Оценка производительности PostgreSQL - одного сценария НЕДОСТАТОЧНО

До финиша дойдут не все...
Проблема
ВМ с гораздо большими вычислительными ресурсами показывает скорость ниже , чем более скромная ВМ .
Причина
По умолчанию pgbench тестирует сценарий, примерно соответствующий TPC-B, который состоит из пяти команд SELECT, UPDATE и INSERT в одной транзакции.
Для тестирования использовался именно этот сценарий .
Конфигурация виртуальных машин
ВМ-1
Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 11.4.1 20230605 (Red Soft 11.4.0-1), 64-bit
CPU = 8
RAM = 15
OC = RED 7.3
ВМ-2
Postgres Pro (enterprise certified) 14.11.3 on x86_64-pc-linux-gnu, compiled by gcc (Debian 6.3.0-18+deb9u1) 6.3.0 20170516, 64-bit
CPU = 24
RAM = 189
ОС = Astra Linux (Smolensk) 1.6
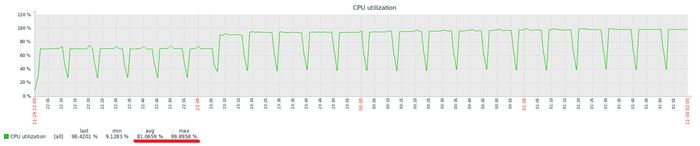
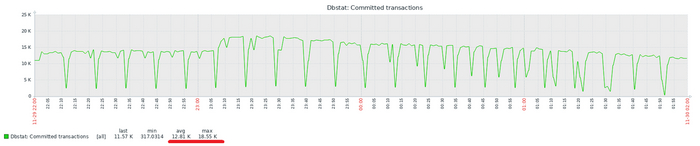
Итоги теста по сценарию TPC-B
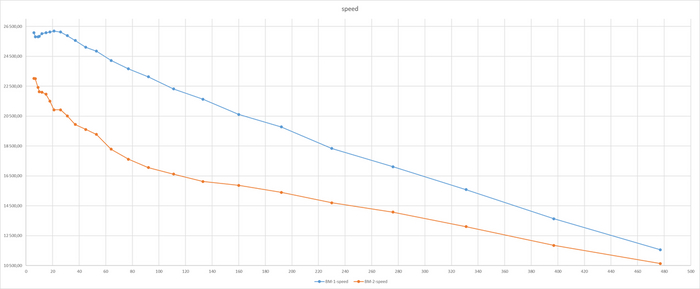
Производительность ВМ-1 существенно выше ВМ-2
Т.е. по итогам данного теста получается - СУБД развёрнутая по шаблону ВМ-1 будет существенно производительнее ?
Что будет , если архитектор примет решение о выборе версии СУБД и запланирует ресурсы инфраструктуры на основании только данного теста ?
Решение проблемы
Одного теста для анализа производительности СУБД и ВМ - недостаточно.
Как было указано в документации:
Однако вы можете легко протестировать и другие сценарии, написав собственные скрипты транзакций.
Что и было сделано.
Для продолжения тестов, был подготовлен сценарий требующий серьезных вычислительных ресурсов - SELECT ... JOIN
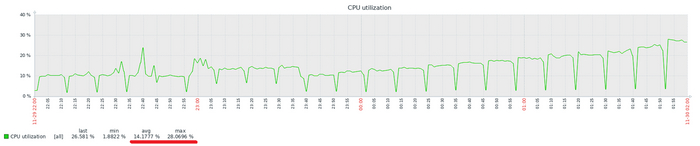
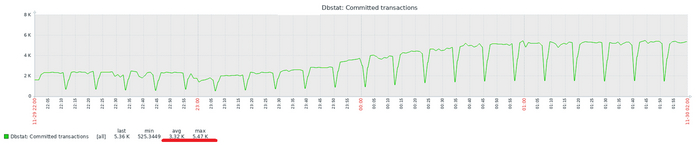
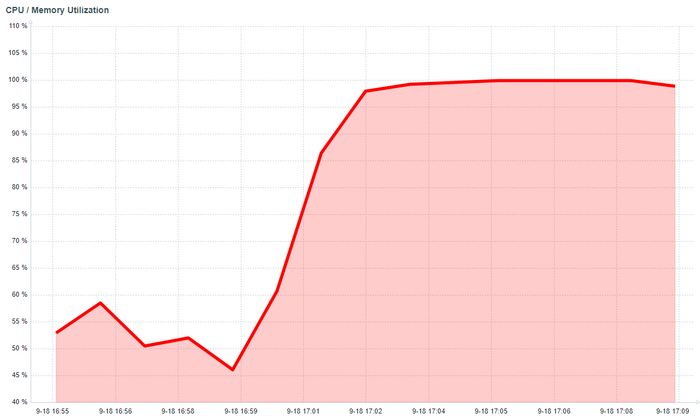
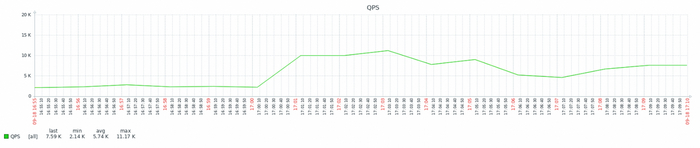
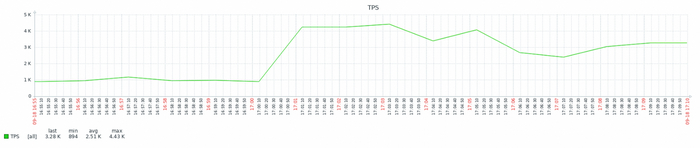
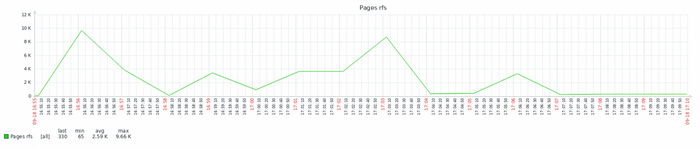
Результат тестирования тяжелого запроса
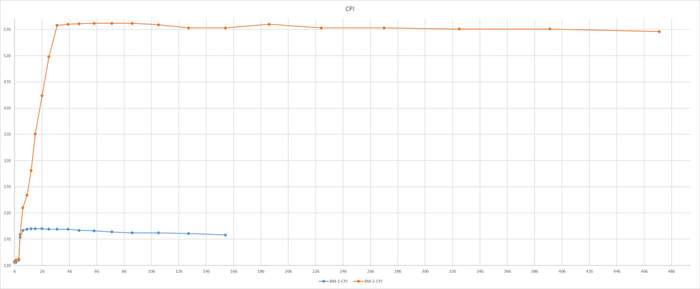
ВМ-2 СУЩЕСТВЕННО производительнее чем ВМ-1
Все встало на свои места.
ВМ-1 даже не хватило ресурсов при количестве одновременных запросов свыше 160. При этом производительности ВМ-2 существенно выше производительности ВМ-1.
Итог
Нельзя принимать архитектурных решений на основании результатов одного только сценария нагрузочного тестирования
2. Для оценки производительности архитектурного решения по конкретной СУБД необходим комплекс разных сценариев нагрузочного тестирования.
Как минимум:
-Select only: оценка скорости чтения данных из СУБД
-Standard: оценка производительности СУБД в условиях конкуренции за блокировки.
-Heavyweight: оценка производительности СУБД при выполнении тяжелых вычислительных и ресурсоемких операций.