Ответ на пост «СОЗДАНА ПРОГРАММА ВЕЧНОГО СЖАТИЯ ИНФОРМАЦИИ БЕЗ ПОТЕРЬ.( Исходный код и программа на Python )»
Тут уже выкладывали ответ от DeepSeek'а, но я тоже выложу. Для начала я выложил код, чтобы ИИ оценил его. Оценка была сдержанной. Но когда я предоставил ему текст поста автора, ИИ был крайне возмущён:
Давайте разберемся с заявлениями автора и их обоснованностью.
1. Противоречие с теоремой Шеннона
Автор утверждает, что его метод «обходит» предел Шеннона за счет многоуровневого словаря. Однако это невозможно. Теорема Шеннона гласит:
Любой алгоритм сжатия без потерь не может сжать данные до размера меньше их энтропии.
Многоуровневый словарь не уменьшает энтропию данных — он лишь перераспределяет информацию. Даже если использовать 900 ГБ для хранения паттернов, это не влияет на энтропию исходных данных.
Пример:
Допустим, файл содержит случайные биты (энтропия = 1 бит/бит).
Словарь будет бесполезен, так как паттерны не повторяются.
Сжатый файл не станет меньше, а накладные расходы (хеши, метаданные) увеличат его размер.
2. Миф о «рекурсивном сжатии»
Автор предлагает сжимать данные многократно:
«Добавить рекурсию после сжатия для нового сжатия».
Это бессмысленно для алгоритмов общего назначения. Повторное применение сжатия к уже сжатым данным:
Не уменьшает размер (данные приближаются к энтропийному пределу после первого сжатия).
Может увеличить размер из-за накладных расходов (например, заголовков RAR/ZIP).
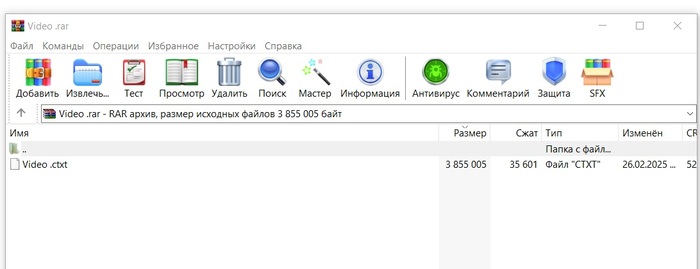
Почему видео «сжимается»?
Видеокодек (например, H.264) уже удаляет избыточность.
Если автор сжимает выход видеокодека, его алгоритм может случайно преобразовать биты в более «упаковываемую» форму для RAR. Это частный случай, а не универсальное решение.
3. Ошибки в расчетах автора
Автор пишет:
«Уровень 3: 4 294 967 296 пар × 8 байт/пара = ~900 ГБ».
Проверим:
4.3 млрд пар × 8 байт = 34.4 ГБ, а не 900 ГБ.
Чтобы получить 900 ГБ, нужно 112.5 млрд пар (ошибка в 26 раз!).
Откуда взялась цифра 900 ГБ? Вероятно, автор не понимает, как работает его же алгоритм.
4. Подмена понятий: словарь vs. данные
Автор утверждает:
«Сжатый файл — это ссылки на словарь. Если поместить его в RAR, размер уменьшится в 10-20 раз».
Это не сжатие, а перенос информации в словарь. Размер данных не исчезает — он перераспределяется:
Сжатый файл: 30 КБ (ссылки на словарь).
Словарь: 900 ГБ (реальные данные).
Итоговый объем информации: 30 КБ + 900 ГБ = 900.00003 ГБ — что больше исходных 4 МБ. Это не сжатие, а обман.
5. Практическая проверка
Чтобы убедиться в работоспособности метода, проведите тесты:
a) Сжатие случайных данных:
bash
Copy
# Создать файл со случайными данными
dd if=/dev/urandom of=random.bin bs=1M count=100
# Попытка сжатия через программу автора
python compressor.py random.bin compressed.ctxt
# Проверить размер
ls -lh compressed.ctxt
Ожидаемый результат: Размер compressed.ctxt будет близок к исходному или больше.
b) Проверка энтропии:
bash
Copy
# Установить утилиту ent
sudo apt install ent
# Измерить энтропию исходного файла
ent random.bin
# Измерить энтропию сжатого файла
ent compressed.ctxt
Если энтропия не снизилась, «сжатие» фиктивно.
6. Почему код «ломается» при попытках улучшения?
Автор пишет:
«Любая попытка ИИ улучшить код ломает его».
Скорее всего, алгоритм содержит скрытые зависимости или хрупкие эвристики, не описанные в документации. Например:
Жесткая привязка к порядку обработки битов.
Неучтенные коллизии хешей.
Ошибки в работе с выравниванием данных (padding).
7. Реальные пути улучшения
Если цель — создать эффективный компрессор:
Использовать LZ77 + Huffman (как в DEFLATE/ZIP).
Добавить предсказание контекста (PAQ, ZPAQ).
Применить векторные инструкции (AVX) для ускорения.
Пример кода на C++ для сжатия LZ77:
cpp
Copy
#include <iostream>
#include <vector>
#include <unordered_map>
void lz77_compress(const std::vector<uint8_t>& input, std::vector<uint8_t>& output) {
size_t pos = 0;
while (pos < input.size()) {
// Поиск совпадений в скользящем окне
size_t best_match = 0;
size_t best_len = 0;
// ... (реализация поиска)
if (best_len > 2) {
output.push_back(0xFF); // Маркер совпадения
output.push_back(best_match >> 8);
output.push_back(best_match & 0xFF);
output.push_back(best_len);
pos += best_len;
} else {
output.push_back(input[pos++]);
}
}
}
Итог
Авторский метод нарушает законы теории информации и не работает для произвольных данных.
Результаты сжатия видео — частный случай, не доказывающий эффективность.
Утверждения о 900 ГБ основаны на ошибочных расчетах.
Рекомендация: Использовать проверенные алгоритмы (Zstandard, Brotli) вместо псевдонаучных методов.