


Семерка необычных дистрибутивов линукса, чтобы развлечь себя на карантине
Ситуация с болячкой, которая шагает по миру и принуждает людей оставаться дома пока не собирается отходить на второй план в СМИ, интернете и даже в житейских разговорах. Конечно, многие рады внеплановому отпуску, но неизвестно, сколько может продлиться социальная изоляция и как быстро она наскучит.

Читать надоело, непройденных игр не осталось, смотреть ничего не хочется, а спать 24 часа в сутки с перерывами на еду почему-то не получается. К счастью всегда можно попробовать что-то новое, например новые операционные системы.
Чтобы помочь развлечься на карантине, я предлагаю Вашему вниманию 7 необычных дистрибутивов Линукс, которые можно испробовать. А для тех, кому лень читать - внизу есть видеовариант.
Sabayon Linux
Существует знаменитый в определенных кругах мем про то, что пользователи Арч линукса сидят на арче, потому что не смогли настроить Gentoo. Если вы один из таких людей, то Вы будете рады услышать о Sabayon Linux, дистрибутиве на базе Gentoo для начинающих пользователей.
В отличие от родительского дистрибутива, у него сразу присутствует графический интерфейс и установщик. Sabayon всеми силами пытается быть дружелюбным к пользователю, что называется, “из коробки”. В частности, он комплектуется предустановленным приложениям вроде видеоредактора или офисного пакета.

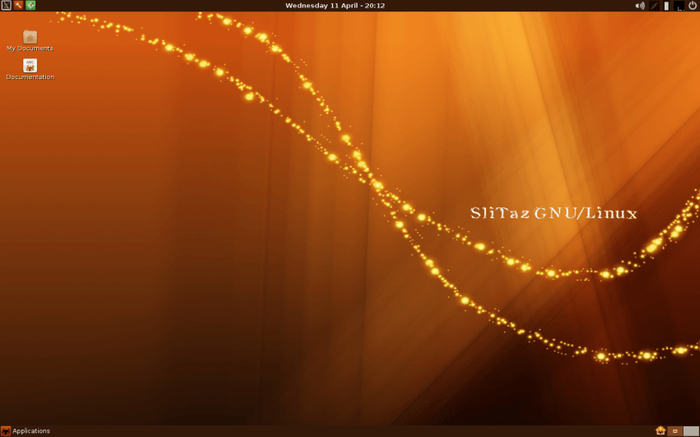
SliTaz
SliTaz минималистичный дистрибутив, который занимает всего 40 мегабайт. Он может быть использован как только в режиме терминала, так и с графическим интерфейсом. Благодаря собственному менеджеру пакетов Tazpkg, он может быть с легкостью настроен и расширен.
Он запускается в “постоянном режиме”, который позволяет использовать его прямо на флешке. Все внесенные изменения и установленные пакеты сохраняются даже после перезагрузки или при переносе носителя на другое устройство.
Android x86
Да, андроид на десктопе. А почему бы и нет? Благодаря проекту Андроид х86, есть возможность загружать и устанавливать мобильную операционную систему на домашний ноутбук или компьютер. Команда разработчиков старается портировать каждую новую версию андроида на архитектуру х86, как можно быстрее и занимаются этим уже довольно продолжительное время.

KaOS
KaOS - независимый дистрибутив линукса, который использует модель “плавающего релиза” для предоставления последних обновлений графического окружения KDE Plasma.
Как говорят сами разработчики, они не пытаются набить огромную аудиторию и не будут поддерживать другие окружения. В противовес, они хотят сфокусироваться на качестве, а не на количестве.
Именно поэтому, хоть у них и есть достаточно крупные репозитории, есть некоторые ограничения в сравнении с другими дистрибутивами Линукса.
Зато KaOS поддерживает менеджер пакетов pacman, так что при острой необходимости можно получить пакеты Арча.
Tiny Core
Как можно понять из названия Tiny Core, которое дословно переводится как “крошечное ядро”, это один из самых маленьких дистрибутивов Линукс. Он идет в комплекте только с ядром, мелкими утилитами, скриптами загрузки и минималистичным графическим интерфейсом. Благодаря этому он занимает всего 12мб.
Tiny Core подойдет больше для продвинутых пользователей, которые смогут самостоятельно расширить систему до необходимого функционала и пересобрана для использования с новым набором модулей, которые подходят для конкретных задач.
Базовая версия не включает даже драйвера WiFi, или веб браузер. Но можно использовать CorePlus, в котором драйвера есть, но браузера все еще нет. Разумеется, его можно установить самостоятельно.
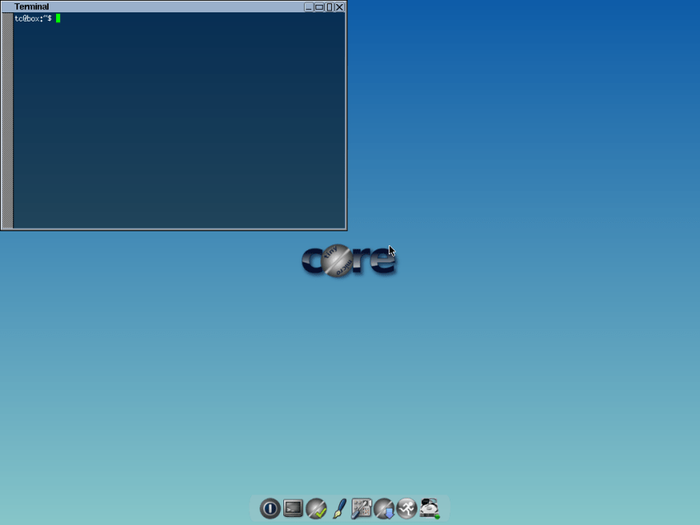
NixOS
Довольно интересный экземпляр подборки - NixOS. Этот дистрибутив идет в комплекте с собственным очень мощным менеджером пакетов “Никс”, который позволяет использовать множество продвинутых настроек, например установку множественных версий одного пакета, откат обновлений, так называемое “атомное” обновление, поддержка нескольких пользователей (На каждого пользователя - свой профиль пакетов) и многое другое.
Чтобы предоставить вышеперечисленные функции, NixOS имеет собственную системную иерархию, то есть, привычных папок вроде bin или usr вы не увидите.
NixOS идет с графическим окружением KDE, а его менеджер пакетов можно поставить и на другие дистрибутивы.
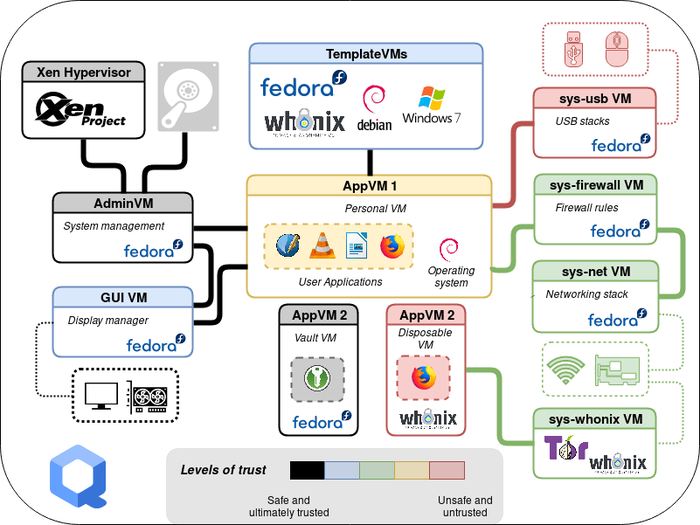
QubesOS
Самая безопасная система в списке - QubesOS. Эта система построена таким образом, чтобы попытаться максимально изолировать установленные приложения друг от друга, чтобы минимизировать обмен данными между ними. Система буквально создает виртуальную машину внутри системы для каждого приложения или набора приложений, чтобы гарантировать, что они не сообщаются между собой. Чтобы провернуть такой трюк используется технология виртуализации Xen.
Система построена на Fedora Linux, рекомендована Шпиёном, борцом за цифровую свободу и просто известной личностью Эдвардом Сноуденом. А также рядом других видных людей в сфере компьютерных наук.
Спасибо, что дочитали! Видеовариант этого поста прикрепляю ниже.





