Как работает фрагментация пакетов в IP (на примере тестов iPerf3)
В этом посте поговорим про фрагментацию пакетов, разберемся как она работает и почему она не выгодна никому: ни хостам, ни маршрутизатором, сначала будет немного теории, а затем воспользуемся генератором пакетов и посмотрим дампы.
Что такое фрагментация?
Из разговора про MTU мы помним четыре момента:
Минимальный размер кадра 64 байт.
MTU по умолчанию в Ethernet сетях 1500 байт.
Кадры могут быть гораздо больше чем 1500 байт.
MTU параметр настраиваемый и не факт, что на всех линка будет настроен MTU, который будет пропускать пакеты, генерируемые отправителем.
Это некие вводные ограничения, которые нам дает Ethernet. IPv4 к этим ограничением добавляет то, что узел получатель должен гарантировать всем своим соседям, что он может принять IP-пакет размером 576 байт, а узел в IPv6 должен уметь обрабатывать пакеты размером 1280 байт.
С учетом вышеописанного легко можно представить две ситуации, в которых может начать работать фрагментация :
Хосты согласовали обмен пакетами 1500 байт (на самом деле они согласовали TCP или SCTP MSS), но на сети есть линк или линки, где MTU меньше 1500 байт.
Хосты генерируют пакеты размером более 1500 байт, а на транзитных узлах MTU равен 1500 байт.
Эти ситуации можно решить за счет хостов, им просто нужно генерировать такие пакеты, которые пролезут через любой линк на сети, проблема в том, что хосты не знают MTU на всей сети и обычно надеются, что MTU всей сети не меньше, чем MTU их интерфейсов, которые в эту сеть включены, но есть и другие варианты решения:
Транзитное устройство может уведомить отправителя о том, что тот генерирует слишком большие пакеты и, если отправителю не запрещено, то он может начать генерировать пакеты меньшего размера.
Транзитный узел может не уведомлять отправителя о том, что тот генерирует большие пакеты, а начать самостоятельно разбивать их на такие пакеты, которые гарантированно пройдут через линк. Это и есть фрагментация.
Слишком большие пакеты могут просто уничтожаться, но нам этот вариант не очень интересен.
Стоит понимать, что фрагментация пакетов явление вынужденное и не очень желательное, единственное достоинство фрагментации заключается в следующем: если приложения не заботятся о размерах передаваемых данных, то это делает IP, чтобы хоть каким-то образом, но связь между отправителем и получателем поддерживалась.
Минусов у фрагментации много, вот три основных на мой взгляд:
При потере одного из фрагментов можно считать, что теряется весь исходный пакет.
Фрагментация повышает нагрузку на устройства сети.
В некоторых случаях при сборке фрагментированного пакет может быть нарушена целостность передаваемых данных.
Вот несколько ссылок, где вы можно больше узнать о проблемах, фрагментации, все на ин-язе: RFC 4963, Fragmentation Considered Harmful, RFC 8900.
Поля IP заголовка для управление фрагментацией
В IP заголовке имеется четыре поля, которые так или иначе используются при фрагментации.
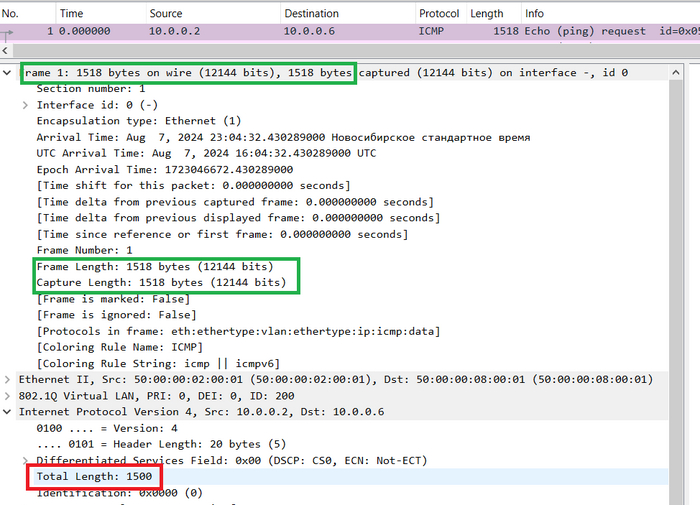
Размер пакет (Total Lenght). В этом поле хранится полный размер пакета в байтах, т.е. заголовка плюс поля данных.
Идентификатор (Identification). Это поле помогает принимающей стороне собрать исходный пакет из полученных фрагментов, у фрагментов, которые являются частями одного исходного пакета, значение этого поля будет одинаковым.
Флаги (Flags). Под каждый флаг выделен один бит, нумерация начинается с нуля. Нулевой бит(нулевой флаг) нам не интересен, первый бит называется DF или do not fragment, если значение этого бита равно единицы, то пакет фрагментировать запрещено, если возникает ситуация когда у пакета DF = 1 и размер больше допустимого MTU, такой пакет уничтожается(некоторые устройства игнорируют бит DF и всё равно выполняют фрагментацию). Второй флаг называется MF или more fragments, он используется для того, чтобы обозначить конец последовательности фрагментированных пакетов, пока MF = 1 узел получатель будет ожидать новые фрагменты, как только придет пакет с MF = 0, получатель поймет, что последовательность фрагментированных пакетов закончилась.
Смещение фрагмента (Fragment Offset). IP не гарантирует того, что получатель будет получать пакеты в той же последовательности, в которой их генерировал отправитель. В случаях, когда фрагментации нет, проблема собрать всё в нужной последовательности это проблема вышестоящего процесса или протокола, но если получатель принял фрагментированную последовательность, задача собрать исходных пакет из фрагментов ложится на IP процесс, поле смещение помогает понять в какой последовательности надо собирать исходный пакет. Данное поле хранит численное значение, одна единица этого числа равна восьми байтам.
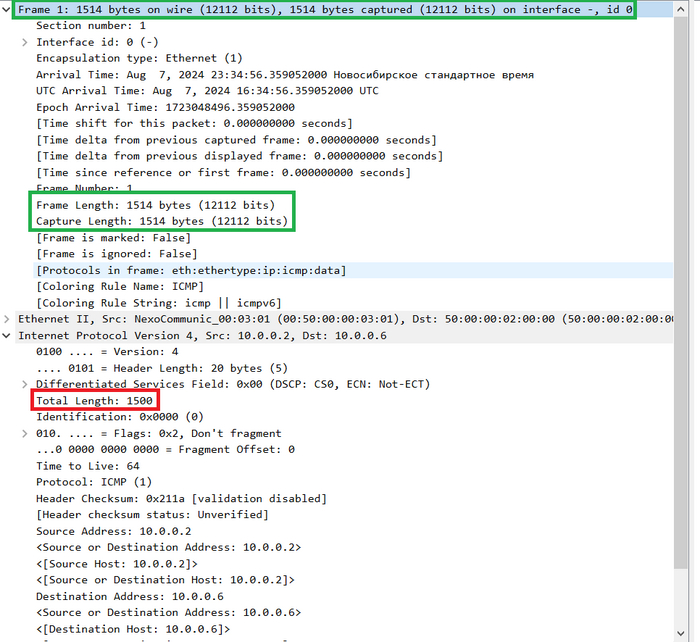
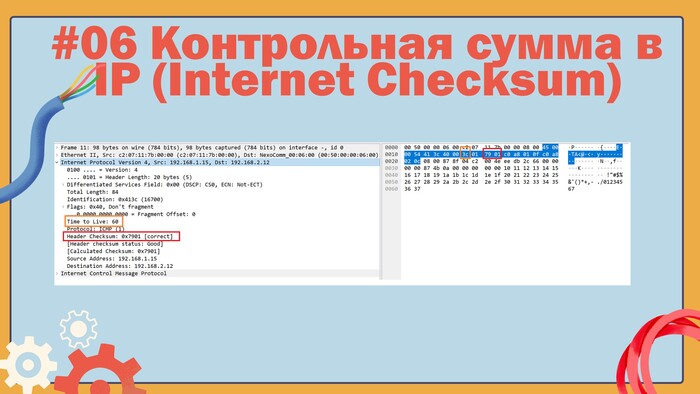
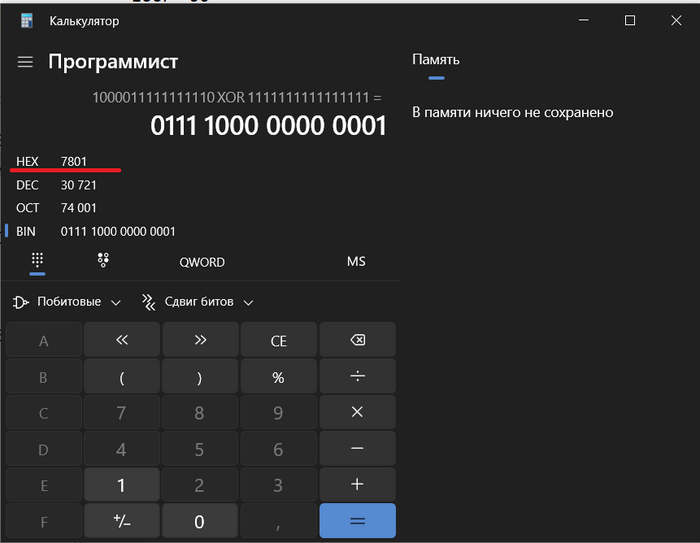
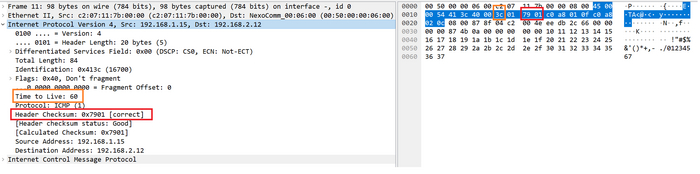
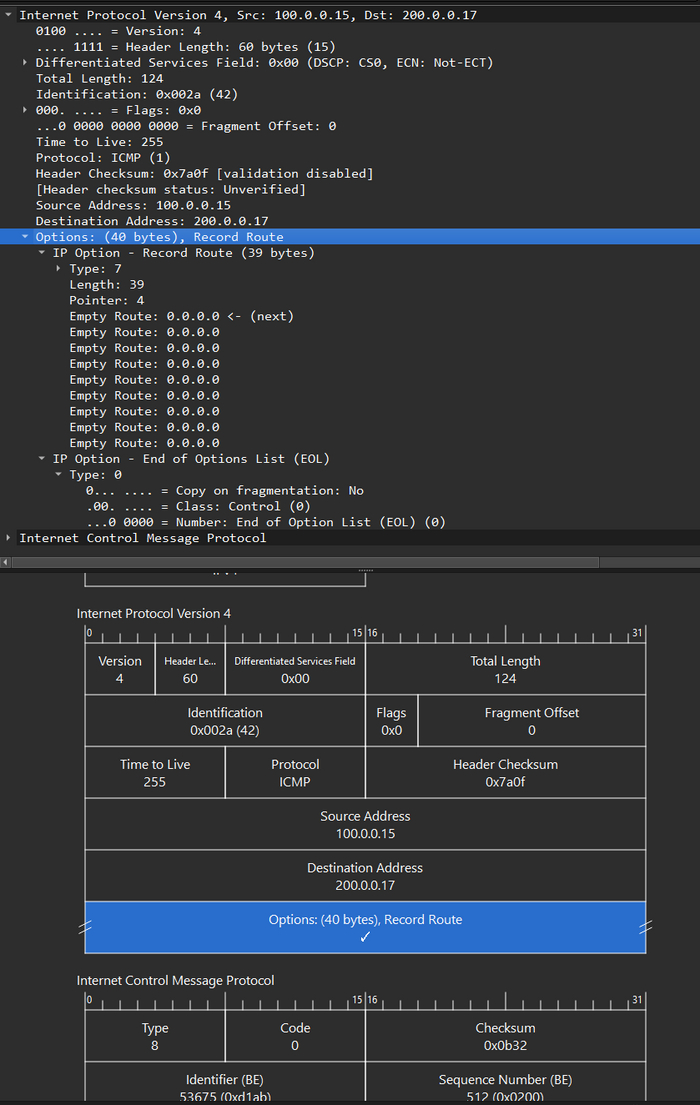
Вот так эти поля выглядят в дампе Wireshark.
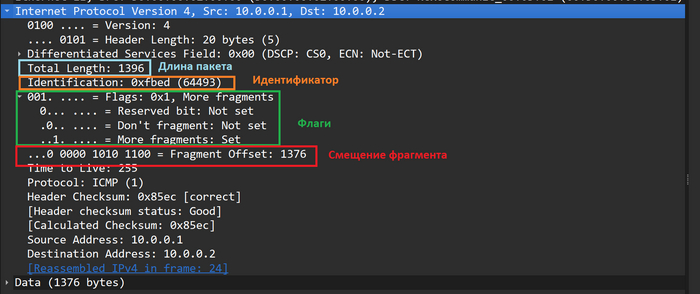
Поля фрагментированного пакета:Total Length, Identification, Flags, Fragment Offset в дампе Wireshark

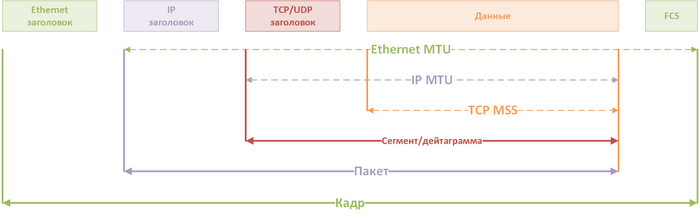
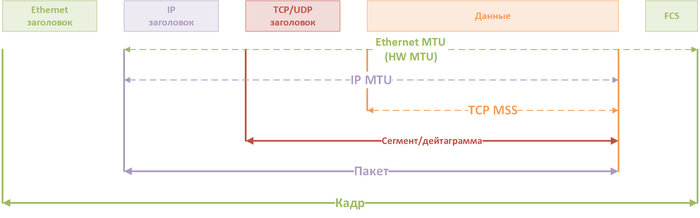
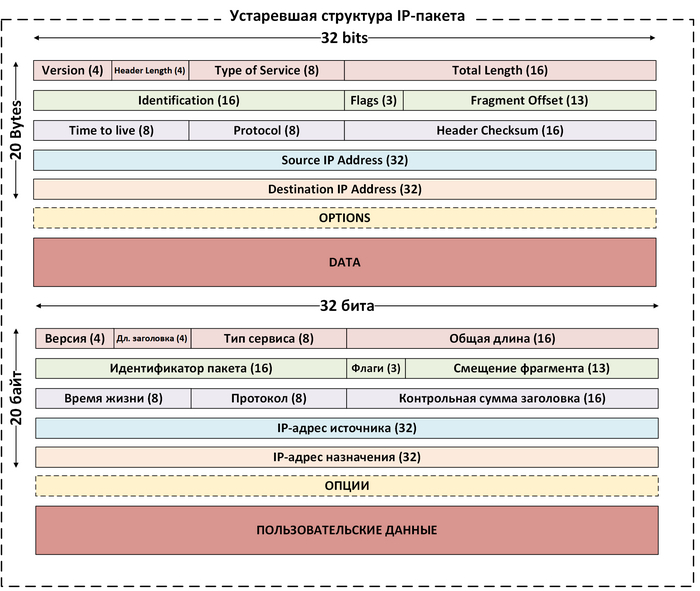
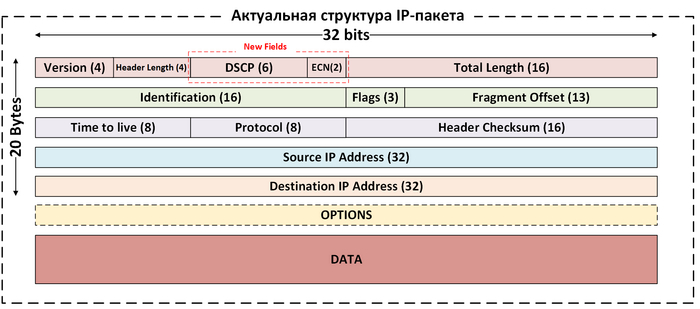
Структура IP-пакета
Цвета на двух картинках выше соответствуют.
Смещение фрагмента в IP
Стоит отдельно остановиться на поле Fragment Offset, его размер 13 бит, то есть максимальное значение этого поля 8191, но весь вопрос в том, какие единицы измерения используются для смещения фрагмента, если в этом поле стоит значение 1, то это означает, что сдвиг надо делать на 8 байт, то есть максимально возможное смещение 65528 байт.
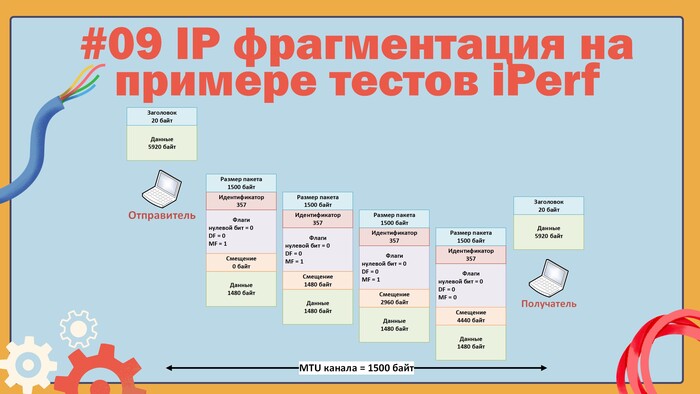
Проще всего разобраться с вопросом смещения можно будет на примере, допустим, у нас есть два хоста, соединенных каналом с MTU 1500 байт, но хосты хотят обмениваться пакетами размером 5940 байт, в этом случае будет включаться механизм фрагментации, и каждый исходный пакет будет разделен на четыре пакета по 1500 байт, чтобы они гарантированно прошли через канал, смещение первого фрагментированного пакета будет равно нулю, у второго пакета оно уже будет 1480 байт, третий пакет будет иметь смещение 2960 и последний пакет будет со смещением 4440 байт, все описанное выше представлено на рисунке.
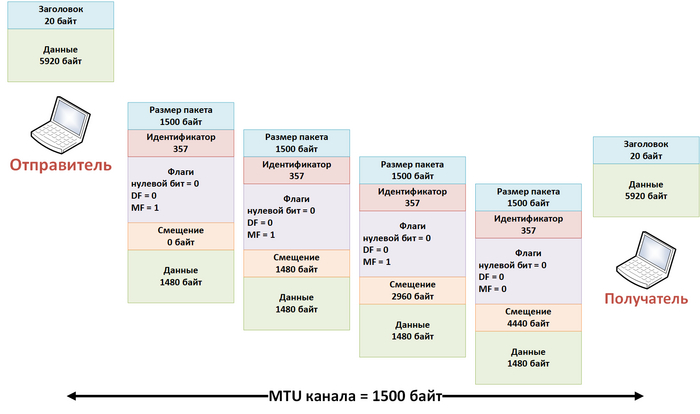
Пример работы фрагментации IP пакетов
Для удобства я пересчитывал единицы измерения смещения в байты.
Из примера понятно, что фрагментация это лишняя работа не только для транзитных узлов, которые ее выполняют, но и для хостов. Также в примере виден смысл поля ID и флага MF, по ним получатель понимает, что это не конец фрагментированной последовательности, но получатель заранее не знает размер исходного пакета.
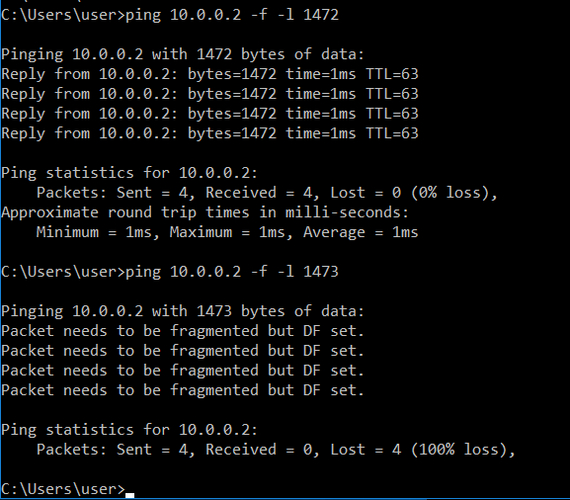
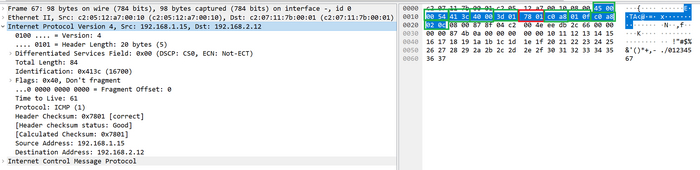
В качестве проверки и подтверждения сказанного ранее я сделал пинг пакетам с размером, как в примере выше, и снял дамп, важно, чтобы MTU линков был равен 1500 байт чтобы получилось как в примере.
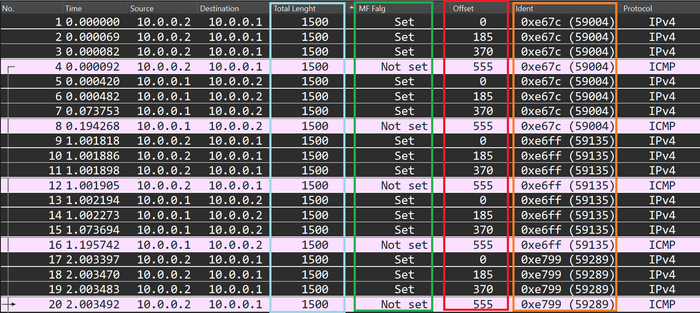
Пример фрагментированных пакетов в дампе Wireshark
Интересные столбцы выделены цветами:
голубой = размер пакета
зеленый = наличие флага MF
красный = смещение
оранжевый = идентификатор
Строки выделять не стал, поскольку розовая строка здесь означает конец фрагментированной последовательности. Плюс важно учитывать, что на этом скрине в столбце Offset значение смещения не в байтах.
Установка iPerf3 на Linux и в Windows
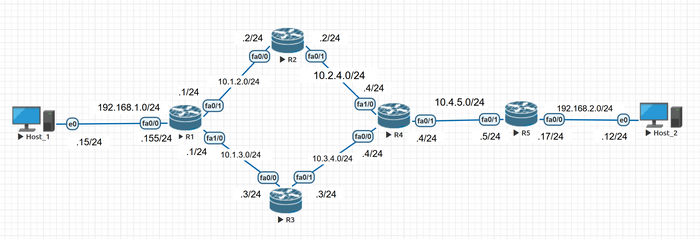
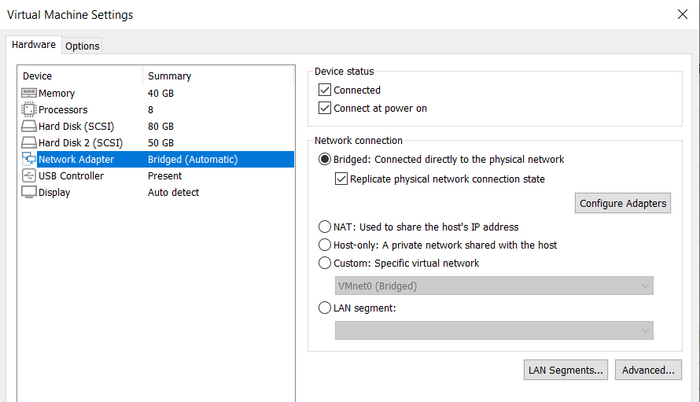
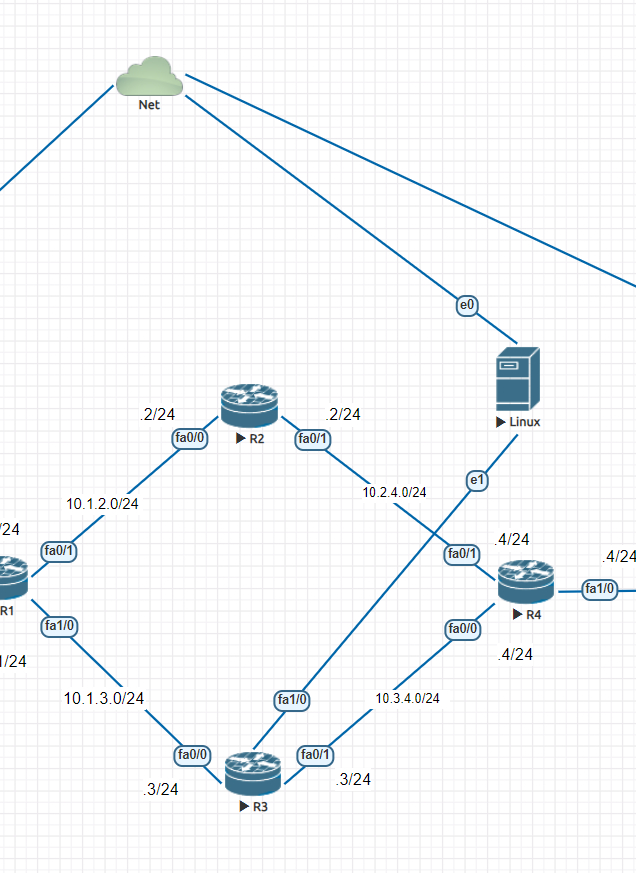
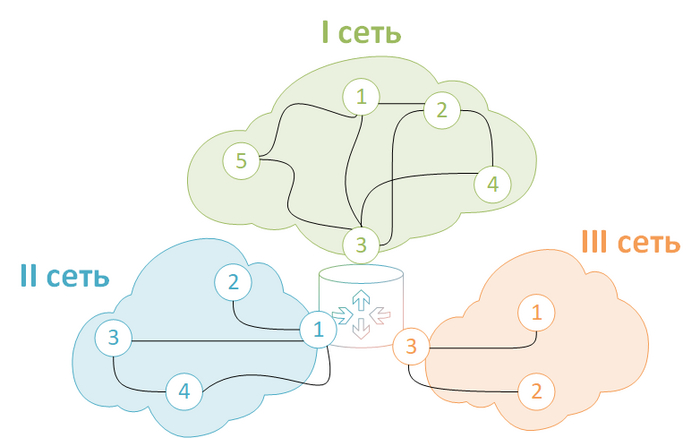
Перейдем к практике, тренироваться будем на той же лабе, которая использовалась в посте про MTU. Вот топология сети:
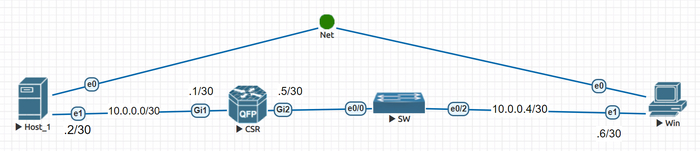
Топология сети лабы
Далее будет краткий гайд по установке и использованию iPerf в Linux и Windows, кому этот момент очевиден, можно смело пропускать.
Iperf представляет собой простой кросс-платформенный генератор трафика, у него есть две версии: вторая и третья, второй никогда не пользовался и чем она отличается от третьей не знаю. Iperf является клиент-серверным приложением.
Iperf это утилита командной строки в Windows, установка его здесь довольная простая, скачиваете архив по этой ссылке, выбирайте самую свежую версию, она внизу. Внутри полученного архива будет папка с именем iperf+номер_версии_разрядность_ОС:

Архив с iPerf3
Если хотите, можете скинуть эту папку в любое удобное вам место и на этом установка будет завершена. Я же создам в корне диска C папку с именем iperf3 и скопирую в него содержимое папки "iperf3.17_64.", так будет проще:

Установленный iPerf3
При желании можете добавить путь к файлу iperf3.exe в переменную PATH, тогда для запуска программы не придется каждый раз в командной строке переходить по пути C:\iperf3 чтобы запустить программу.
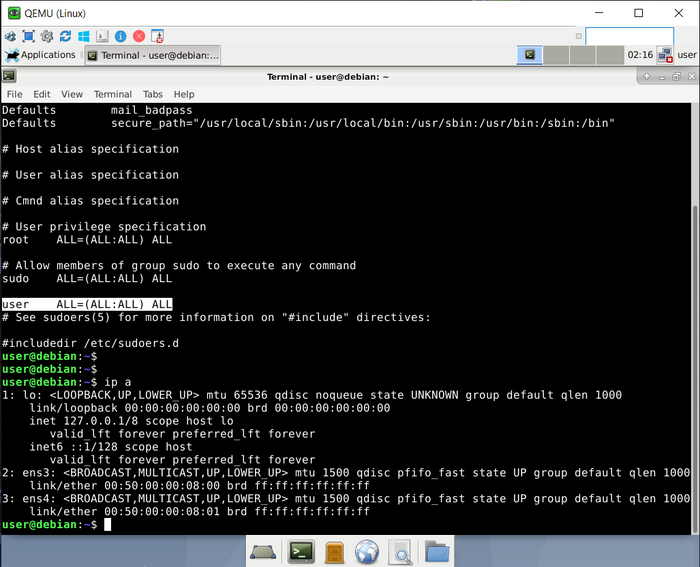
Установку в Linux буду показывать на примере Debian 10, пишем две команды:
sudo apt update&&upgrade -y
sudo apt install iperf3
В других дистрибутивах команды могут отличаться, в команде на установку iperf тройку после iperf пишем обязательно, иначе установится вторая версия.
Примечание
В репозитории дистрибутива, который вы используете, может находиться пакет не с самой последней версией iPerf, в моем случае вопрос версии не принципиален, нам просто надо посмотреть на работу фрагментации, но если вы планируете использовать его для тестов своих каналов, учитывайте два момента: тесты, выполненные на iperf разных версий, могут не показать реальной картины (обычно результаты хуже чем есть на самом деле), в разных версиях есть разные баги, влияющие на результаты тестирования. Microsoft же вообще не рекомендует использовать iPerf для тестов в Windows.
Как запустить тест скорости iPerf
Запустить тест скорости в iPerf дело не хитрое, начнем с сервера. Запуск сервера делается так:
iperf3 -s

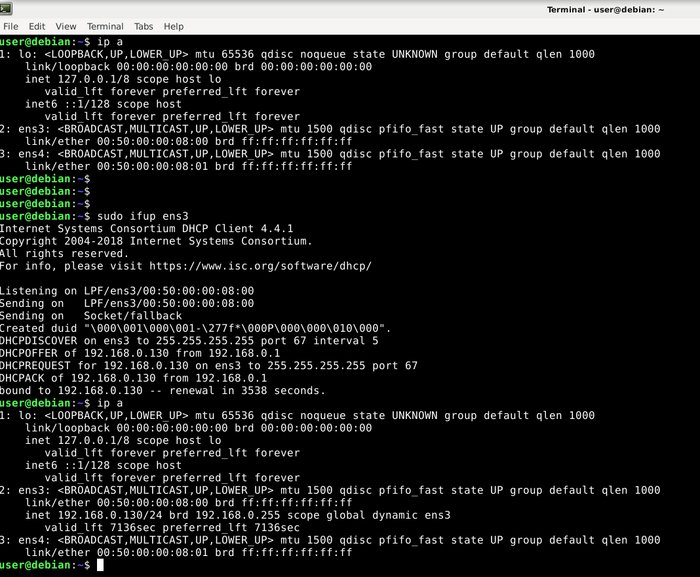
Запущенный сервер iPerf в Linux
Сервер ожидает запросы от клиента на порт 5201 любого из транспортных протоколов: TCP, UDP, SCTP. Если у вас используется firewall, убедитесь что порт открыт.
Клиента iperf будем запускать в Windows, для этого нужно запустить командую строку желательно от имени администратора, перейти в папку, где лежит exe файл (переходить никуда не надо будет, если добавить путь к iperf3.exe в переменную PATH):
C:\Windows\system32>cd c:\iperf3
c:\iperf3>iperf3.exe -c 10.0.0.2 -f k -M 1300
Connecting to host 10.0.0.2, port 5201
[ 5] local 10.0.0.6 port 49786 connected to 10.0.0.2 port 5201
[ ID] Interval Transfer Bitrate
[ 5] 0.00-1.01 sec 256 KBytes 2079 Kbits/sec
[ 5] 1.01-2.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 2.01-3.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 3.01-4.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 4.01-5.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 5.01-6.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 6.01-7.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 7.01-8.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 8.01-9.01 sec 0.00 Bytes 0.00 Kbits/sec
[ 5] 9.01-10.01 sec 0.00 Bytes 0.00 Kbits/sec
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate
[ 5] 0.00-10.01 sec 256 KBytes 210 Kbits/sec sender
[ 5] 0.00-14.04 sec 97.8 KBytes 57.0 Kbits/sec receiver
iperf Done.
c:\iperf3>
Опции для разных ОС одинаковые, пользователи Linux могут получить справку при помощи утилиты man, в Windows можно написать iperf3.exe -h, но лучше обратиться к документации. Опции iperf делятся на серверные, клиентские и универсальные.
Теперь по поводу команды в Windows: -c говорит о том, что iperf запускается в режиме клиента, при этом данной опции надо передать IP-адрес сервера. Опция -f k говорит iperf о том, что скорость должна быть отображена в kbps, а -M 1300 задает размер TCP MSS 1300 байт.
Учитывайте, что какой бы протокол вы не использовали, iperf выставить df-bit = 1 и это никак не изменить, насколько мне известно, и это нужно учитывать при дальнейших тестах, плюс по умолчанию iperf генерирует пакеты только в одну сторону: от клиента к серверу. На сервере статистика тоже отображается, вот статистика для соединения, которое мы инициировали командой, выполненной выше в Windows:
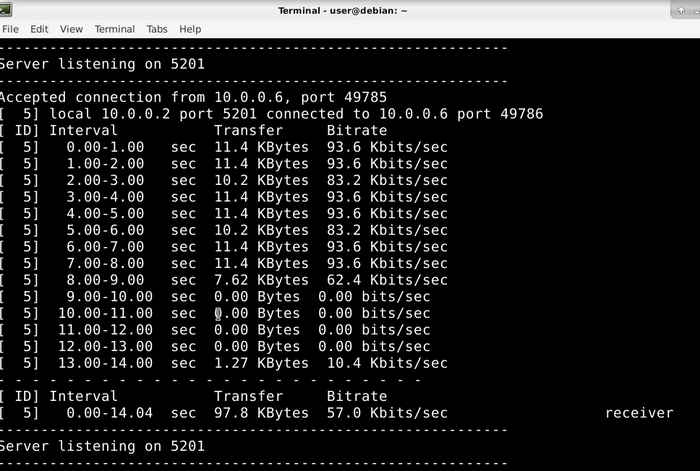
Статистика теста скорости iperf на Linux сервере
Более детальную информацию о тесте можно получать, если использовать опцию -V на клиенте и сервере.
Как убрать df-bit у транзитного IP-пакета на роутере Cisco
Пожалуй, самый плохой сценарий для маршрутизатора в вопросах фрагментации, это когда маршрутизатор выполняет эту самую фрагментацию. Выше я не случайно написал про df-bit, который iPerf всегда выставляет на генерируемые им пакеты. С выставленным df-bit мы фрагментацию никогда не увидим, значит, его надо обнулить, как это сделать средствами Windows я не знаю и тратить время на то, чтобы с этим разобраться я не захотел, а вот на роутерах Cisco можно написать route-map и навешать этот route-map на интерфейс, в который будут входить пакеты с установленным df-bit, который мы хотим обнулять.
Примечание
Для тех, кто читал пост про MTU. В той лабе на интерфейсе CSR в сторону коммутатора был создан саб-интерфейс Gi2.200, на нем и был настроен IP-адрес, сейчас же саб-интерфейс Gi2.200 удален, IP-адрес перенесен на Gi2, а на линке CSR/SW кадры ходят без вланов.
Создать route-map можно, например, такой:
CSR#conf t
CSR(config)#route-map RM_DEL-DF-BIT permit 10
CSR(config-route-map)#match ip address 101
CSR(config-route-map)#set ip df 0
CSR(config-route-map)#exit
CSR(config)#access-list 101 permit tcp 10.0.0.0 0.0.0.255 any
Строка set ip df 0 как раз и заставляет обнулять df-bit, а RM_DEL-DF-BIT это просто имя route-map, которое я ей придумал. Роут-мапу нам надо повешать на интерфейс Gi2, поскольку пакеты с df-bit, который мы хотим обнулять, будут входить именно в интерфейс (если бы остался саб-интерфейс Gi2.200, то тогда вешать надо было бы на него). Делается это так:
CSR#conf t
CSR(config)#int gi2
CSR(config-if)#ip policy route-map RM_DEL-DF-BIT
И давайте зададим IP MTU 1300 байт на интерфейс Gi1:
CSR#conf t
CSR(config)#int gi1
CSR(config-if)#ip mtu 1300
Всё, лабу подготовили.
Как работает фрагментация IP пакетов на роутере
Наконец-то мы добрались до самой фрагментации. Запустим iperf на Винде(команда iperf3.exe -c 10.0.0.2 -f k -M 1370) и снимем дампы:
Первый с линка между SW/Win, здесь будут идти не фрагментированные пакеты с TCP MSS 1370 байт, это уже больше чем MTU интерфейса Gi1, но к значению MSS нужно будет добавить еще размеры заголовков TCP и IP.
Второй дамп будем делать с линка Host_1/CSR. Здесь мы сможем увидеть фрагментированные пакеты, видя два дампа, мы сможем сделать вывод о том, что фрагментацию выполняет именно роутер.
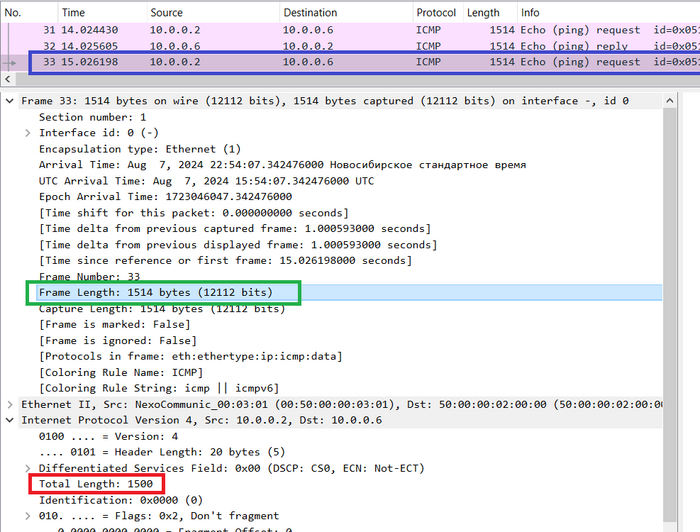
Важно найти один и тот же пакет как в первом, так и во втором дампе, проще всего это сделать по идентификатору пакета. Вот пакет с номером 2e8b на линке SW/Win:

Не фрагментированный пакет размером 1410 байт
Размер пакета 1410 байт, df-bit = 1. А вот этот же пакет на линке Host_1/CSR:

Роутер разделил исходный пакет и теперь вместо одного пакета 1410 байт у нас два пакета размером 1430 байт
Во-первых, пакетов два: 1300 байт и 130 байт, а это больше изначальных 1410, уже неприятно, особенно, если счёт будем вести на миллионы. Во-вторых, видим, что пакеты, которые идут в сторону Debian, имеют df-bit = 0, из увиденного делаем выводы:
Route-map работает, CSR снимает df-bit и делает фрагментацию.
Фрагментацию выполняет роутер.
Не вижу сейчас особого смысла смотреть внутрь пакета, т.к. все интересующие нас поля я вывел в дамп, но если что, вот пакет, который генерировала Винда:
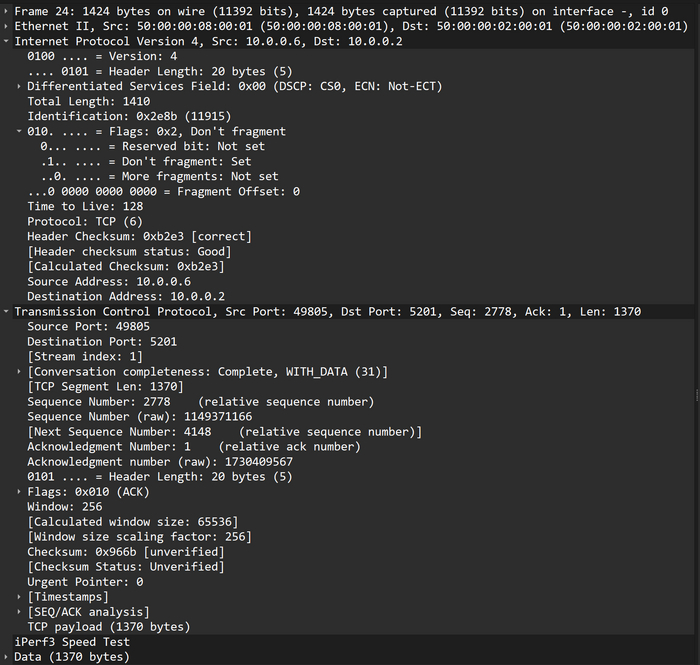
Исходный пакет размером 1410 байт
Вот первый фрагмент на выходе из CSR Gi1:
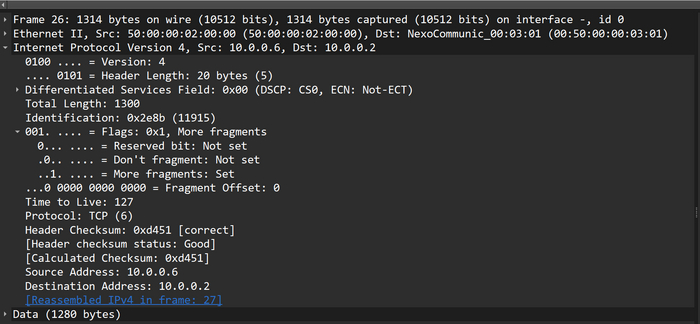
Первый фрагмент исходного пакета
А вот второй фрагмент:
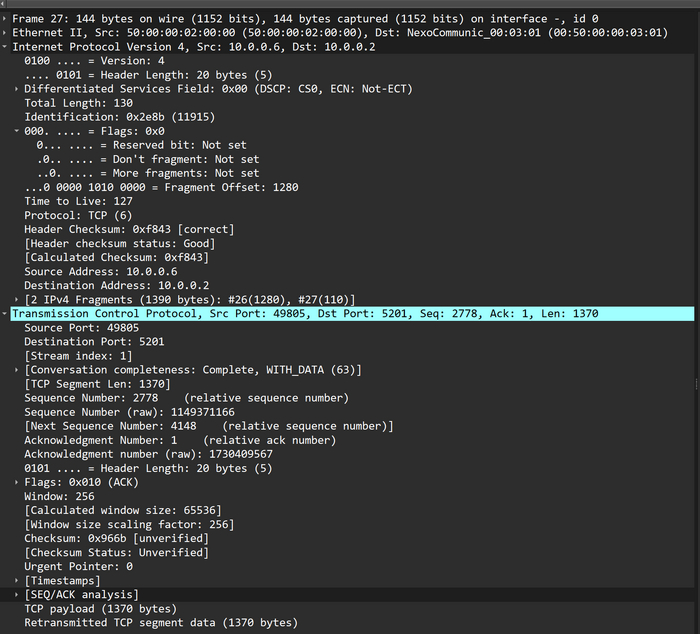
Второй фрагмент исходного IP-пакета
Мы посмотрели пример фрагментации пакетов, понятно, что делать это на роутерах не очень правильно, но иногда приходится.
В следующий раз поговорим про Path MTU Discovery, для этого нужно отвязать route-map от интерфейса Gi2, чтобы роутер перестал обнулять df-bit:
CSR#conf t
CSR(config)#int gi2
CSR(config-if)#no ip policy route-map RM_DEL-DF-BIT
IP MTU 1300 байт на линке Gi1 оставляем.
Вопросы для ваших ответов
Может ли фрагментированный IP пакет быть меньше 68 байт и почему?
Напомню топологию
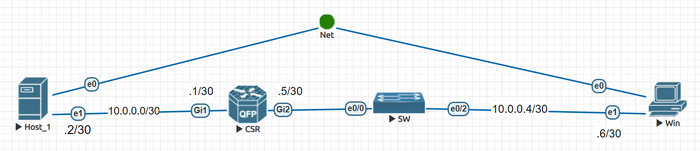
Топология сети лабы
Представим ситуации: на интерфейсе Gi2 роутера CSR настроен IP MTU 1400 байт, на всех остальных линках IP MTU 1500 байт, хост Windows генерирует в сторону Linux пакеты размером 1450 байт, что с этими пакетами будет?
Имеется линк с IP MTU 700 байт: на сколько фрагментов и какого разрмера будет разбит пакет1400 байт?
Имеется линк с IP MTU 725 байт: на сколько фрагментов и какого разрмера будет разбит пакет1430 байт?
Видео версия
Для тех, кому проще смотреть и слушать есть видео версия