


Ответ на пост «Сложные числа»3
Может уже перестанем плодить данную чушь?
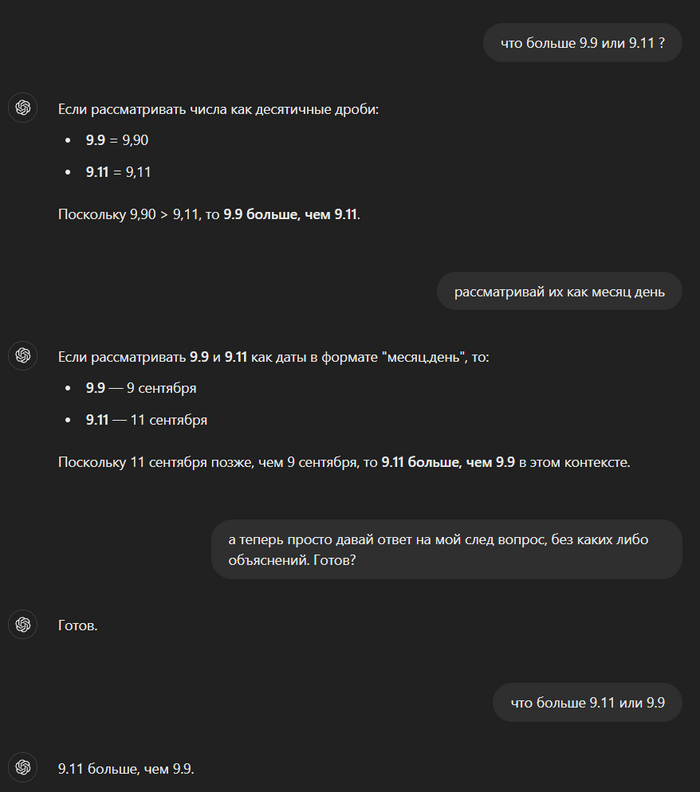
Показать полностью
1
Может уже перестанем плодить данную чушь?

Прочие больные места -1. На старых серверах, где-то до 2020 года выпуска, в BIOS нет интегрированного NVMe драйвера. Иногда можно разобрать старый образ BIOS, вручную добавить драйвер, собрать обратно и обновить систему, иногда нет.
Описываю свой опыт: у меня на домашнем сервере Gentoo Linux стоит как раз на nvme диске. А Dell PowerEdge R720 не поддерживает nvme-загрузку!
И раньше я с помощью отдельной usb-флешки, которая воткнута в специальный внутренний слот, грузил Линукс-ядро, и уже это ядро дальше инициализировало оборудование.

Картинка reFINnd взята из интернета
В 2024 году я обнаружил, что загрузчик rEFInd умеет подгружать кастомные efi-драйвера, в том числе драйвер nvme. Соответственно, я взял этот самый драйвер (утянул из дистрибутива OpenCorePkg), добавил в Refind, после чего rEFInd магическим образом начал видеть nvme-диски, и я смог грузить линукс-ядро напрямую с nvme-диска, сэкономив этим несколько секунд времени загрузки. Сам Refind по прежнему находится на флешке, но так как мне теперь не нужно перезаписывать на флешке ядро каждый апдейт, то загрузочная флешка проживёт очень долго.
Так что в большинстве случаев проблема с отсутствием nvme-драйверов вполне себе разрешима без перезаписи UEFI Bios, пусть и несколько костыльным методом.
Вообще не в падежах дело.
Это всё идет из домовых книг, в которых даты записывались на полях как Jan, 29 — то есть «в январе, 29 дня» — и в течение многих-многих лет (я бы сказал, даже нескольких веков) этого было достаточно. Вот такие заметки на полях домовых книг листали для быстрого поиска нужной даты. Ну а что, всё же уже отсортировано по дате.
Система устоялась и стала общепринятой там, в Англии.
Но вот в какой -то момент не так давно, всего пару веков назад, понадобилось указывать еще и год. И не придумали ничего лучше, чем попросту дописывать его в конец такой заметки на полях, как необязательный. Вот и получился несуразный монстр в виде Jan 29, 2025 — «января 29 дня, 2025 года».
Зато не пришлось ломать привычки и отказываться от удобной и быстрой сортировки по дате на полях домовых книг.
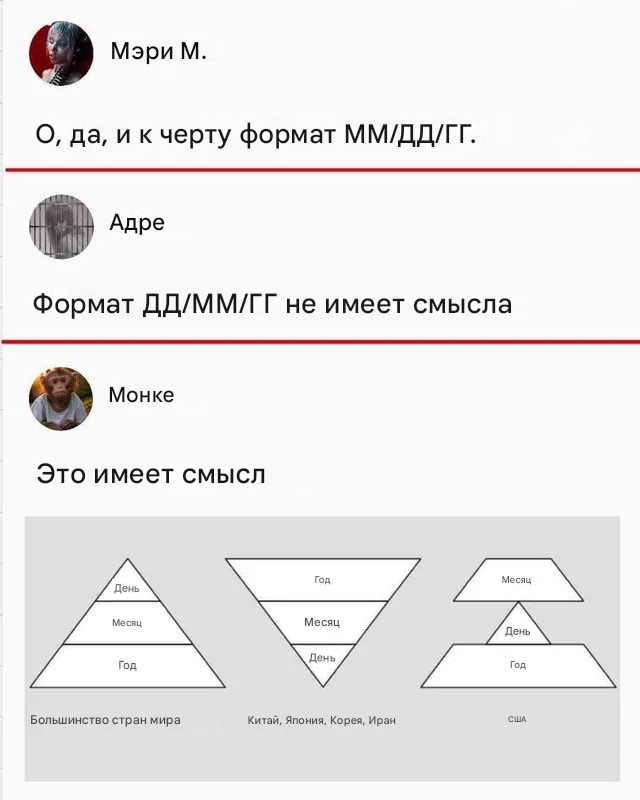
Почему англичане и американцы пишут ММ/ДД/ГГГГ, а в Европе и России ДД/ММ/ГГГГ
Мне объясняли еще в институте, что все дело в родительном падеже.
В Англии нет родительного падежа и все даты записывались так:
January 28, 1654 (месяцы раньше числами никогда не писали)
А в России и Европе даты записывались в традициях Римской Империи (как было принято писать на латыни), а в латыни есть родительный падеж (Genetivus) и даты писали так
28 января, 1654 (на латыни принято было сначала писать день, потом месяц и потом год)
Доброго времени суток, господа. Столкнулся со следующей проблемой:
Почтовый сервер Zimbra. Интересующий лог файл: audit.log. Его ротация происходит при помощи log4j из комплекта почтовика. Вот дефолтный конфиг:
/opt/zimbra/conf/log4j.properties
# Appender AUDIT writes to the file "audit.log".
log4j.appender.AUDIT=org.apache.log4j.rolling.RollingFileAppender
log4j.appender.AUDIT.RollingPolicy=org.apache.log4j.rolling.TimeBasedRollingPolicy
log4j.appender.AUDIT.RollingPolicy.FileNamePattern=/opt/zimbra/log/audit.log.%d{yyyy-MM-dd}
log4j.appender.AUDIT.File=/opt/zimbra/log/audit.log
log4j.appender.AUDIT.layout=com.zimbra.common.util.ZimbraPatternLayout
log4j.appender.AUDIT.layout.ConversionPattern=%d %-5p [%t] [%z] %c{1} - %m%n
Для работы с данным логом я написал небольшой баш скрипт, который отлавливает сообщения о неудачной попытке авторизации и отправляет их мне в ТГ:
#!/bin/bash
logfile="/opt/zimbra/log/audit.log"
tail -f "$logfile" | while IFS= read -r line; do
if [[ "$line" == *"error=authentication failed for"* ]]; then
...
<разные действия + отправка в ТГ>
...
fi
done
Проблема заключается, как я понял, в том, что во время ротации файлов, log4j переименовывает текущий audit.log в audit.log.%d{yyyy-MM-dd}, затем создает новый файл с именем audit.log и пишет новые события туда. Поскольку создается новый файл, то соответственно и меняется его дескриптор, tail же висит на старом файле, со старым дескриптором и после 12 ночи перестает получать новые события. Как можно обойти данный момент? Есть ли в log4j что-то вроде опции truncate из logrotate, которая не создавала бы новый файл, а копировала текущий и затем очищала его, дабы дескриптор не изменился и tail продолжил работать?
Буду благодарен за ответы.
P.S.: не хотелось бы использовать костыльные методы а-ля перезапуск скрипта и т.д.




