в контейнере начинает жить что-то с записью на диск, stateful – тут же начинаются PersistentVolume (PV) и прочие драйвера к внешнему хранению. Вы скажете S3, облако, но в итоге данные все равно приземляются на те же SSD\HDD.
Итог. Если хотите высокодоступную виртуализацию, или не виртуализацию, то сначала определите, что для вас «высоко». Потом или стройте репликацию на каком-то уровне, со своими плюсами и минусами, или считайте стоимость внешнего хранилища, или, но про это чуть позже, готовьтесь к HCI - Hyper-converged infrastructure.
Еще раз: это всё, всегда, и без исключений – про деньги.
Бизнес, то есть генеральный директор, должен понимать, с точностью до значимых чисел, стоимость простоя, риски простоя в год, и стоимость инфраструктуры и людей для обеспечения этой доступности.
Можно сделать какие-то решения и на костылях, сделать свой SC VMM на скриптах, кронтабе, потом подтянуть API – весь инструментарий для этого есть. Но сколько времени займет написание своих костылей, и кто будет поддерживать эти костыли после увольнения писавшего? Особенно если код написан в спагетти стиле?
Системы хранения данных, год 2025.
Чтобы говорить про СХД, нужно знать и понимать хотя бы следующее.
Классическая СХД в вакууме – это СХД начального уровня. Деды вспомнят, может и без таблеток, про HP MSA2000 G2. Еще пока был единый HP. Или вспомнят Storwize какой-то. В общем, все, что было до появления божественной Евы 4400. Или, если это уже прадеды, то накидают боевых картинок со сменными блинами для дисков. Это уже не так интересно.
Современные СХД можно условно разделить на следующие группы:
Почему условно? Потому что термин не закреплен в ISO \ IEEE \ ГОСТ, и любой маркетолог может сказать «это СХД». Была даже такая редакция Windows - Windows Storage Server. Может, кто-то вспомнит VNX.
Группа 1. Вообще не СХД.
Это и программные решения, типа Raidix, и Synology RackStation RS1221RP, и много лет рекомендуемый лучшими майнерами и их друзьями Infortrend, и тот же Ceph. Тысячи их. Хотите считать эти изделия СХД – пожалуйста, только не забывайте, что у них или по 1 процессору и материнской плате, то есть или по одному контроллеру, или для них нужно хотя бы три сервера. Лучше пять. Или они просто кривые, который год.
Лично для меня СХД начинается от «всего по хотя бы два» - два блока питания, два независимых контроллера. Можно 4 блока питания и 4 контроллера. Больше можно. Меньше нини. Контроллеры могут работать в каком угодно режиме, и с любым Path Selection policy (PSP) - Active/Optimized, Active/Non-optimized, Standby, это не так важно. Хотя как, «не так». Если у вас на СХД переключение путей при отказе контроллера идет больше таймаута на системе виртуализации, или больше таймаута на нагруженной системе внутри контейнера или виртуализации, а это может быть и 30 секунд, и 5 секунд, то система виртуализации может сказать (и скажет) – все мертво, All-Paths-Down (APD), Permanent Device Loss (PDL), и остановить ввод вывод. С последующими криками боли и унижения. Естественно, без вазелина. Как при этом Земля не проваливается в око ужаса, не понятно. Но про это позже.
Группа 2. СХД начального уровня, уже даже и гибридные.
Мир меняется, технологии растут и дешевеют. Лет 20 назад тиринг и динамические рейды только появлялись «для масс», сейчас они почти везде. Даже не найду, когда появился тиринг, в 2011 году уже был. В 2008 году был. Истина где-то рядом.
10 лет назад all-flash-array (AFA), то есть СХД с софтом, оптимизированным на работу только с СХД, стоили совсем других денег, чем сегодня Huawei OceanStor Dorado 3000 V6.
Очередное пояснение. У Huawei сейчас используется следующее деление в маркетинге, которое многих путает. OceanStor – это «вообще все СХД», OceanStor Dorado – линейка all-flash-array, v6 – поколение. Рисовать таблицу не буду.
Поэтому получается так:
СХД начального уровня = СХД малой производительности, с урезанными функциями относительно старших моделей в ряду. Сложно расширяемые - например, нельзя подключить внешние дисковые полки. Хотя, этот пункт тоже под вопросом, полки HP D2600 и D2700 числились как совместимые с HPE P2000 G3 FC Modular Smart Array System.
Гибридные СХД – системы, в которых можно одновременно использовать механические и SSD диски. Таких систем полно.
All-flash-array (AFA), русский перевод термина отсутствует за ненужностью. Это СХД, работающие только с SSD. Теперь (уже лет пять?) есть и начального уровня, относительно задешево. Dorado 3000 например.
У СХД среднего уровня добавляется и производительность, и надежность. Для AFA к All-SAS SSD добавляется ALL-NVME SSD, с их оптимизациями под NVMe over Fabrics (NVMe-oF) и NVMe over RDMA over Converged Ethernet (NVMe over RoCE). С последними поколениями коммутаторов на FPGA Xilinx UltraScale VU9P, скажем Arista 7130E с их задержками в 50 ns, все становится очень интересно.
Маркетологи в Arista ленивые, просто ну невозможно. Могли бы и поменять что-то, а то пишешь статью и узнаешь, что были Arista 7130 Series 48E, стали Arista 7130 Series 48L with UltraScale VU7P-2 FPGA, еще в 2021.
Хотя в Cisco и 80 ns рады. На 400 GbE портах.
Добавляется лицензирование метрокластера, добавляются всякие онлайн дедупликации и компрессии, иногда и офлайн, добавляется возможность поставить не 2 контроллера, а 4.
У кого-то добавлялись (или уже нет, я не успеваю следить за сменой 3Par на Alletra) возможности резервировать данные на случай отказа не только одного диска, а целой дисковой полки. Добавляется маскарадинг, или как это не назови – когда можно спрятать старую СХД за новыми СХД, и данные со старой СХД будут доступны через контроллеры и интерфейсы новой. Прочие бонусы, пусть про них маркетологи рассказывают.
У старших моделей, то что у маркетологов называется mission-critical storage, добавляются надежность, но, прежде всего, меняется архитектура связи контроллеров. Самих контроллеров можно ставить 16-32 штуки, дисков чуть ли не 10-20 тысяч штук, итд итп. Дорого, богато, объемно, быстро, надежно.
Лидеров по тратам маркетингового бюджета, как и раньше, можно смотреть в квадрате Gartner.
Отдельно в тех же квадратах введено разделение:
Primary Storage Platforms
File and Object Storage Platforms
Full-Stack Hyperconverged Infrastructure Software
потому что, как иначе продавать рекламу и места в квадрате для всех участников рынка?
Имена всех участников более-менее на слуху: Dell PowerMax, HPE Alletra Storage, Netapp, Pure Storage, Lenovo, Fujitsu (они еще живы? Оказывается да), Hitachi Vantara (тот же вопрос), Huawei, Infinidat, почему-то Inspur и даже Infortrend.
Что предлагается тут для повышения надежности хранения и повышения доступности в среднем и старшем, а то и в младшем сегменте рынка?
Ничего особенно нового.
Локально – все те же вариации на тему Distributed RAID - Lenovo ADAPT, IBM distributed RAID (DRAID), Huawei Raid 2.0, Netapp SANtricity Dynamic Disk Pools (DDP), и так далее. Очень удобно, очень быстро. Быстрее разве что фоновая подготовка к отказу диска, есть такая модная тема.
Глобально – тоже ничего нового, метрокластер и синхронная или асинхронная репликация, смотря что хотите.
Для любителей кластеров подлиннее есть и Synchronous Long Distance (SLD).
Иногда теперь внутри стоит «что-то такое про Artificial intelligence (AI)» - который обрабатывает кеширование, и какие-то маркетинговые (как сейчас продавать что-то без пометки AI? Никак), и внутренние задачи.
Чуть было не забыл про «все для тестов и резервного копирования» - снимок (снапшот) тома, синхронный снимок группы томов, презентация снимка кому надо – например, для того чтобы быстро отдать копию боевого тома в тесты, или сделать бекап клона тома. Само собой API для обеспечения работы систем резервного копирования.
Конечно, батарейки для поддержания кеша в живом состоянии. И многое другое, всякие там аналитики отказов, звонки другу, счетчики ресурсов итд итп. Драйвера под Openstack само собой.
Програмно-определяемые СХД, Software-defined storage (SDS).
Как говорит википедия, Software-defined storage (SDS) is a marketing term ..
Термин очень и очень маркетинговый, потому что почти все современные СХД, так или иначе, программные. Зачастую на все тех же x86, или на arm. Базовая ОС – скорее всего варианты с ядром Linux. Внутри может быть пара контейнеров для обеспечения файлового или S3 доступа. Внутри иногда можно даже запустить свой контейнер или виртуалку, с массой ограничений, но можно.
Продают их примерно все вендоры, и ничего плохого в этом нет. Вопрос в том, сколько в продукте маркетинга, а сколько технической составляющей. Отдельно надо сказать, что имеет значение и цена, и выбор масштабирования – горизонтальное или вертикальное.
Хочется хранить больше пиратского кино в старом добром формате «8 фильмов на 1 DVD» - ваш выбор горизонтальное масштабирование, много дешевых серверов с дешевыми дисками и резервированием x3.
Хочется высокой скорости и отсутствия простоя, пока на ЦОД Госзнак идет восстановление - выбираете дорого, богато.
Что там на слуху? Ceph, linstor, Vitastor?
В чем главный минус всех этих решений? Это дорого.
Дорого не в смысле разовых вложений, запустить все это можно на любом железе из ларька бу техники. И это даже будет работать. Ничего сложного в первом запуске нет. Если у вас 3 БУ ПК, нет требований к надежности, нет требований по скорости (линейной или IOPS), нет задачи обновления, нужно «просто чтобы работало» - берете 3 ПК, собираете, работает. Потом увольняетесь, пока само не упало. Можно даже запустить виртуализацию там же. И даже что-то заработает, то есть запустится. Идеальное решение для статьи корпоративного блога на Хабре, скажем, для МТС. Особенно, если не писать «да, наше облако упало и лежало неделю, потому что». То есть, если у облака с таким хранилищем нет в соглашении крупного штрафа за простой, в деньгах, а не в «скидке 5% на следующий месяц», то они могут хоть Ceph ставить, хоть писать что они не смогли что-то сделать с Openstack и выбрали Cloudstack. То же самое, только сбоку.
Отказываться от VMware Cloud Foundation русские облака не спешат. Мировые, впрочем, тоже. Да, это дорого. Очень дорого. Клиент платит.
Если не считать TCO, total cost of ownership, и умело считать CAPEX и ФСБУ 26/2020, то Ceph выглядит дешевле. А если считать? И если прибавить требования со стороны прочих департаментов \ отделов \ etc?
Очередное отступление в сторону.
Может показаться, что Ceph выглядит в этом тексте как мировое зло, на фоне светлого и прекрасного корпоративного решения «задорого», в то время как для фирмы бесплатный Ceph выглядит идеально. Затраты на лицензии ноль, затраты на поддержку у фирмы – ноль (планируется, что его развернет и подключит имеющийся штат), собрать можно на двух HPE Gen 6 с процессором на целых 4 ядра возрастом 12 лет, что может пойти не так? Дада, мы (менеджмент) конечно тебя услышали. И что надежность низкая, и что может упасть, что нужно купить что-то под бекап, обязательно купим в следующем году. ЧТО ЗНАЧИТ УПАЛО И ТЫ ПРЕДУПРЕЖДАЛ? НЕДОСТАТОЧНО ПРЕДУПРЕЖДАЛ! ВИНОВЕН!
Российский, и не только российский, бизнес, очень любит перекладывать риски и переводить стрелки на исполнителя. Упал сервис – виноват Вася, недостаточно часто обращал внимание руководства на состояние и риски. Слишком тихо и редко кричал. Почти всегда, за очень редкими исключениями, бизнес будет переходить к теме «я начальник, ты дурак, начальство не ошибается - значит, ты виноват». Единственный работающий способ – не трогать любую потенциальную дрянь даже палкой. Никак. Никогда. Спорить с начальством, наслушавшимся сына маминой подруги, прочитавшего 1.5 статьи в маркетинговом копроблоге, бесполезно – есть два мнения, его и неправильное. Конфликт с начальством вообще не продуктивен. Но, иногда приходится выбирать:
– Вступать с размаха в очевидные проблемы, тратить дни и ночи на разбирание в многолетном наслоении питоновых отложений, и все это за ту же зарплату, получая вообще не оцениваемый на рынке в рублях или долларах опыт починки, сидя по шею в этих отложениях, или
- Увольняться. Заявление на стол, дальше не твои проблемы. Все эти рассказы в фирме «мы семья, мы команда» заканчиваются с первыми признаками проблемы.
Сам продукт при этом не плох, не хорош. У него есть своя ниша, свои понятные характеристики, поведение итд. В пределах этой ниши он может выполнять свои задачи. В очень, очень узких пределах, на нормальном железе, настроенный под задачу, после полугода тестов и 3-5 разносов стендов.
Если говорить про аналогии, то и система BASE-STEP (запущена 24 октября 2024) и тачка для навоза на даче, решают задачу доставки чего-то из точки А в точку Б. Только стоят по разному, и не все можно перевозить на тачке, и не всё стоит перевозить на BASE-STEP – если в BASE-STEP сунуть навоз, то может рвануть.
Но нужны обе. На своем месте.
Модное веяние последних 10 лет – HCI. Hyper Converged Infrastructure
В какой-то момент, с ростом количества и качества ИТ, внедрения «всего» и «везде», фирма приходит к какому-то равновесию. На каждый новый сервис в среднем нужно сколько-то ядер, сколько-то гигагерц. Нужна память. Нужно дисковое пространство. Становится удобнее оперировать одинаковыми серверами, подключенными к 1-2 системам управления. Таким, как Intel Data Center Manager, Aria Operations Management Pack, HPE OneView и так далее. Сводные отчеты, сводные таблицы, автоматизация везде и всюду.
Возникает идея – зачем нам СХД, если у нас и так и так есть сервера с отсеками под диски. Давайте сделаем систему с распределенной программно-определяемой СХД, которая будет работать с нашей системой виртуализации и с локальными дисками. Возникает redundant array of inexpensive servers (RAIS) или redundant array of independent nodes (RAIN). Очень удобно. Уперлись в потолок – купили еще 1, 2, 6 стандартных единиц, добавили в систему, дальше оно само. Хотите такое же, но ориентированное именно на хранение – можно и так, просто поменяйте настройки и занесите деньги по счету. Хотите не 2 петабайта, а 4,6 – пожалуйста, проходите в кассу. Скорости – отличные, надежность (обычно) – 4-5 девяток, 99.99 – 99.999.
Ограничения – да почти никаких, можно начинать строить хоть с 2 серверов, даже без коммутатора. Shotgun mode и понеслась.
Минусы написаны мелким шрифтом:
Очень узкий список протестированного на совместимость оборудования.
Очень высокие требования к квалификации эксплуатирующего персонала. Особенно сетевиков, которые зачастую не готовы читать про требования к RDMA, и не понимают, как и зачем реализованы что Switch Embedded Teaming, что Network Air Gaps.
Обманчивая простота снаружи, при этом внутри надо знать «как» и «как именно» это работает, а не только в GUI кнопки нажимать.
Отвыкать, точнее ни в коем случае не лечить проблемы ребутом.
Облако.
Как же без него. Про облака, все, есть три заблуждения: что это быстро, надежно, дешево.
Ничего подобного. «Быстро» в российских облаках предполагает какие-то очень костылизированные решения. Аналогов классов хранения по моему нет ни у кого.
Надежность применительно к российским облакам, которые могут валяться и сутки, и неделю, но все это время маркетологи строчат статьи «у нас все хорошо», вообще не применима.
Дешево .. это как сказать. Во сколько вам обойдутся сервисы, лежащие час в облаке?
В иностранных облаках ситуация принципиально другая. Или нет. Не то, чтобы они порой не лежат. Лежат, и еще как. Недавно опять часть Azure лежала три дня, с 8 по 11 января.
Вот отчет: 01/08/2025 Post Incident Review (PIR) – Networking issues impacting Azure Services in East US 2, Tracking ID: PLP3-1W8. Что сломалось, почему сломалось, как сломалось. Особенно если вчитываться, и понимать, какие смуглые друзья и дефективные Кумары и их такие же менеджеры стоят за строчками
All manual configuration changes will be moved to an automation pipeline which will require elevated privileges.
Consider ensuring that the right people in your organization will be notified about any future service issues
И почему вышла статья Azure networking snafu enters day 2, some services still limping.
Но. Хотя бы вышла и статья, и разбор, и обещания все исправить.
Классика, точнее перевод -
Оригинал
East Coast personality vs West Coast personality
me: trying fix a flat tire in California: oh, bummer, that must be hard for you
in Baltimore: baby, what the ()is wrong with you, JEESUS CHRIST here let me do it before you () up your car more
When I describe East Coast vs West Coast culture to my friends I often say "The East Coast is kind but not nice, the West Coast is nice but not kind," and East Coasters immediately get it. West Coasters get mad.
If you're from the great white north, you get that kindness but not niceness everywhere. "() you but have a great day" "Wow that () made the best sandwich I've had in years, I gotta tip next time."
перевод
Менталитет Восточного побережья и Западного побережья
я: пытаюсь починить спущенное колесо в Калифорнии:
ох, дедушка, это должно быть тяжело для тебя
в Балтиморе: детка, что с тобой () не так, ИИСУС ХРИСТОС, давай я сам сделаю прежде чем ты () сломаешь все совсем.
Когда я описываю своим друзьям культуру Восточного и Западного побережья, я часто говорю: «Менталитет восточное побережья: дружелюбные, но не миленькие,
Менталитет западное побережье: миленькие, но не дружелюбные».
Жители Восточного побережья сразу понимают, что имеется в виду.
Жители Западного побережья бесятся
Для ЛЛ: eval – отдельная редакция, остальное очевидно.
Давно я не обновлял у себя на стенде Windows server, на прошлой неделе добрался.
Скоро и в прод – уже вышли кумулятивы:
2025-01 Cumulative Update for Microsoft server operating system version 24H2 for x64-based Systems (KB5050009)
2025-01 Cumulative Update for .NET Framework 3.5 and 4.8.1 for Microsoft server operating system version 24H2 for x64 (KB5049622)
Конечно, не второй сервис пак, но что ж поделать.
Почему это важно: поддержка 2012R2 закончилась, поддержка 2016 закончилась, скоро закончится и поддержка для 2019. Плюс в 2025 обещают всякие приятные вещи, ускорения и улучшения. Мне интересно посмотреть на GPU partitioning, и улучшенный S2D.
Картинка от 2019, суть та же
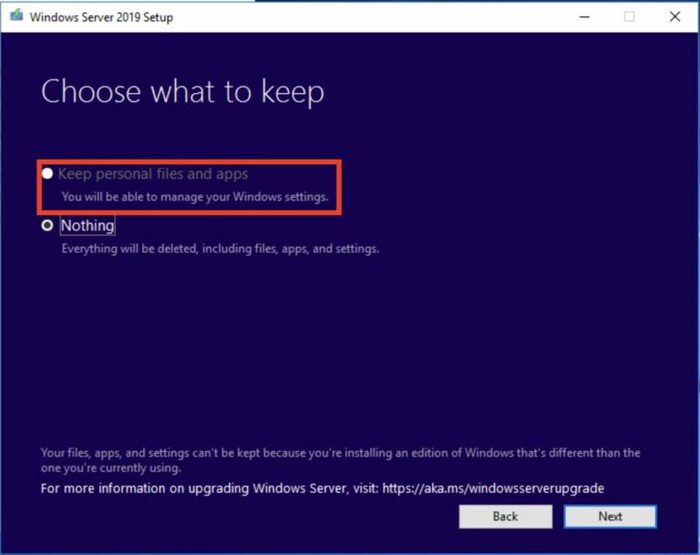
MS предлагает 5 вариантов установки и обновления до MS Server 2025: in-place upgrade, Installation, Migration, Cluster OS Rolling Upgrade, License conversion. Ничего особенно нового, ничего интересного. Прочитали, проверили на стенде, и в бой.
Разве что внезапный KB5044284, и прочие известные проблемы.
Так я и думал, запуская привычный Setup с ISO – и увидел, что обновляться мне не положено. Пункт «сохранить файлы и настойки» - серый, и не выбирается. Давно такого не видел, удивился. Пошел посмотрел
reg query "HKLM\SYSTEM\CurrentControlSet\Control\Nls\Language" /v Installlanguage
Но нет, все нормально, английский.
Пошел читать, и в сегодня лет узнал, что с точки зрения MS существует не 4 редакции Windows Server (Standard core, Standard desktop, Datacenter core, Datacenter desktop), а 8 -
Windows Server 2025 Standard Evaluation, Windows Server 2025 Standard Evaluation (Desktop Experience), Windows Server 2025 Datacenter Evaluation, Windows Server 2025 Datacenter Evaluation (Desktop Experience) – и это не одно и то же.
Я думал, что разница в лицензировании, но ошибался.
Сейчас добавился Datacenter: Azure Edition (ServerTurbine).
Как посмотреть остаток здоровья известно, (Slmgr /dli или DISM /online /Get-CurrentEdition или Get-ComputerInfo | select OsName, WindowsEditionId) , как перезарядить на 180 дней – тоже, (Slmgr /rearm), прочее скучное тоже не новость.
Что делать.
Берем инструкцию у MS (Keep personal files and apps option greyed out when upgrading from Windows Server 2012 R2 to Windows Server 2019) или не у MS тут (Fix “You Don’t Have Permission” Error and Grayed Out “Keep Personal Files and Apps” Option During Windows Server In-Place Upgrade), на всякий случай читаем Fix Windows Update corruptions and installation failures, и делаем:
Распаковываем ISO в какую-то папку, в примере C:\ISO\SERV2016, делаем папку под временные файлы, C:\mount, и затем:
dism /mount-wim /wimfile:c:\ISO\SERV2016\sources\install.wim /mountdir:c:\mount /index:2
Важный момент с индексами – внутри install.wim лежит список этих индексов, 2 – для Windows Server 2025 Standard Evaluation (Desktop Experience), если вам нужен Windows Server 2025 Datacenter Evaluation (Desktop Experience) – то индекс 4.
dism /image:c:\mount /get-currentedition
dism /image:c:\mount /get-targeteditions
dism /image:c:\mount /set-edition:ServerStandard
На этой строке тоже не забывайте поменять настройки, если надо.
dism /unmount-wim /mountdir:c:\mount /commit
Все эти операции займут какое-то время – распаковка, запаковка. После этого можно будет запустить setup.exe, и обновиться по месту. Потом проверить, что получилось (DISM /online /Get-CurrentEdition)
Setup кривой.
Пару минут после запуска о чем-то думает, только процесс виден в списке процессов, при том что у меня на стенде 128 Gb памяти.
Дальше ничего интересного, сколько-то перезагрузок, и готово.
Настройки сохраняет, из тестового домена система не вылетела. Пишут, что так обновлять можно почти все – не знаю, не знаю. В случае Exchange, MS SQL и контроллера домена я бы так обновляться не стал.
Много слева, много справа
Всяких неприятностей!
Много неизвестностей
И там, и тут!
Для ЛЛ: 2012 R2 в 2025 году обновить не очень просто
Примечание: текст написан как заметка по troubleshooting, содержит лишние подробности.
Коллеги пришли плакать в личку – есть, говорят, на свете педобиры, а есть некрофилы. Их некрофилы хотят странного, любви, но без взаимности – чтобы обвешанная непонятно чем Windows server 2012 R2 работала, и ставила все патчи.
Коллег понять можно –хваленое импортозамещение регулярно не работает никак, кроме как на выставке, а соблюдать приличия, хотя бы в части патчей, надо.
В чем проблема.
Windows Server 2012 R2 давно снят с поддержки:
Mainstream End Date - Oct 9, 2018,
Extended End Date - Oct 10, 2023. Запомним эту дату, она нам еще будет нужна.
Но, по каким-то причинам*– к нему заявлена поддержка Extended Security Update Year 1, Extended Security Update Year 2, Extended Security Update Year 3 – до 2026 года.
* может, опять военные – MS поддерживала Windows XP для US NAVY до 2016 года и до сих пор поставляет «всякое».
Так что обновления выходят, последнее кумулятивное -
2024-12 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5048735)
Конечно, к нему нужно поставить
2024-10 Servicing Stack Update for Windows Server 2012 for x64-based Systems (KB5044413)
Но у коллег проблема – SSU ставится, а rollup не ставится, и все тут.
И настройки сбрасывали, и папку удаляли, и DISM делали – не идет каменный цветок у Данил мастеров.
Попросили меня.
Я не врач, но посмотреть могу.
Первым делом пришлось поискать у себя дистрибутив 2012 R2 c Microsoft Volume Licensing Service Center (VLSC). Всякого добра у меня в загашнике было, и 2003 сервер, и даже настоящий оригинальный Windows 2000 в коробочке, а 2012 R2 нет.
Пошел побираться.
Нашел en_windows_server_2012_r2_with_update_x64_dvd_4065220, почему-то на интернет архиве. Скопировал – пусть будет!
Попутно поискал по сусекам, по амбарам, у старых некрофилов (брал у них Nowell 4 не очень давно).
SW_DVD5_NTRL_Win_Svr_Language_Pack_2012_R2_64Bit_MultiLang_FPP_VL_OEM_X19-05196.ISO
MD5 506C7E34179267B09AD19575F271E0A7
SHA1 5A06AC7859EF9D8776E0D1067A9003044497F95E
SHA256 7D1CE64BB3EB719E86152D8B3568FAC631B2AB24422BC3B920679EB7AFFC6A4F
Microsoft Windows Server 2012 R2 RTM MSDN
SW_DVD5_Windows_Svr_Std_and_DataCtr_2012_R2_64Bit_English_Core_MLF_X19-05182.ISO
MD5 83BDF8034BCB019A8F001BAEEAB27326
SHA1 6823C34A84D22886BAEA88F60E08B73001C31BC8
SHA256 8BA8961E1CF10570A639F607963CFF9FF7EEDC42398F9F4D3B8670D5D9D3B1FF
Windows Server 2012 R2 with Update 1
SW_DVD9_Windows_Svr_Std_and_DataCtr_2012_R2_64Bit_English_-3_MLF_X19-53588.ISO
MD5 B52450DD5BA8007E2934F5C6E6EDA0CE
SHA1 D4B28F350981A7C3306DD409B172AEA10D8599AC
SHA256 C15E6E25377FAECF7E6D6B23723553211A4BC043773A62A06FBE2781F7E9F82E
Наверное, у кого-то где-то можно было найти что-то свежее с VLSC, но, чем богаты.
Поставил последний, получил чистый свежий билд 6.3.9600.
Надо было посмотреть
(Get-ItemProperty -Path c:\windows\system32\hal.dll).VersionInfo.FileVersion
потому что [System.Environment]::OSVersion.Version , оно же [Environment]::OSVersion ничего не показывает,
но я не посмотрел.
Включил авто обновление. Выключил IE Enhanced security. Выключил IE Protected mode.
– с ними не скачать хром, а IE из комплекта уже не может обработать https://www.catalog.update.microsoft.com/
Скачал хром. Скачал notepad++
Пошел, как пишут, скачал Windows Server 2012 R2 Update (KB2919355) – почему-то состоящий из 7 разных обновлений, но я взял только
windows8.1-kb2919355-x64_e6f4da4d33564419065a7370865faacf9b40ff72.msu
Не успел я его поставить, потому что сел пить чай с пирожными, как Win update выдала – вам надо поставить 112 важных обновлений, и 5 не очень важных.
Самое большое - Update for Windows Server 2012 R2 (KB3000850) от 4/14/2015 и затем
2023-01 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5022352)
Нажал кнопку «давай обновляйся» и отправился дальше по делам – пускай работает железный паровоз автоматизация.
Обновил, обновил еще раз, еще раз перезагрузил.
Сделал $Hotfix = get-hotfix ; $Hotfix.count
Всего поставилось 124 обновления, включая не обязательные.
Посмотрел
(Get-ItemProperty -Path c:\windows\system32\hal.dll).VersionInfo.FileVersion
6.3.9600.20512 (winblue_ltsb_escrow.220711-1746)
Посмотрим, что там наставилось.
Get-HotFix | Sort-Object -Property HotFixID -Descending
Первым номером идет
2023-09 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5030329), вторым -
2023-01 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5022352)
Так, а что насчет
2024-10 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5044411)?
главное, не спутать его с
2024-10 Servicing Stack Update for Windows Server 2012 for x64-based Systems (KB5044413)
Я спутал.
Поищем:
2024-12 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5048735)
Get-HotFix | Where-Object { $_.HotFixID -like 'KB50*'}
Индейская национальная народная изба, а не KB5044411

Индейская национальная народная изба
Есть только эти два
2023-09 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5030329)
2023-01 Security Monthly Quality Rollup for Windows 8.1 for x64-based Systems (KB5022352)
так что фильтр Where-Object работает, но обновлений нет.
Ладно, что там после
2023-01 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5022352) ?
2023-02 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5022899)
Скачаю.
2023-02 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5022899)
windows8.1-kb5022899-x64_00d16db3cfda0f18dc89755faebb4aa12aba2cc7.msu
И, чтобы сразу проскочить до сентября 2023, как SSU, скачаю
2023-09 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5030269)
windows8.1-kb5030269-x64_4f5c3c75b71207ef100ce60f2ad8683e22eb20b0.msu
Ставить его (2023-02 KB5022899) лучше из IPMI или VM консоли – потому что вот установка запустилась, вот предложила перезагрузку – и дальше ничего. На экране VM консоли ничего не происходит, CTRL-ALT-DEL не проходит, и минут 5 (у меня на тесте) только часы идут.
Ставим, смотрим и …
Get-HotFix | Where-Object { $_.HotFixID -like 'KB502289*'}
показывает ничего, зато
Get-HotFix | Where-Object { $_.HotFixID -like 'KB50*'}
показывает, что я немного ошибся – в системе есть
2023-10 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5031419)
Вот так фокус. Ставил 2023-02 KB5022899, а появились:
2023-10 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5031419)
2023-10 Security and Quality Rollup for .NET Framework 4.8 for Windows Server 2012 R2 for x64 (KB5031003)
Причем, похоже, это не я его поставил посреди ночи, а Windows update.
Хотя он и писал, что обновлений больше нет, но они все же есть. Не очень понятно как так вышло.
Мне бы на этом месте сделать скриншот и снапшот, но я не сделал.
После
2023-09 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5030329), идет
2023-11 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5032308)
И он, внезапно, ставится. Но, после установки проверим – все ли на месте.
Get-HotFix | Where-Object { $_.HotFixID -like 'KB5032*'}
Что насчет 2023-11 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5032249) ?
Не хочу проверять. Сначала поставлю:
2024-01 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5034587) – поставилось
2024-02 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5034866) – поставилось
2024-03 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5035968) – поставилось
Прыгну сразу к
2024-10 Servicing Stack Update for Windows Server 2012 R2 for x64-based Systems (KB5044411) – поставилось
Посмотрим что получилось:
Get-HotFix | Sort-Object -Property HotFixID -Descending | Select-Object -First 10
Вроде, все на месте.
Завершающий этап, пробую:
2024-12 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5048735)
Еще раз: ставить его (2024-12 KB5048735) лучше из IPMI или VM консоли – потому что вот установка запустилась, вот предложила перезагрузку – и дальше ничего. На экране VM консоли ничего не происходит, CTRL-ALT-DEL не проходит, и минут 5 (у меня на тесте) только часы идут.
Ставилось обновление как-то настолько долго, зависнув на 96%, что я не стал следить за скоростью процесса. Что-то прошло, произошло, но потом
Get-HotFix | Sort-Object -Property HotFixID -Descending | Select-Object -First 10
KB5044411 на месте, KB5048735 отсутствует.
Согласно
C:\Windows\Logs\CBS\CBS.log
Где-то до строки 13350 –
00000253 Begin executing advanced installer phase 40 (0x00000028) index 276
Все шло нормально. Даже до строки 13450 -
00000261 Begin executing advanced installer phase 50
CSI 00000262@2025 () Executing Process [76]"C:\Windows\Microsoft.NET\Framework\v4.0.30319
И потом оп, и откат обновления.
Исследование завершено.
Проблема подтверждена, что делать – не понятно. В обычной статье я бы сразу написал, какой я умный и сразу все понял, но это не так.
Попробую ставить подряд.
Установлено: 2023-10 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5031419)
Следующий патч:
2023-11 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5032249)
Ставлю ставлю, ставится, рестарт, задумалось на 90% и откат обновлений. Запомним эту цифру, 90%
Отрицательный результат – тоже результат.
Ставить все подряд –не работает. Придется читать, что там в логе.
Читаем логи.
Тут нам Notepad++ и пригодится. Открываем C:\Windows\Logs\CBS\CBS.log
Логи у меня были и 35 мб, и 128 мб. Чистого текста. В логе все хорошо:
98000 примерно строка:
Exec: Staging Package: Package_3148_for_KB5032249~31bf3856ad364e35~amd64~~6.3.1.8, Update: 5032249-5445_neutral
000005d8 Performing 256 operations; 256 are not lock/unlock and follow:
Потом 118000
Exec: Package: Package_568_for_KB5032249~31bf3856ad364e35~amd64~~6.3.1.8 is already in the correct state
Exec: Package: Package_2191_for_KB5032249~31bf3856ad364e35~amd64~~6.3.1.8 is already in the correct state, current: Installed
Exec: Package: Package_2886_for_KB5032249~31bf3856ad364e35~amd64~~6.3.1.8 is already in the correct state, current: Installed, targeted: Installed
Exec: The Package or one of its Updates required a reboot so transaction commit was skipped, Package's changes need to be pended
Строка 123000
CBS Setting ExecuteState key to: ExecuteStateNone
Setting RollbackFailed flag to 0
И, наконец, перезагрузка
Trusted Installer signaled for shutdown, going to exit.
CBS Doqe: System reboot required
CBS Perf: Doqe: Install ended.
CBS Doqe: q-uninstall: Inf: ntprint4.inf
CBS Perf: Doqe: Uninstall ended.
CBS Progress: UI message updated. Operation type: Update. Stage: 1 out of 1. Percent progress: 30.
Old component: [ml:364{182},l:362{181}]"Microsoft-Windows-SLC-Component-ExtendedSecurityUpdatesAI, Culture=neutral, Version=6.3.9600.21620, PublicKeyToken=31bf3856ad364e35, ProcessorArchitecture=amd64, versionScope=NonSxS"
New component: [ml:364{182},l:362{181}]"Microsoft-Windows-SLC-Component-ExtendedSecurityUpdatesAI, Culture=neutral, Version=6.3.9600.21668, PublicKeyToken=31bf3856ad364e35, ProcessorArchitecture=amd64, versionScope=NonSxS"
Install mode: uninstall
И где-то в районе 125500 строки:
CSI 00000002 ESU: Product = 8.
CSI 00000003 ESU: Windows is not activated.
00000007 ESU: Network Retry Counts : 30 (0x0000001e)
CBS Progress: UI message updated. Operation type: Update. Stage: 1 out of 1. Percent progress: 90.
На этом месте Штирлиц сунул руку в карман и подумал: это конец
00000024 ESU: Trying to Check IMDS Again LastError=HRESULT_FROM_WIN32(12002).
Startup: Timed out waiting for startup processing to complete
Это уже можно гуглить,
No Updates for 2012 R2 Servers activated with ESU activated through Azure Arc
If installing the Extended Security Update enabled by Azure Arc fails with errors such as "ESU: Trying to Check IMDS Again LastError=HRESULT_FROM_WIN32(12029)" or
"ESU: Trying to Check IMDS Again LastError=HRESULT_FROM_WIN32(12002)",
there is a known remediation approach:
Download this intermediate CA published by Microsoft.
Install the downloaded certificate as Local Computer under Intermediate Certificate Authorities\Certificates. Use the following command to install the certificate correctly:
certutil -addstore CA 'Microsoft Azure TLS Issuing CA 01 - xsign.crt'
Install security updates. If it fails, reboot the machine and install security updates again.
Troubleshoot delivery of Extended Security Updates for Windows Server 2012
Option 2: Manually download and install the intermediate CA certificates
If you're unable to allow access to the PKI URL from your servers, you can manually download and install the certificates on each machine.
Сертификаты я поставил, инсталл, ребут – а все равно, 90% ..
Just to bump this.... Issue popped up again this month. After a case with MSFT, had to install the Microsoft Azure RSA TLS Issuing CA 04 with thumbprint BE68D0ADAA2345B48E507320B695D386080E5B25 from Azure Certificate Authority details | Microsoft Learn
Читаем это и это, и, наконец, выходим на: Windows Server 2012/R2: Extended Security Updates
Download and install the Extended Security Updates (ESU) Licensing Preparation Package.
For Windows Server 2012 R2 or Windows Server 2012 R2 Embedded, see the Extended Security Updates (ESU) Licensing Preparation Package that is dated August 10, 2022 (KB5017220).
Все понятно. Расширенная поддержка «для всех» закончилась:
Extended End Date - Oct 10, 2023.
Поэтому последние патчи «для всех» -
2023-10 Security Monthly Quality Rollup for Windows Server 2012 R2 for x64-based Systems (KB5031419)
2023-10 Security and Quality Rollup for .NET Framework 4.8 for Windows Server 2012 R2 for x64 (KB5031003)
Чтобы работало остальное, вам нужен 2022-08 Extended Security Updates (ESU) Licensing Preparation Package for Windows Server 2012 R2 for x64-based Systems (KB5017220) и внимательное чтение статьи How to get Extended Security Updates (ESU) for Windows Server.
Дальше просто. Берем сначал укропу Ставите апдейт для Updates (ESU) Licensing Preparation. Ставите 4 новых сертификата по статье выше. Прописываете отдельно продаваемый ESU key из личного кабинета Microsoft Volume Licensing Service Center (VLSC), немного магии, охапка дров и патч готов.
Если у вас есть деньги и VLSC, конечно.
Если нет, то вам сюда или сюда.
Massgrave не проверял.
Напоминаю:
Windows Server 2016 Mainstream End Date - Jan 11, 2022.
Windows Server 2019 Mainstream End Date - Jan 9, 2024.
Переходите, кто не перешел, и кому надо, переходите на хотя бы
Windows Server 2022 – он будет поддерживаться еще полтора года.
Сбоев по маршрутам \ BGP и сбоев на стыках провайдеров с внешними интернетами не отмечено.
Изнутри РФ, судя по данным коллег, работали:
телеграмм
не шифрованный DNS
SSH трафик
ping
все VPN
вконтакт (почему-то).
РТК и Билайн сообщили "это не мы".
